Julia Moira Radtke - Sich einen Namen machen
Здесь есть возможность читать онлайн «Julia Moira Radtke - Sich einen Namen machen» — ознакомительный отрывок электронной книги совершенно бесплатно, а после прочтения отрывка купить полную версию. В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Жанр: unrecognised, на немецком языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.

- Название:Sich einen Namen machen
- Автор:
- Жанр:
- Год:неизвестен
- ISBN:нет данных
- Рейтинг книги:5 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
Sich einen Namen machen: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «Sich einen Namen machen»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
Mit ihrer empirisch basierten Arbeit, deren Datengrundlage 11.000 Aufnahmen von Graffitis aus Mannheim bilden, legt die Autorin die erste umfassende wissenschaftliche Beschreibung dieser Namenart vor. Da die Graffitinamen im Fokus stehen, ist die Arbeit in erster Linie der Onomastik zuzuordnen. Um die Pseudonyme angemessen beschreiben zu können, werden in der Untersuchung aber auch Ansätze der Multimodalitäts- und Schriftbildlichkeitsforschung sowie der Linguistic-Landscape-Forschung verarbeitet.
Sich einen Namen machen — читать онлайн ознакомительный отрывок
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «Sich einen Namen machen», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
Die Zusammenstellung des Korpus erfolgt über die „technique of photographic data collection“, die eine typische Herangehensweise der Linguistic-Landscape-Forschung darstellt (PUZEY 2016: 398).22 Die Daten wurden bei dieser Untersuchung allerdings nicht selbst erhoben, sondern es wurde ein bereits existierender Datenbestand für die wissenschaftliche Erforschung der Graffitinamen genutzt. Bei der Auswertung der Daten werden ferner (auch) typische Methoden der Onomastik wie „die Analyse des formalen Baus der Namen“ und die „Klassifikation der Namen (nach verschiedenen Gesichtspunkten)“ (BLANÁR 2004: 159) angewandt.
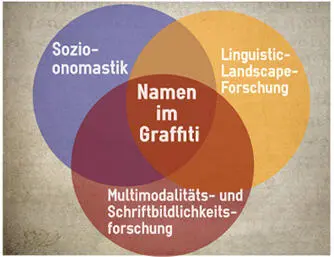
Abb. 2: Das Thema dieser Arbeit im Schnittbereich der Teildisziplinen
Das Thema „Namen im Graffiti“ betrifft somit sowohl inhaltlich als auch methodisch verschiedene linguistische Forschungsbereiche. Wie Abb. 2 zusammenfasst, ist es in der Linguistic-Landscape-Forschung, der Namenforschung und der Multimodalitäts- bzw. Schriftbildlichkeitsforschung zu verorten. Des Weiteren lässt sich aus den bisherigen Ausführungen festhalten, dass für eine Erforschung der Graffitinamen sowohl ein empirischer als auch ein theoretischer Bedarf besteht. Die vorliegende Arbeit macht es sich zum Ziel, die ermittelte Forschungslücke zu schließen und wird dabei von den folgenden Fragestellungen geleitet:
Wie lassen sich Graffitinamen namentheoretisch einordnen? Welche formalen und funktionalen Unterschiede ergeben sich zu anderen Namen- und Pseudonymentypen?
Mit welchem theoretischen Ansatz bzw. Konzept lassen sich die Namen angemessen beschreiben?
Welche (schrift-)sprachlichen und (schrift-)bildlichen Muster bestimmen die Graffitinamen und welche Funktionen kennzeichnen sie?
Um diese Fragen zu beantworten, wird in Kapitel 2 zunächst das Phänomen Graffiti beschrieben. Dabei werden auch Informationen zum soziokulturellen Kontext der deutschen Graffitiszene zusammengestellt, denn im Rahmen einer sozioonomastischen Studie werden Namen – wie bereits erläutert – vor der Folie ihres sozialen, kulturellen und situativen Kontextes betrachtet. An dieser Stelle sei bereits darauf hingewiesen, dass Theorie und Empirie dabei nicht immer strikt getrennt werden können: Sowohl in Kapitel 2 als auch in den folgenden Kapiteln werden bereits Fallbeispiele aus dem Korpus, das der empirischen Untersuchung zugrunde liegt, einbezogen.
In Kapitel 3 wird das Grundlagenwissen der Onomastik zusammengefasst, auf das bei der namentheoretischen Verortung der Graffitinamen zurückgegriffen wird. Es schließt ein Kapitel zu Pseudonymen an, das aufzeigt, wie Pseudonyme im System der Namen zu verorten sind und auf welche Beobachtungsschwerpunkte sich die bisherige Pseudonymenforschung konzentrierte (Kapitel 4).
Im 5. Kapitel wird herausgearbeitet, worin die allgemeine Spezifik der Graffitipseudonyme besteht, um anschließend – an dieser Spezifik ausgerichtet – einen theoretischen Rahmen auszuwählen, der eine angemessene Beschreibung der Namen ermöglicht. Es kann bereits vorweggenommen werden, dass sich hier als wichtig erweisen wird, einen erweiterten Bedeutungsbegriff zugrunde zu legen: Neben den Bedeutungen, die sich aus der Schriftsprachlichkeit der Namen ergeben, gilt es auch andere Möglichkeiten der Bedeutungsgenerierung zu berücksichtigen.
Den Bedeutungen, die sich aus der Schriftbildlichkeit ergeben, widmet sich anschließend Kapitel 6. In diesem wird erläutert, wie der Phänomenbereich der Bildlichkeit der Schrift in der bisherigen Forschung abgesteckt worden ist. Darüber hinaus werden verschiedene Ansätze dazu vorgestellt und diskutiert, wie Typographie bzw. die Schriftbildlichkeit überhaupt Bedeutung generieren kann.
Kapitel 7 umfasst die empirische Untersuchung der Graffitinamen. Es beinhaltet eine ausführliche Erläuterung des Korpus, der Methodik und der Ergebnisse. Die Ergebnisse werden in zwei separaten Teilkapiteln (7.4 und 7.5) dargestellt, da die linienförmig gestalteten Namen, die in der Graffitiszene als Tags 23 bezeichnet werden, und die flächig gestalteten Namen, die Pieces , separat voneinander in den Blick genommen werden. Die Ergebnisse der Untersuchung der Tags bestehen insbesondere in der Beschreibung und Analyse der (schrift-)bildlichen und (schrift-)sprachlichen Muster, die sich in den Mannheimer Graffitipseudonymen aufdecken ließen. Da der Graffitiname in den Pieces typischerweise von anderen Einheiten umgeben ist und mit diesen komplexere Kompositionen bildet, liefert die Untersuchung der Pieces in erster Linie Erkenntnisse zu den Formen und Funktionen der verschiedenen Einheiten, aus denen die Kompositionen bestehen können.
1.2 Forschungsgegenstand
Die Datenbasis dieser Untersuchung bilden Aufnahmen von Graffitis aus Mannheim. Im Fokus stehen dabei die Formen, die dem modernen Szenegraffiti zugeschrieben werden können (vgl. dazu Kapitel 2). Es werden damit weder rein bildliche Werke in den Blick genommen, wie sie etwa im Bereich der Street-Art zu finden sind, noch politische Sprüche und Parolen, die sich ebenfalls im öffentlichen Raum in Mannheim finden lassen und dementsprechend auch auf dem Bildmaterial zu sehen sind. Stattdessen geht es um diejenigen Formen, die sich durch ihre besonderen bildlichen und schriftlichen Eigenschaften als Szenegraffitis zu erkennen geben.
Die oben formulierten Fragestellungen werden anhand eines datenbankbasierten Korpus beantwortet, das aus Fotografien von Szenegraffitis und den entsprechenden Annotationen besteht. Das Korpus ist Teil der DFG-geförderten Forschungsdatenbank INGRID („Informationssystem Graffiti in Deutschland“), die derzeit an der Universität Paderborn und dem Karlsruher Institut für Technologie (KIT) aufgebaut wird (vgl. zu INGRID PAPENBROCK UND TOPHINKE 2018).
Graffiti stellt ein für die Wissenschaft relevantes Thema dar, weil es einen konstanten Bestandteil unserer kulturellen Wirklichkeit darstellt. Die gesprühten Schriftbilder finden sich nicht nur in nahezu jeder europäischen Großstadt, sondern sie sind auch durch ihre anhaltende Präsenz in den Medien, in der Werbung und sogar im politischen Wahlkampf zu einem festen Bestandteil des kulturellen Alltags geworden (PAPENBROCK 2015: 173f.). MAI formuliert daher treffend: „Writing is culture.“ (2005: 14) Als kulturelle Erzeugnisse einer bestimmten Zeit geben Graffitis Einblicke in soziale Gruppen, deren Strukturen und Aktionsräume, die für diese Gruppen relevanten Themen, den Umgang mit Schriftlichkeit im öffentlichen Raum und vieles mehr.
Um Graffitis als Forschungsgegenstand nutzen zu können, müssen sie jedoch in großem Umfang und über einen längeren Zeitraum erhoben und für die wissenschaftliche Erforschung aufbereitet werden (PAPENBROCK 2015: 182f.). Wissenschaftler, die Graffitis systematisch erforschen wollten, sahen sich dabei bislang jedoch mit einigen Herausforderungen konfrontiert. Ein größeres Datenkorpus selbst zu erstellen, ist für Einzelpersonen schwierig, weil für die Korpusgenerierung in der Regel nur begrenzte zeitliche Ressourcen zur Verfügung stehen. Da Graffitis nicht dauerhaft bestehen, ist es darüber hinaus problematisch, Bestände mit einer zeitlichen Tiefe zusammenzustellen. Auch der Rückgriff auf bereits bestehende Bildbestände, die es überwiegend abseits der universitären Forschung gibt, bietet immer noch keine wirkliche Alternative. Größere Graffiti-Bildbestände finden sich beispielsweise auf Internetseiten der Szene (z.B. auf Instagram, Facebook sowie auf Szeneseiten wie ilovegraffiti.de und streetfiles.org 1). Diese Bilder sind jedoch aus rechtlichen Gründen nicht für die wissenschaftliche Erforschung von Graffiti geeignet. Problematisch ist zum einen, dass die Bildrechte in der Regel nicht geklärt sind. Zum anderen sind die Aufnahmen oft nicht nach wissenschaftlichen Standards bearbeitet, d.h., es liegen keine Informationen zum Fotografen, zum Aufnahmeort und zum Aufnahmedatum vor. Auch Sammlungen von Privatpersonen, z.B. die des Ethnologen Peter Kreuzer (München) oder die des Psychologen Norbert Siegl (Wien), waren bislang nicht für eine wissenschaftliche Erforschung von Graffitis geeignet. Das Problem besteht hierbei darin, dass die Bilder entweder nicht digitalisiert und verschlagwortet und/oder für wissenschaftliche Zwecke nicht frei zugänglich sind.2
Читать дальшеИнтервал:
Закладка:
Похожие книги на «Sich einen Namen machen»
Представляем Вашему вниманию похожие книги на «Sich einen Namen machen» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.












Обсуждение, отзывы о книге «Sich einen Namen machen» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.