Нихиль Будума - Основы глубокого обучения
Здесь есть возможность читать онлайн «Нихиль Будума - Основы глубокого обучения» — ознакомительный отрывок электронной книги совершенно бесплатно, а после прочтения отрывка купить полную версию. В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Город: Москва, Год выпуска: 2020, ISBN: 2020, Издательство: Манн, Иванов и Фербер, Жанр: economics, на русском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.

- Название:Основы глубокого обучения
- Автор:
- Издательство:Манн, Иванов и Фербер
- Жанр:
- Год:2020
- Город:Москва
- ISBN:9785001464723
- Рейтинг книги:3 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
Основы глубокого обучения: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «Основы глубокого обучения»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
Основы глубокого обучения — читать онлайн ознакомительный отрывок
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «Основы глубокого обучения», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
У нас только один вес, и мы используем случайную инициализацию и пакетный градиентный спуск для поиска его оптимального значения. Но поверхность ошибки имеет плоскую область (известную в пространствах с большим числом измерений как седловая точка). Если нам не повезет, то при пакетном градиентном спуске мы можем застрять в ней.
Другой возможный подход — стохастический градиентный спуск (СГС). При каждой итерации поверхность ошибки оценивается только для одного примера. Этот подход проиллюстрирован на рис. 2.7, где поверхность ошибки не единая статичная, а динамическая. Спуск по ней существенно улучшает нашу способность выходить из плоских областей.
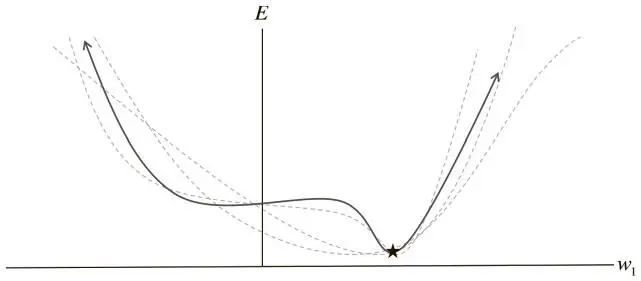
Рис. 2.7. Стохастическая поверхность ошибки варьирует по отношению к пакетной, что позволяет решить проблему седловых точек
Основной недостаток стохастического градиентного спуска в том, что рассмотрение ошибки для одного примера может оказаться недостаточным приближением поверхности ошибки.
Это, в свою очередь, приводит к тому, что спуск займет слишком много времени. Один из способов решения проблемы — использование мини-пакетного градиентного спуска . При каждой итерации мы вычисляем поверхность ошибки по некой выборке из общего набора данных (а не одному примеру). Это и есть мини-пакет (minibatch), и его размер, как и темп обучения, — гиперпараметр. Мини-пакеты уравновешивают эффективность пакетного градиентного спуска и способность избегать локальных минимумов, которую предоставляет стохастический градиентный спуск. В контексте обратного распространения ошибок изменение весов выглядит так:
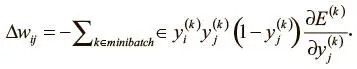
Это идентично тому, что мы вывели в предыдущем разделе. Но вместо того чтобы суммировать все примеры в наборе данных, мы обобщаем все примеры из текущего мини-пакета.
Переобучение и наборы данных для тестирования и проверки
Одна из главных проблем искусственных нейросетей — чрезвычайная сложность моделей. Рассмотрим сеть, которая получает данные от изображения из базы данных MNIST (28×28 пикселов), передает их в два скрытых слоя по 30 нейронов, а затем в слой с мягким максимумом из 10 нейронов. Общее число ее параметров составляет около 25 тысяч. Это может привести к серьезным проблемам. Чтобы понять почему, рассмотрим еще один упрощенный пример (рис. 2.8).
Рис. 2.8. Две модели, которыми может быть описан наш набор данных: линейная и многочлен 12-й степени
У нас есть ряд точек на плоской поверхности, задача — найти кривую, которая наилучшим образом опишет этот набор данных (то есть позволит предсказывать координату y новой точки, зная ее координату x). Используя эти данные, мы обучаем две модели: линейную и многочлен 12-й степени. Какой кривой стоит доверять? Той, которая не попадает почти ни в один обучающий пример? Или сложной, которая проходит через все точки из набора? Кажется, можно доверять линейному варианту, ведь он кажется более естественным. Но на всякий случай добавим данных в наш набор! Результат показан на рис. 2.9.
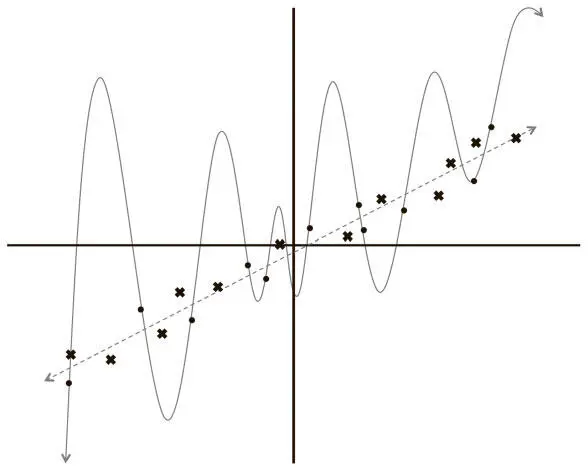
Рис. 2.9. Оценка модели на основе новых данных показывает, что линейная модель работает гораздо лучше, чем многочлен 12-й степени
Вывод очевиден: линейная модель не только субъективно, но и количественно лучше (по показателю квадратичной ошибки). Но это ведет к очень интересному выводу по поводу усвоения информации и оценки моделей машинного обучения. Строя очень сложную модель, легко полностью подогнать ее к обучающему набору данных. Ведь мы даем ей достаточно степеней свободы для искажения, чтобы вписаться в имеющиеся значения. Но когда мы оцениваем такую модель на новых данных, она работает очень плохо, то есть слабо обобщает . Это явление называется переобучением. И это одна из главных сложностей, с которыми вынужден иметь дело инженер по машинному обучению. Нейросети имеют множество слоев с большим числом нейронов, и в области глубокого обучения эта проблема еще значительнее. Количество соединений в моделях составляет миллионы. В результате переобучение — обычное дело (что неудивительно).
Рассмотрим, как это работает в нейросети. Допустим, у нас есть сеть с двумя входными значениями, выходной слой с двумя нейронами с функцией мягкого максимума и скрытый слой с 3, 6 или 20 нейронами. Мы обучаем эти нейросети при помощи мини-пакетного градиентного спуска (размер мини-пакета 10); результаты, визуализированные в ConvNetJS, показаны на рис. 2.10 [12].
Читать дальшеИнтервал:
Закладка:
Похожие книги на «Основы глубокого обучения»
Представляем Вашему вниманию похожие книги на «Основы глубокого обучения» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.












Обсуждение, отзывы о книге «Основы глубокого обучения» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.