SS
Здесь есть возможность читать онлайн «SS» весь текст электронной книги совершенно бесплатно (целиком полную версию без сокращений). В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Жанр: Справочники, на английском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.

- Название:SS
- Автор:
- Жанр:
- Год:неизвестен
- ISBN:нет данных
- Рейтинг книги:5 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
SS: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «SS»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
SS — читать онлайн бесплатно полную книгу (весь текст) целиком
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «SS», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
The mean time between failures (MTBF) of a service asset is a measure of the reliability of that asset. To increase the reliability of service assets consider the following approaches:
Use service assets with high MTBF
Maintain redundant assets
Operate the assets within design parameters
Secure the assets.
It is possible to achieve higher reliability from using assets of superior quality that fail less often.
7.5.3.2 People and processes
All assets can fail to perform at the required level. Asset s engineered and maintained for higher performance tend to have higher MTBF under the same operating conditions. This is more intuitive in the case of engineering artefacts such as hardware and software assets. It is harder to define or measure the reliability of people and process assets even where they clearly contribute to the failure of a service. The unavailability of a service staff member may cause the service to be unavailable. Procedural faults or unhandled exceptions in processes can lead to unavailability of services. The concept of MTBF applies to people and processes even if the actual metric s may be difficult or meaningless. The idea is the same. Higher MTBF means higher reliability.
This coupling between people and process assets helps improve the overall reliability of the system with improvements in one affecting the other. To reduce the stress on people assets the following motivation (M) and hygiene (H) tactics are useful:
Ensure staff have adequate knowledge and experience (M)
Train, educate, and supervise staff (M)
Reward staff for performing correctly, consistently, and ethically (M)
Develop a culture that promotes quality , efficiency , and ownership of output (M)
Improve the work environment including workplace design , productivity tools, information design, and supporting knowledge system s (H)
Automate tasks with monotony, complexity or low tolerance for variation (H)
Allocate adequate resource s to balance workload and to reduce stress (H)
Design organization to improve specialization and coordination of work (H).
To reduce the stress on process assets the following tactics are useful:
Put processes under the ownership and control of capable groups and individuals
Ensure the processes are fed with necessary knowledge and information
Reduce the in-process time to reduce average workload at any given moment
Reduce the amount of rework to be fed back into processes
Automate tasks where appropriate to reduce variation induced by people asset s
Secure the processes from unauthorized use, intrusion, and sabotage.
7.5.4 Maintainability
Service s need to be recovered as quickly as possible when they become unavailable to user s. Mean Time to Restore Service (MTRS) for a service, system or component is the time taken on average to restore its full functionality. This includes not only any physical repair or replacement, but also all the other factors that contribute towards full functionality. It is possible to estimate the MTRS of a service only when there is sufficient data available about the supporting configuration of service asset s. MTRS is a measure that depends on several factors including the following:
Configuration of service assets
Mean time to repair (MTTR) of individual components
Competency of support staff
Resource s available including information
Policies, procedure s, and guideline s
Redundancy .
Adjustments to the above factors in isolation or combination increase maintainability . Analysis of the way MTRS responds to each factor is useful for improving the design of services and performance in operation . Reducing any of the following factors can reduce MTRS (Figure 7.19):
Time to record
Time to respond
Time to resolve
Time to physically repair or replace
Time to recover.
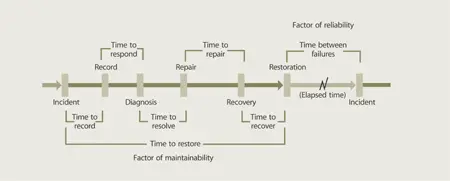
Figure 7.19 Improvement opportunities within incident lifecycle
It is normal to measure time strictly in real terms of seconds, minutes, hours and days. The periodicity of business activity varies between customers and contract s. In situations where the rate of loss to the business is linear with time, it is useful to measure the time factors indirectly in terms such as cycles, miles, transaction s and trades to sense the true impact on business.
Toolbox Tip
Methods and principles of Design of Experiments (DOE), Six Sigma and system s dynamics modelling methods are useful in developing decision model s for maintainability and reliability .
7.5.5 Redundancy
Redundancy is a means of increasing reliability and maintainability of systems. High- availability systems typically have some level of redundancy built in. There are four primary types of redundancy useful selectively or in combination: active, passive, diverse and heterogeneous (Figure 7.20).
7.5.5.1 Active redundancy
Productive capacity of redundant assets is in service all the time. Their use distributes load across the system and promotes a higher MTBF at system and component level from reduced stress of each component. There is minimal disruption to the service from quick switchover to Hot Standby with replicated capabilities and resource s. This type of redundancy is used to support critical services and business activity that cannot tolerate any level of disruption. This option is relatively expensive because it involves asset-specific or dedicated capacity.
7.5.5.2 Passive redundancy
Redundant assets enter service when failure s occur. They are idle in the meantime or are otherwise used. There is switchover time involved. If this time is tolerable by the service or business activity , then passive redundancy could be a less expensive alternative to active redundancy. The capacity used is less asset -specific so its cost may be spread across several services or contract s.
7.5.5.3 Diverse redundancy
Diverse redundancy is from different types of service asset s sharing certain capabilities but with distinctive strengths and weaknesses. This makes diverse redundancy resistant to a single cause of failure. It is harder to implement because of the integration element between diverse types of assets. This type of redundancy is used when there is high uncertainty about the causes of failure.
7.5.5.4 Homogeneous redundancy
Homogeneous redundancy is from extra capacity of the same type of service assets. It is useful when there is high certainty about the causes of failure, and sufficient capacity is necessary to support demand. It is simpler to implement and maintain.
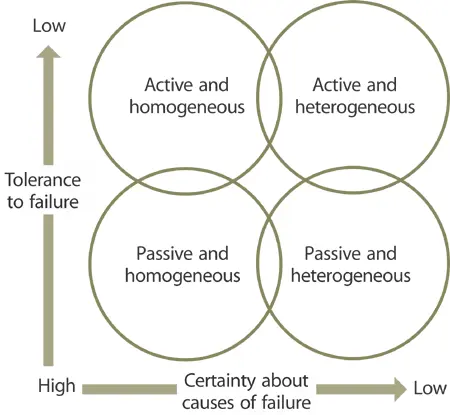
Figure 7.20 Choosing the right type of redundancy
7.5.6 Time between failures and accessibility
Reliability and maintainability are factors of service availability defined in terms of faults and failures of one or more of the underlying service assets. However, what matters to user s is whether they can utilize the service or not. MTBF and MTRS mean little to them unless service level s are degraded or disrupted. The availability of services can be low even when service assets have high MTBF and low MTRS. In the time between failures, users expect the service to be easily accessible for utilization without inconvenience and undue effort on their part. Accessibility of a service is illustrated by the following examples.
Читать дальшеИнтервал:
Закладка:
Обсуждение, отзывы о книге «SS» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.