Computational Statistics in Data Science
Здесь есть возможность читать онлайн «Computational Statistics in Data Science» — ознакомительный отрывок электронной книги совершенно бесплатно, а после прочтения отрывка купить полную версию. В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Жанр: unrecognised, на английском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.

- Название:Computational Statistics in Data Science
- Автор:
- Жанр:
- Год:неизвестен
- ISBN:нет данных
- Рейтинг книги:4 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
Computational Statistics in Data Science: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «Computational Statistics in Data Science»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
Computational Statistics in Data Science
Computational Statistics in Data Science
Wiley StatsRef: Statistics Reference Online
Computational Statistics in Data Science
Computational Statistics in Data Science — читать онлайн ознакомительный отрывок
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «Computational Statistics in Data Science», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
2.1.3 How easy is R to develop?
R is becoming easier and easier to develop packages and analyses with. This is largely due to the efforts of RStudio, bringing slick new tools and support software on a regular basis. Their software “combine robust and reproducible data analysis with tools to effectively share data products.” One package that integrates well with RStudio is devtools written by Dr Hadley Wickham, the chief scientist at RStudio. devtools provides a plethora of tools to create, test, and export R packages. devtools has grown so comprehensive that developers have split the project into several smaller packages such as testthat (for writing tests), roxygen2 (for writing R documentation), usethis (for automating package setup, data, imports, etc.), and a few others that provide convenient tools for building and testing packages.
2.1.4 What is the downside of R?
R is slow. Or at least that is the perception and sometimes the case. This is because R is not a compiled language, so methods of flow control such as for‐loops are not optimized. This shortcoming is easily circumvented by taking advantage of the vectorization offered through other built‐in functions like those from the apply family in R, but these faster techniques often go unused through lack of proficiency or because it is easier to write a for‐loop. Intrinsically slow functions can be written in C++ and run via Rcpp , but then that negates the simplicity of writing R. This is a special case where Python easily surpasses R. Python is also a scripted language, but through the use of NumPy and numba it can gain fast vectorized operations, loops, and utilize a just‐in‐time (JIT) compiler. Ergo, any performance shortcoming of Python can be taken care of through a decorator.
Packages are not written by programmers, or at least not programmers by trade or education. A great deal of libraries for R are written by researchers and analysts who needed a tool and created the tool. Because of this, there is often fragmentation in the syntax or incompatibility between packages, or generally a lack of best practices that leads to poorly performing code, or, in the most drastic setting, code that simply gives erroneous results.
2.1.5 Summary of R
R is firmly entrenched as a premier statistical software package. Its open‐source, community‐based approach has taken the statistical software scene by storm. R's interactive and scripting programming style makes it an attractive and flexible analytic tool. R does lack the speed/flexibility of other languages; yet, for a specialist in statistics, R provides a near‐complete solution. RStudio's efforts further solidify R as a key player moving forward in the modern statistical software ecosystem. We see the popularity of R continuing – however, big data's demands could force R programmers to adapt other tools in conjunction with R, if companies/developers fail to keep up with tomorrow's challenges.
2.2 Python
Created by Guido van Rossum and released in 1991, Python is a hugely popular programming language [4]. Python features readable code, an interactive workflow, and an object‐oriented design. Python's architecture affords rapid application development from prototyping to production. Additionally, many tools integrate nicely with Python, facilitating complex workflows. Python also possesses speed, as most of its high‐performance libraries are implemented in C/C 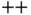 .
.
Python's core distribution lacks statistical features, prompting developers to create supplementary libraries. Below, we detail four well‐supported statistical and mathematical libraries: NumPy [5], SciPy [6], Pandas [7], and Statsmodels [8].
NumPy is a general and fundamental package for scientific computing [5]. NumPy provides functions for operations on large arrays and matrices, optimized for speed via a C implementation. The package features a dense, homogeneous array called ndarray . ndarray provides computational efficiency and flexibility. Developers consider NumPy a low‐level tool as only foundational functions are available. To enhance capabilities, other statistical libraries and packages use NumPy to provide richer features.
One widely used higher level package, SciPy , employs NumPy to enable engineering and data science [6]. SciPy contains modules addressing standard problems in scientific computing, such as mathematical integration, linear algebra, optimization, statistics, clustering, image, and signal processing.
Another higher level Python package built upon NumPy , Pandas , is designed particularly for data analysis, providing standard models and cohesive frameworks [7]. Pandas implements a data type named DataFrame – a concept similar to the data.frame object in R. DataFrame's structure features efficient methods for data sorting, splicing, merging, grouping, and indexing. Pandas implements robust input/output tools – supporting flat files, Excel files, databases, and HDF files. Additionally, Pandas provides visualization methods via Matplotlib [9].
Lastly, the package Statsmodels facilitates data exploration, estimation, and statistical testing [8]. Built at even a higher level than the other packages discussed, Statsmodels employs NumPy , SciPy , Pandas , and Matplotlib . Many statistical models exist, such as linear regression, generalized linear models, probability distributions, and time series. See http://www.statsmodels.org/stable/index.htmlfor the full feature list.
In addition to the four libraries discussed above, Python features numerous other bespoke packages for a particular task. For ML, the TensorFlow and PyTorch packages are widely used, and for Bayesian inference, Pyro and NumPyro are becoming popular (see more on these packages in Section 4). For big data computations, PySpark provides scalable tools to handle memory and computation time issues. For advanced data visualization, pyplot , seaborn , and plotnine may be worth adopting for a Python‐inclined data scientist.
Python's easy‐to‐learn syntax, speed, and versatility make it a favorite among programmers. Moreover, the packages listed above transform Python into a well‐developed vehicle for data science. We see Python's popularity only increasing in the future. Some believe that Python will eventually eliminate the need for R. However, we feel that the immediate future lies in a Python + R paradigm. Thus, R users may well consider exploring what Python offers as the languages have complementary features.
2.3 SAS®
SAS was born during the late 1960s, within the Department of Experimental Statistics at North Carolina State University. As the software developed, the SAS Institute was formed in 1976. Since its infancy, SAS has evolved into an integrated system for data analysis and exploration. The SAS system has been used in numerous business areas and academic institutions worldwide.
SAS provides packages to support various data analytic tasks. The SAS/STAT component contains capabilities one normally associates with data analysis. SAS/STAT supports analysis of variance (ANOVA), regression, categorical data analysis, multivariate analysis, survival analysis, psychometric analysis, cluster analysis, and nonparametric analysis. The SAS/INSIGHT package implements visualization strategies. Visualizations can be linked across multiple windows to uncover trends, spot outliers, and readily discern subtle patterns. Finally, SAS provides the user with a matrix‐programming language via the SAS/IML system. The matrix‐based language allows custom statistical algorithm development.
Читать дальшеИнтервал:
Закладка:
Похожие книги на «Computational Statistics in Data Science»
Представляем Вашему вниманию похожие книги на «Computational Statistics in Data Science» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.
![Роман Зыков - Роман с Data Science. Как монетизировать большие данные [litres]](/books/438007/roman-zykov-roman-s-data-science-kak-monetizirova-thumb.webp)











Обсуждение, отзывы о книге «Computational Statistics in Data Science» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.