Pedro Domingos - The Master Algorithm - How the Quest for the Ultimate Learning Machine Will Remake Our World
Здесь есть возможность читать онлайн «Pedro Domingos - The Master Algorithm - How the Quest for the Ultimate Learning Machine Will Remake Our World» весь текст электронной книги совершенно бесплатно (целиком полную версию без сокращений). В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Жанр: Прочая околокомпьтерная литература, на английском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.

- Название:The Master Algorithm: How the Quest for the Ultimate Learning Machine Will Remake Our World
- Автор:
- Жанр:
- Год:неизвестен
- ISBN:нет данных
- Рейтинг книги:4 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
The Master Algorithm: How the Quest for the Ultimate Learning Machine Will Remake Our World: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «The Master Algorithm: How the Quest for the Ultimate Learning Machine Will Remake Our World»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
Machine learning is the automation of discovery-the scientific method on steroids-that enables intelligent robots and computers to program themselves. No field of science today is more important yet more shrouded in mystery. Pedro Domingos, one of the field’s leading lights, lifts the veil for the first time to give us a peek inside the learning machines that power Google, Amazon, and your smartphone. He charts a course through machine learning’s five major schools of thought, showing how they turn ideas from neuroscience, evolution, psychology, physics, and statistics into algorithms ready to serve you. Step by step, he assembles a blueprint for the future universal learner-the Master Algorithm-and discusses what it means for you, and for the future of business, science, and society.
If data-ism is today’s rising philosophy, this book will be its bible. The quest for universal learning is one of the most significant, fascinating, and revolutionary intellectual developments of all time. A groundbreaking book, The Master Algorithm is the essential guide for anyone and everyone wanting to understand not just how the revolution will happen, but how to be at its forefront.
The Master Algorithm: How the Quest for the Ultimate Learning Machine Will Remake Our World — читать онлайн бесплатно полную книгу (весь текст) целиком
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «The Master Algorithm: How the Quest for the Ultimate Learning Machine Will Remake Our World», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
Naïve Bayes is a good conceptual model of a learner to use when reading the press: it captures the pairwise correlation between each input and the output, which is often all that’s needed to understand references to learning algorithms in news stories. But machine learning is not just pairwise correlations, of course, any more than the brain is just one neuron. The real action begins when we look for more complex patterns.
From Eugene Onegin to Siri
In 1913, on the eve of World War I, the Russian mathematician Andrei Markov published a paper applying probability to, of all things, poetry. In it, he modeled a classic of Russian literature, Pushkin’s Eugene Onegin, using what we now call a Markov chain. Rather than assume that each letter was generated at random independently of the rest, he introduced a bare minimum of sequential structure: he let the probability of each letter depend on the letter immediately preceding it. He showed that, for example, vowels and consonants tend to alternate, so if you see a consonant, the next letter (ignoring punctuation and white space) is much more likely to be a vowel than it would be if letters were independent. This may not seem like much, but in the days before computers, it required spending hours manually counting characters, and Markov’s idea was quite new. If Vowel i is a Boolean variable that’s true if the i th letter of Eugene Onegin is a vowel and false if it’s a consonant, we can represent Markov’s model with a chain-like graph like this, with an arrow between two nodes indicating a direct dependency between the corresponding variables:

Markov assumed (wrongly but usefully) that the probabilities are the same at every position in the text. Thus we need to estimate only three probabilities: P(Vowel 1= True) , P(Vowel i+1= True | Vowel i= True) , and P(Vowel i+ 1 = True | Vowel i= False) . (Since probabilities sum to one, from these we can immediately obtain P(Vowel 1= False) , etc.) As with Naïve Bayes, we can have as many variables as we want without the number of probabilities we need to estimate going through the roof, but now the variables actually depend on each other.
If we measure not just the probability of vowels versus consonants, but the probability of each letter in the alphabet following each other, we can have fun generating new texts with the same statistics as Onegin : choose the first letter, then choose the second based on the first, and so on. The result is complete gibberish, of course, but if we let each letter depend on several previous letters instead of just one, it starts to sound more like the ramblings of a drunkard, locally coherent even if globally meaningless. Still not enough to pass the Turing test, but models like this are a key component of machine-translation systems, like Google Translate, which lets you see the whole web in English (or almost), regardless of the language the pages were originally written in.
PageRank, the algorithm that gave rise to Google, is itself a Markov chain. Larry Page’s idea was that web pages with many incoming links are probably more important than pages with few, and links from important pages should themselves count for more. This sets up an infinite regress, but we can handle it with a Markov chain. Imagine a web surfer going from page to page by randomly following links: the states of this Markov chain are web pages instead of characters, making it a vastly larger problem, but the math is the same. A page’s score is then the fraction of the time the surfer spends on it, or equivalently, his probability of landing on the page after wandering around for a long time.
Markov chains turn up everywhere and are one of the most intensively studied topics in mathematics, but they’re still a very limited kind of probabilistic model. We can go one step further with a model like this:
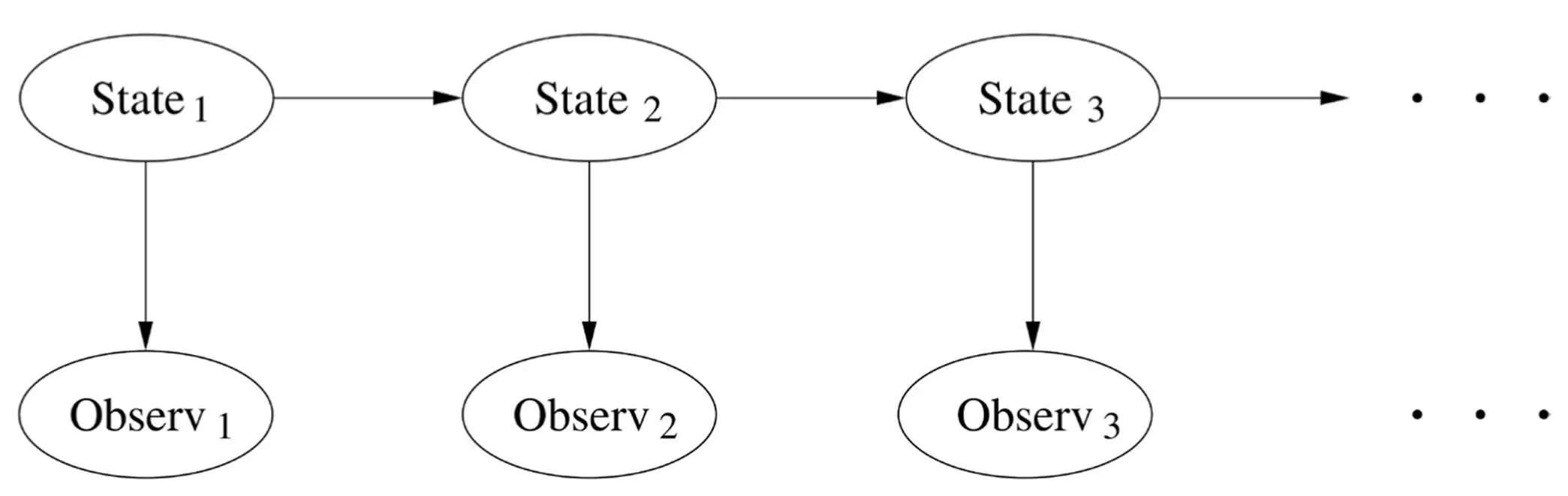
The states form a Markov chain, as before, but we don’t get to see them; we have to infer them from the observations. This is called a hidden Markov model, or HMM for short. (Slightly misleading, because it’s the states that are hidden, not the model.) HMMs are at the heart of speech-recognition systems like Siri. In speech recognition, the hidden states are written words, the observations are the sounds spoken to Siri, and the goal is to infer the words from the sounds. The model has two components: the probability of the next word given the current one, as in a Markov chain, and the probability of hearing various sounds given the word being pronounced. (How exactly to do the inference is a fascinating problem that we’ll turn to after the next section.)
Siri aside, you use an HMM every time you talk on your cell phone. That’s because your words get sent over the air as a stream of bits, and the bits get corrupted in transit. The HMM then figures out the intended bits (hidden state) from the ones received (observations), which it should be able to do as long as not too many bits got mangled.
HMMs are also a favorite tool of computational biologists. A protein is a sequence of amino acids, and DNA is a sequence of bases. If we want to predict, for example, how a protein will fold into a 3-D shape, we can treat the amino acids as the observations and the type of fold at each point as the hidden state. Similarly, we can use an HMM to identify the sites in DNA where gene transcription is initiated and many other properties.
If the states and observations are continuous variables instead of discrete ones, the HMM becomes what’s known as a Kalman filter. Economists use Kalman filters to remove noise from time series of quantities like GDP, inflation, and unemployment. The “true” GDP values are the hidden states; at each time step, the true value should be similar to the observed one, but also to the previous true value, since the economy seldom makes abrupt jumps. The Kalman filter trades off these two, yielding a smoother curve that still accords with the observations. When a missile cruises to its target, it’s a Kalman filter that keeps it on track. Without it, there would have been no man on the moon.
Everything is connected, but not directly
HMMs are good for modeling sequences of all kinds, but they’re still a far cry from the flexibility of the symbolists’ If … then … rules, where anything can appear as an antecedent, and a rule’s consequent can in turn be an antecedent in any downstream rule. If we allow such an arbitrary structure in practice, however, the number of probabilities we need to learn blows up. For a long time no one knew how to square this circle, and researchers resorted to ad-hoc schemes, like attaching confidence estimates to rules and somehow combining them. If A implies B with confidence 0.8 and B implies C with confidence 0.7, then perhaps A implies C with confidence 0.8 × 0.7.
The problem with these schemes is that they can go badly awry. From the two perfectly reasonable rules If the sprinkler is on, then the grass is wet and If the grass is wet, then it rained , I can infer the nonsensical rule If the sprinkler is on, then it rained . A more insidious problem is that with confidence-rated rules we’re prone to double-counting evidence. Suppose you read in the New York Times that aliens have landed. Maybe it’s a prank, even though it’s not April 1. But now you see the same headline in the Wall Street Journal , USA Today, and the Washington Post . You start to panic, like the listeners to Orson Welles’s infamous War of the Worlds radio broadcast who didn’t realize it was a dramatization. If, however, you check the fine print and notice that all four newspapers got the story from the Associated Press, you go back to suspecting it’s a prank, this time by an AP reporter. Rule systems have no way of dealing with this, and neither does Naïve Bayes. If it uses features like Reported in the New York Times as predictors that a news story is true, all it can do is add Reported by AP, which only makes things worse.
Читать дальшеИнтервал:
Закладка:
Похожие книги на «The Master Algorithm: How the Quest for the Ultimate Learning Machine Will Remake Our World»
Представляем Вашему вниманию похожие книги на «The Master Algorithm: How the Quest for the Ultimate Learning Machine Will Remake Our World» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.












Обсуждение, отзывы о книге «The Master Algorithm: How the Quest for the Ultimate Learning Machine Will Remake Our World» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.