Stefan Schmerler - Softwaretest in der Praxis
Здесь есть возможность читать онлайн «Stefan Schmerler - Softwaretest in der Praxis» — ознакомительный отрывок электронной книги совершенно бесплатно, а после прочтения отрывка купить полную версию. В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Жанр: unrecognised, на немецком языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.

- Название:Softwaretest in der Praxis
- Автор:
- Жанр:
- Год:неизвестен
- ISBN:нет данных
- Рейтинг книги:4 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
Softwaretest in der Praxis: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «Softwaretest in der Praxis»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
Konkret adressiert das Buch folgende Fragestellungen: Welche Testtechnologie soll eingesetzt werden für mein spezifisches Problem?
Wie lange und mit welchem Aufwand sollte ich testen, um guten Gewissens (was auch immer das beim Testen heißen mag) die Testphase abbrechen zu können? Wie hoch ist das dann noch verbleibende Risiko, wie fehleranfällig ist mein System dann noch? Gibt es eine Metrik für Reifegrad und Qualität von Software, die einfach und schnell anzuwenden ist?
Für die häufigsten Testprobleme werden Schritt-für-Schritt-Anleitungen hinsichtlich Testfallermittlung vorgeschlagen, um mit minimalem Aufwand die größtmögliche Absicherungstiefe zu erzielen. Der Leitfaden kann unmittelbar eingesetzt werden in fast jedem Softwareentwicklungsprojekt. Neben dem klassischen Softwaretest (dynamische und statische Testverfahren, Test von Echtzeitsystemen, modellbasierter Test u.a.), werden wichtige Aspekte der Absicherung eingebetteter Software am Beispiel der Automobilelektronik detailliert erläutert, z. B. Hardware-, Software-, Model- und Vehicle-in-the-Loop-Technologie, virtuelle Integration bis hin zum Test von Fahrerassistenzsystemen und der Software für Autonomes Fahren.
Softwaretest in der Praxis — читать онлайн ознакомительный отрывок
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «Softwaretest in der Praxis», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
Einen Code »wasserdicht« zu
machen ist sehr viel Arbeit!
Was zeigt dies alles? Ausgangspunkt war eine Zeile Programmcode. Der Programmcode enthält jetzt zusätzliche 16 Zeilen und ist immer noch fehlerhaft. Die Kernfunktionalität macht den geringsten Teil im Code aus. Einen fehlerfreien Code zu schreiben, ist sehr anspruchsvoll und für komplexe Programme praktisch unmöglich. Kein Programmierer kann alle Nutzungsszenarien antizipieren, aber fehlerfreie Software erfordert dies. Fehler sind Bestandteil jeder Software. Dies ist eine bittere Erkenntnis.
Die Frage ist nicht, ob Software fehlerfrei ist – sie ist es nicht – sondern, ob und wie gut man mit den Fehlern leben kann und ob diese tolerierbar sind.
einige Mythen über Software
Von Software wird allgemein gesagt, sie sei einfach zu erstellen und einfacher zu ändern als andere Gewerke. Man schließt von der physikalischen Welt auf gleiche Umstände bei Software – dies ist natürlich ein Trugschluss. Hier zwei trügerischen Annahmen:
▶»Software ist einfach zu erstellen, da jedes Schulkind, das Basic kennt, so etwas kann.«
▶»Software ist einfacher zu ändern als andere Gewerke, man denke nur an Gussbeton oder Stahlröhren!«
Die Erwartung, komplexe Software verhalte sich nach physikalischen Gesetzmäßigkeiten, ist bei Nichtfachleuten zwar weit verbreitet, aber ganz offensichtlich falsch. Insbesondere die Aufwände für den Test und die Mechanismen der Komplexitätssteigerung folgen besonderen Gesetzmäßigkeiten.
Aufwand und Komplexität
Wie aufwendig ist es also, einen Programmcode zu testen und wovon hängt dieser Aufwand ab? Einfache Antwort: Von der Komplexität des zu testenden Programms!
Betrachten wir den Testaufwand am Beispiel des Kontrollflussgraphen eines Programms in Abb. 1-1. Die Knoten des Kontrollflussgraphen repräsentieren unverzweigte Codesequenzen, die dargestellten Verzweigungen können z. B. durch if-then-else-Konstrukte oder Schleifen verursacht werden.
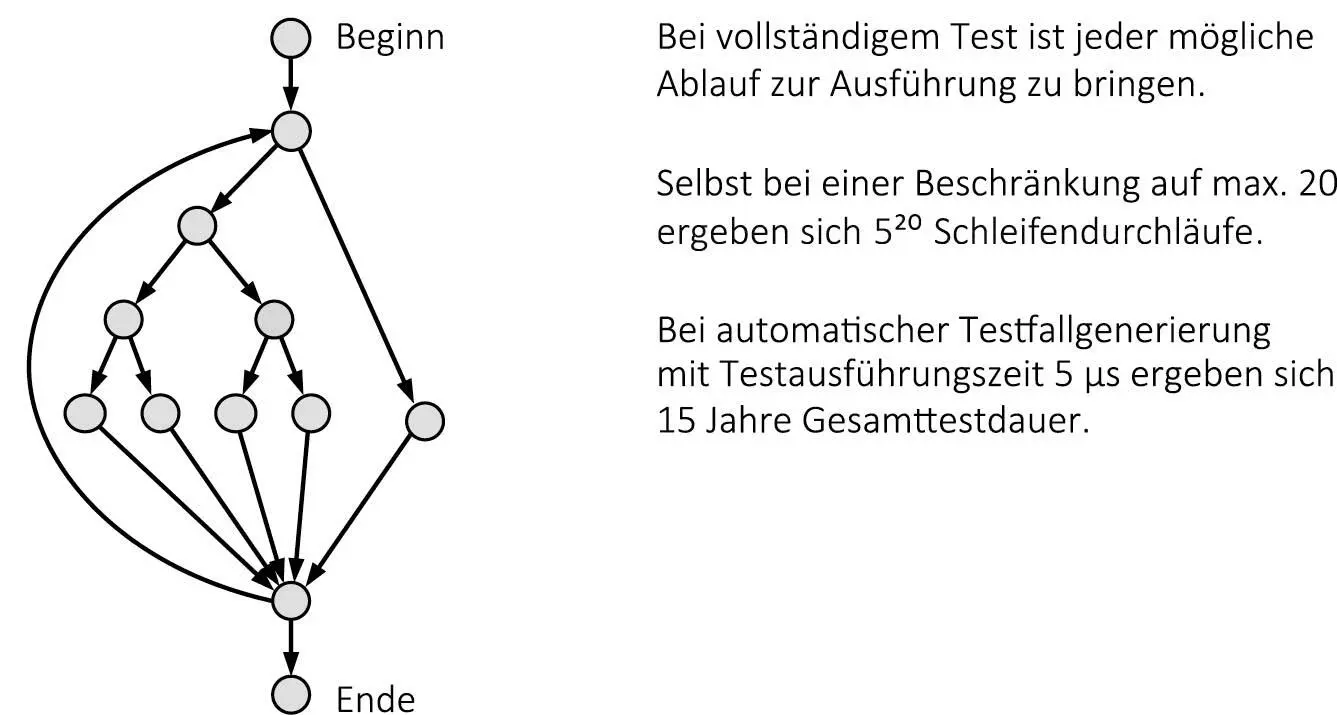
Abb. 1-1: Kontrollflussgraph eines Beispielprogramms
Der Testaufwand korreliert mit
der Komplexität von Software.
Ganz offensichtlich korreliert der Testaufwand mit der Komplexität der getesteten Software. Je komplexer die inneren (z. B. Verzweigungs-)Strukturen sind, desto aufwendiger ist der Test, um einen vergleichbaren Reifegrad zu erzielen. Um also Aussagen über den zu erwartenden Testaufwand treffen zu können, ist es unbedingt erforderlich, konkrete Informationen über die Komplexität der zu testenden Software zu besitzen. Eine Metrik für die numerische Messung von Softwarekomplexität wird später noch vorgestellt.
Grundsätzlich kann man sagen, dass Software nicht komplexer sein sollte, als es für die Lösung der zugrunde liegenden Aufgabe unbedingt erforderlich ist. Ein einfach strukturierter, leicht verständlicher Code hat nachweislich eine geringere Fehlerneigung als verflochtene, tiefverschachtelte Programme mit überladenen Anweisungen und Bedingungen.
statistische Daten
zu Softwarefehlern
Viele statistische Untersuchungen haben sich bereits mit der Fehlerhäufigkeit in der Softwareentwicklung auseinandergesetzt. Der Coverity Scan Report z. B. untersucht regelmäßig kommerzielle und Open-Source-Projekte und ermittelt Fehlerstatistiken. Für den Report 2014 wurden ca. 10 Mrd. Codezeilen mit folgendem Ergebnis analysiert:
▶Open-Source-Projekte weisen eine Gesamtfehlerdichte von 0,61 Fehlern je 1000 Codezeilen auf, für kommerzielle Projekte wurde ein Wert von 0,76 Fehlern je 1000 Codezeilen ermittelt.
▶Ein Projekt von 500.000 Codezeilen beinhaltet also statistisch 350 Fehler.
▶Die Zeit, um einen Fehler manuell zu finden und zu beheben, wird mit durchschnittlich 8–10 Stunden abgeschätzt.
1.2.2 Warum also ist Testen so schwierig?
keine Analogie zur Mechanik
in Qualität und Komplexität
Einer der Gründe, warum ein Softwaretest im Vergleich zur Prüfung mechanischer Komponenten als vergleichsweise schwierig erscheint, ist die Tatsache, dass die meisten Analogien aus dieser »bekannten« Welt versagen. Im Vergleich zu physikalischen Systemen gibt es z. B. kein theoretisches Modell, das es erlaubt, die Zuverlässigkeit eines Softwaresystems von der Zuverlässigkeit seiner Komponenten abzuleiten. Offensichtliche, plausible Qualitätskriterien wie für mechanische Bauteile gibt es für Software nicht. Zu viele Kriterien existieren, die man als Grundlage für diese Aussage heranziehen könnte.
Welchen Aussagewert besitzen die folgenden häufig (aber völlig zu Unrecht) zitierten Metriken in Bezug auf Softwarequalität?
▶Fehler pro Lines of Code sind denkbar ungeeignet. Die Fehlerhäufigkeit im Code ist eine Eigenschaft der Software und sagt nichts über deren Ausfallwahrscheinlichkeit aus noch gibt sie Aufschluss über die Kritikalität der Fehler. Diese ist von der Benutzung der Software abhängig.
▶Fehleraufdeckungsrate pro Zeit ist ebenfalls untauglich: Dies ist noch nicht einmal eine Messung von Softwareeigenschaften. Es ist eine Messung der Ausdauer, Vorstellungskraft und Intuition der Testergruppe. Der Test wird beendet, wenn den Testern die Ideen ausgehen.
Ohne Qualitätsmetriken auch
kein klares Testende-Kriterium!
Schwierig ist letztlich das Fehlen klarer Testende-Kriterien u. a. in Ermangelung adäquater Qualitätsmetriken. In der Praxis wird dem Testbestreben der Entwickler oft aufgrund wirtschaftlicher Randbedingungen ein Ende gesetzt. Die Terminsituation bei der Produktentwicklung erlaubt es zudem oftmals nicht, Deadlines zu verschieben, sodass auch dies den Testprozess (den letzten Prozessschritt der Entwicklung) vorzeitig beenden kann. Es gilt also immer, einen wirtschaftlichen Kompromiss zwischen Qualität und Kosten zu erzielen – oder, um mit Harry M. Sneed zu sprechen:
»Zuviel Qualität ist Luxus, zu wenig Qualität unverantwortlich«
Spannungsdreieck
Qualität-Kosten-Zeit
Die Grafik Abb. 1-2 zeigt das Spannungsdreieck Qualität-Zeit-Kosten, das diesen Sachverhalt recht gut veranschaulicht. Je früher der Testabbruch, desto höher die Folgekosten z. B. aufgrund von Garantieforderungen und Kulanz. Fehler, die im Produkt an den Kunden ausgeliefert werden, sind sehr teuer! Andererseits sind die Aufwände für das Testing bei frühem Testabbruch natürlich geringer. Je nach der Wirkung des Fehlers wird er vom Kunden nicht toleriert oder er ist sicherheitskritisch und kann nicht in regulären, ohnehin stattfindenden Wartungsmaßnahmen bereinigt werden.
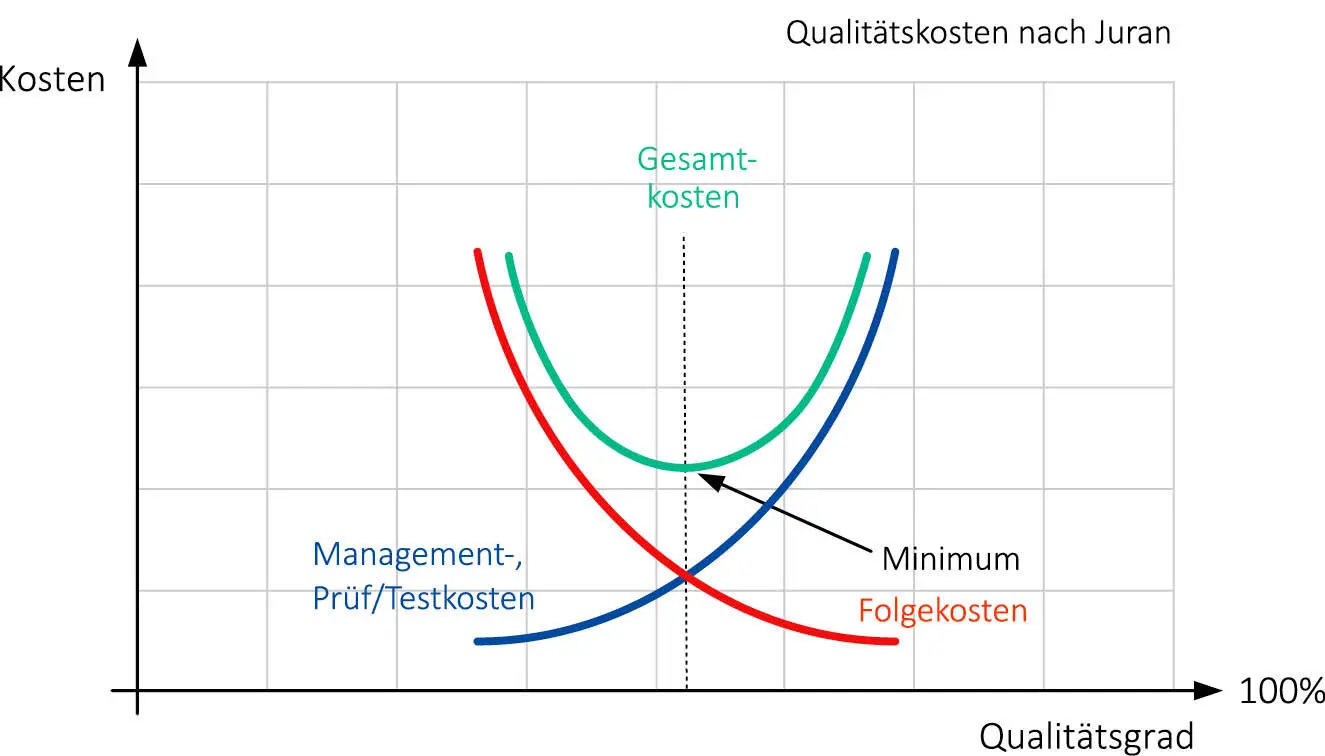
Abb. 1-2: Das Spannungsdreieck Qualität-Kosten-Zeit
Steigert man den Qualitätsgrad über das wirtschaftlich sinnvolle Maß hinaus, steigen natürlich die Testkosten, während die Garantie-/Kulanzkosten sinken. Da sich die Gesamtkosten aus Aufwänden für die Absicherung und für Garantie/Kulanz zusammensetzen, ergibt sich ein Sweet Spot (Abb. 1-2), das Minimum der Kostenparabel. Diesen Sweet Spot gilt es aus betriebswirtschaftlicher Sicht anzufahren.
Abhängigkeiten von Testzeit, Test-
kosten, Testqualität und Testumfang
Harry Sneed hat die Abhängigkeit von Zeit, Kosten, Qualität und Umfang beim Softwaretest bereits 1987 im sog. »Teufelsquadrat des Tests« auf anschauliche Weise grafisch dargestellt (Abb. 1-3). Seine sehr realistische Grundannahme war, dass in Software-Entwicklungsprojekten sowohl die zur Verfügung stehende Zeit als auch das Budget begrenzt sind. Bei einem im Projektverlauf z. B. durch Spezifikationsänderung wachsenden Testumfang bedeutet dies zwangsläufig eine sinkende Testqualität und damit einhergehend in aller Regel auch eine schlechtere Produktqualität. Eine höhere Testqualität kann bei gleichem Testumfang nur mit höheren Testkosten und einer längeren Testzeit erreicht werden. Diese Abhängigkeiten ergeben sich durch Ziehen einer der Ecken des inneren Quadrats in Abb. 1-3. Diese Ecken muss man sich dabei als bewegliche Punkte auf den Diagonalachsen des äußeren Quadrats vorstellen.
Читать дальшеИнтервал:
Закладка:
Похожие книги на «Softwaretest in der Praxis»
Представляем Вашему вниманию похожие книги на «Softwaretest in der Praxis» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.












Обсуждение, отзывы о книге «Softwaretest in der Praxis» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.