Эндрю Уэзеролл - Компьютерные сети. 5-е издание
Здесь есть возможность читать онлайн «Эндрю Уэзеролл - Компьютерные сети. 5-е издание» — ознакомительный отрывок электронной книги совершенно бесплатно, а после прочтения отрывка купить полную версию. В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Год выпуска: 2011, ISBN: 2011, Издательство: Питер, Жанр: Старинная литература, на русском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.
- Название:Компьютерные сети. 5-е издание
- Автор:
- Издательство:Питер
- Жанр:
- Год:2011
- ISBN:9785446100682
- Рейтинг книги:5 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
Компьютерные сети. 5-е издание: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «Компьютерные сети. 5-е издание»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
Компьютерные сети. 5-е издание — читать онлайн ознакомительный отрывок
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «Компьютерные сети. 5-е издание», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
Проблема данной схемы заключается в том, что если к блоку добавлять всего один бит четности, то гарантированно распознаваться будет только одна однобитная ошибка в блоке. В случае возникновения последовательности ошибок вероятность обнаружения ошибки будет всего лишь 0,5, что абсолютно неприемлемо. Этот недостаток может быть исправлен, если рассматривать каждый посылаемый блок как прямоугольную матрицу n бит шириной и k бит высотой (принцип ее построения был описан выше). Если вычислить и отправить один бит четности для каждой строки, то гарантированно обнаружить можно будет до k однобитных ошибок, при условии, что в каждой строке будет не большое одной ошибки.
Однако можно сделать кое-что еще, чтобы повысить уровень защиты от последовательностей ошибок — биты четности можно вычислять в порядке, отличном от того, в котором данные отправляются. Этот способ называется чередованием( interleaving). В нашем примере мы будет вычислять бит четности для каждого из n столбцов, но биты данных отправляться будут в виде k строк, в обычном порядке: сверху вниз и слева направо. В последней строке отправим n бит четности. На рис. 3.8 порядок пересылки показан для n = 7 и k = 7.
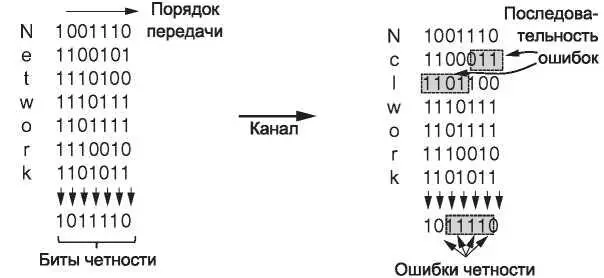
Рис. 3.8.Чередование битов четности для обнаружения последовательностей ошибок
Чередование представляет собой общую технику преобразования кода, способного обнаруживать (или исправлять) изолированные ошибки, в код, обнаруживающий (или исправляющий) последовательности ошибок. На рис. 3.8, там, где присутствует последовательность ошибок длиной n = 7, мы видим, что ошибочные биты находятся в разных столбцах (последовательность ошибок не означает, что все биты в ней неправильные; это всего лишь подразумевает, что, по меньшей мере, первый и последний биты сбойные. На рис. 3.8 из семи сбойных бит на самом деле изменено значение только четырех). В каждом из n столбцов повреждено будет не больше одного бита, поэтому биты четности этих столбцов помогут выявить ошибку. В данном методе n бит четности в блоках из kn битов данных применяются для обнаружения одной последовательности ошибок длиной n бит или меньше.
Последовательность ошибок длиной n + 1 не будет обнаружена, если будут инвертированы первый и последний биты, а все остальные биты останутся неизменными. Если в блоке при передаче возникнет длинная последовательность ошибок или несколько коротких, вероятность того, что четность любого из n столбцов будет верной (или неверной), равна 0,5, поэтому вероятность необнаружения ошибки будет равна 2 -n.
Второй тип кода с обнаружением ошибок, код с использованием контрольной суммы, весьма напоминает группу кодов, применяющих биты четности. Под «контрольной суммой» часто подразумевают любую группу контрольных бит, связанных с сообщением, независимо от способа их вычисления. Группа бит четности — также один из примеров контрольной суммы. Однако существуют и другие, более надежные контрольные суммы, основанные на текущей сумме бит данных в сообщении. Контрольная сумма обычно помещается в конец сообщения, в качестве дополнения функции суммирования. Таким образом, ошибки можно обнаружить путем суммирования всего полученного кодового слова: бит данных и контрольной суммы. Если результат равен нулю, значит, ошибок нет.
Один из примеров контрольной суммы — это 16-битная контрольная сумма, которая используется во всех пакетах протокола IP при пересылке данных в Интернете (Braden и др., 1988). Она представляет собой сумму бит сообщения, поделенного на 16-битные слова. Так как данный метод работает со словами, а не с битами (как при использовании битов четности), то ошибки, при которых четность не меняется, все же изменяют значение суммы, а значит, могут быть обнаружены. Например, если бит младшего разряда в двух разных словах меняется с 0 на 1, то проверка четности этих битов не выявит ошибку. Однако при добавлении к 16-битной контрольной сумме две единицы дадут другой результат, и ошибка станет очевидной.
Контрольная сумма, применяемая в Интернете, вычисляется с помощью обратного кода или арифметики с дополнением до единицы, а не как сумма по модулю 2 16. В арифметике обратного кода отрицательное число представляет собой поразрядное дополнение своего положительного эквивалента. Большинство современных компьютеров работают на арифметике с дополнением до двух, в которой отрицательное число является дополнением до единицы плюс один. На компьютере с арифметикой с дополнением до двух сумма с дополнением до единицы эквивалентна сумме по модулю 2 16, причем любое переполнение старших бит добавляется обратно к младшим битам. Такой алгоритм обеспечивает единообразный охват данных битами контроль
Читать дальшеИнтервал:
Закладка:
Похожие книги на «Компьютерные сети. 5-е издание»
Представляем Вашему вниманию похожие книги на «Компьютерные сети. 5-е издание» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.










Обсуждение, отзывы о книге «Компьютерные сети. 5-е издание» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.