Bioinformatics
Здесь есть возможность читать онлайн «Bioinformatics» — ознакомительный отрывок электронной книги совершенно бесплатно, а после прочтения отрывка купить полную версию. В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Жанр: unrecognised, на английском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.

- Название:Bioinformatics
- Автор:
- Жанр:
- Год:неизвестен
- ISBN:нет данных
- Рейтинг книги:4 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
Bioinformatics: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «Bioinformatics»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
“This book is a gem to read and use in practice.”
— "This volume has a distinctive, special value as it offers an unrivalled level of details and unique expert insights from the leading computational biologists, including the very creators of popular bioinformatics tools."
— “A valuable survey of this fascinating field. . . I found it to be the most useful book on bioinformatics that I have seen and recommend it very highly.”
— “This should be on the bookshelf of every molecular biologist.”
— The field of bioinformatics is advancing at a remarkable rate. With the development of new analytical techniques that make use of the latest advances in machine learning and data science, today’s biologists are gaining fantastic new insights into the natural world’s most complex systems. These rapidly progressing innovations can, however, be difficult to keep pace with.
The expanded fourth edition of the best-selling
aims to remedy this by providing students and professionals alike with a comprehensive survey of the current field. Revised to reflect recent advances in computational biology, it offers practical instruction on the gathering, analysis, and interpretation of data, as well as explanations of the most powerful algorithms presently used for biological discovery.
offers the most readable, up-to-date, and thorough introduction to the field for biologists at all levels, covering both key concepts that have stood the test of time and the new and important developments driving this fast-moving discipline forwards.
This new edition features:
New chapters on metabolomics, population genetics, metagenomics and microbial community analysis, and translational bioinformatics A thorough treatment of statistical methods as applied to biological data Special topic boxes and appendices highlighting experimental strategies and advanced concepts Annotated reference lists, comprehensive lists of relevant web resources, and an extensive glossary of commonly used terms in bioinformatics, genomics, and proteomics
is an indispensable companion for researchers, instructors, and students of all levels in molecular biology and computational biology, as well as investigators involved in genomics, clinical research, proteomics, and related fields.
Bioinformatics — читать онлайн ознакомительный отрывок
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «Bioinformatics», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
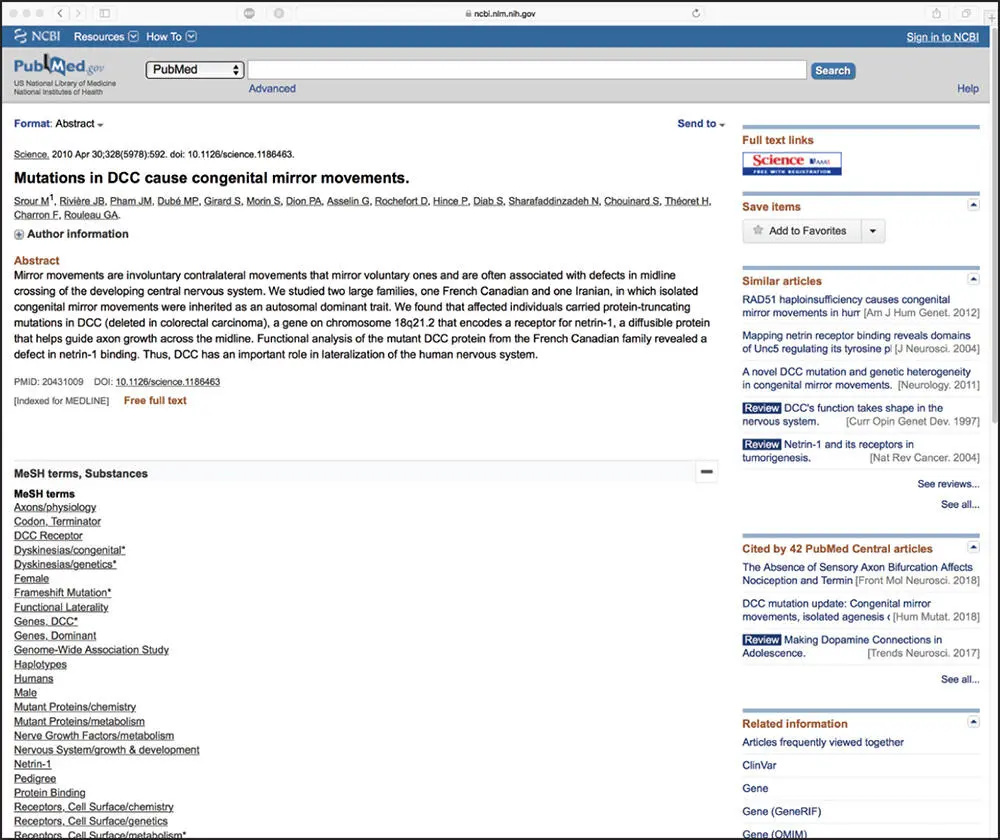
Figure 2.3 An example of a PubMed record in Abstract format, as returned through Entrez. This Abstract view is for the third reference shown in Figure 2.2. This view provides connections to related articles, sequence information, and the full-text journal article through the Discovery Column that runs down the right-hand side of the page. See text for details.
The column on the right-hand side of this window – aptly named the Discovery Column – provides access to the full-text version of the paper and, more importantly, contains many useful links to additional information related to this manuscript. The Similar articles section provides one of the entry points from which the user can take advantage of the neighboring and hard link relationships described earlier and, in the examples that follow, we will return to this page several times to illustrate a selected cross-section of the kinds of information available to the user. To begin this journey, if the user clicks on the See all link at the bottom of that section, Entrez will return a list of 104 references related to the original Rouleau paper at the time of this writing; the first six of these papers are shown in Figure 2.4. The first paper in the list is the same Rouleau paper because, by definition, it is most related to itself (the “parent” entry). The order in which the related papers follow is based on statistical similarity. Thus, the entry closest to the parent is deemed to be the closest in subject matter to the parent. By scanning the titles, the user can easily find related information on other studies, as well as quickly amass a bibliography of relevant references. This is a particularly useful and time-saving function when one is writing grants or papers, as abstracts can easily be scanned and papers of real interest can be identified quickly.
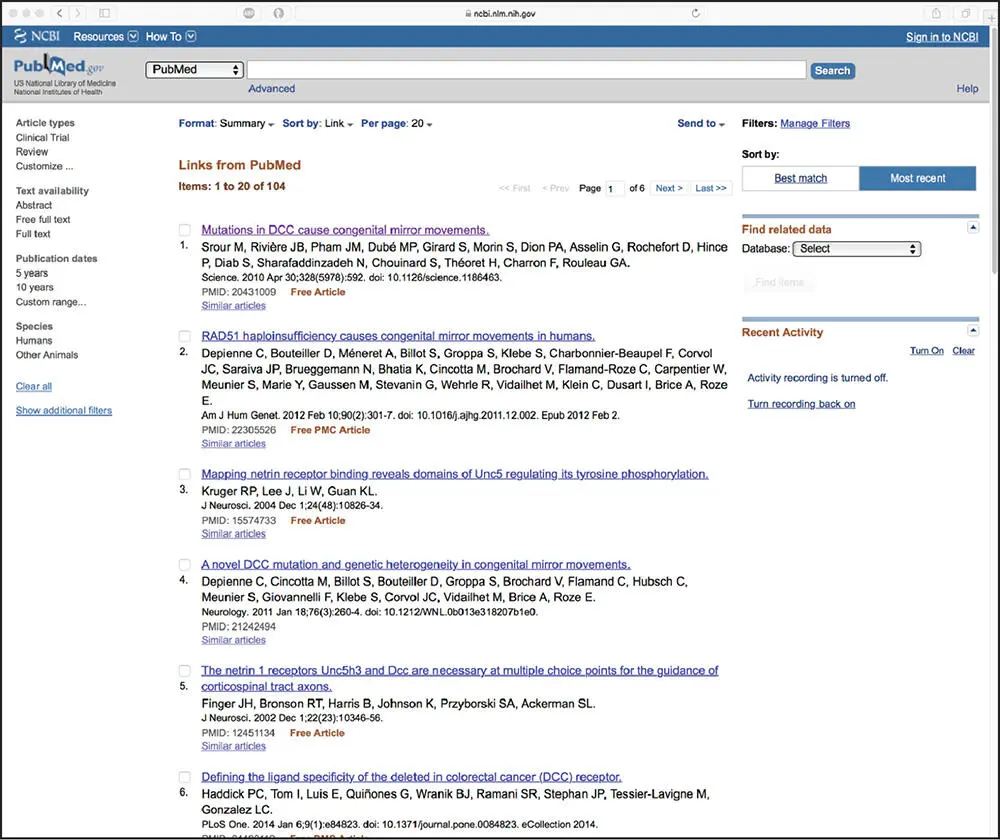
Figure 2.4 Neighbors to an entry found in PubMed. The original entry from Figure 2.3(Srour et al. 2010) is at the top of the list, indicating that this is the parent entry. Additional neighbors to each of the papers in this list can be found by clicking the Similar articles link found below each entry. See text for details.
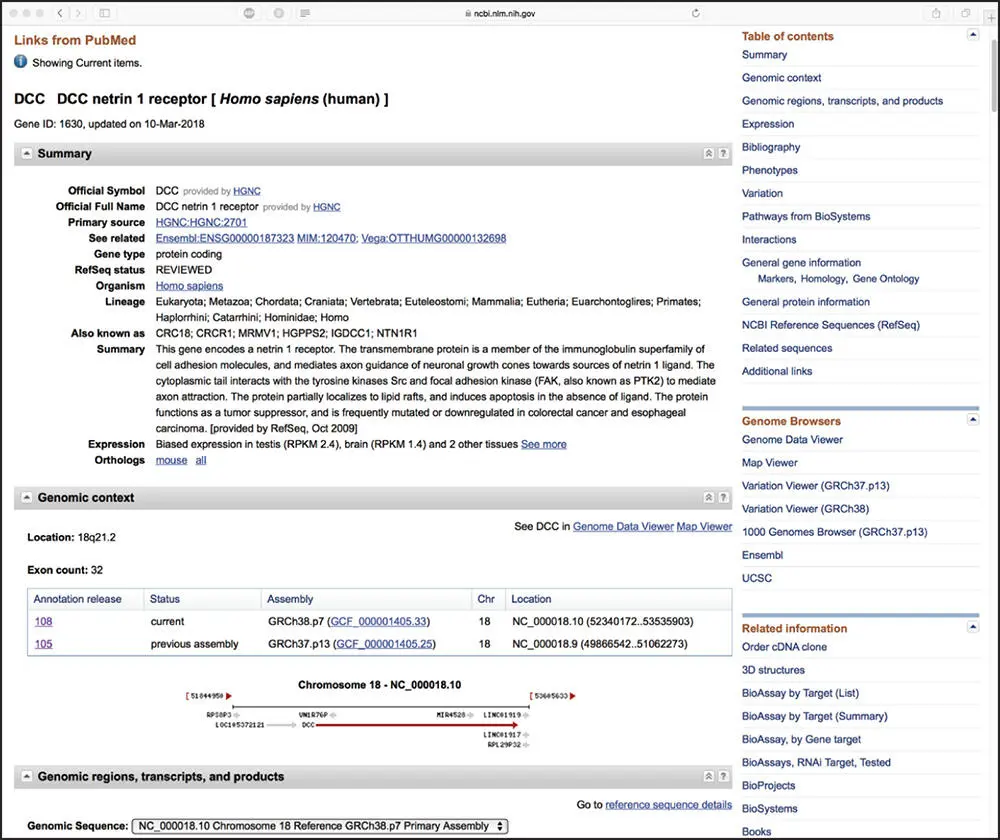
Figure 2.5 The Entrez Gene page for the DCC (deleted in colorectal carcinoma) netrin-1 receptor from human. The entry indicates that this is a protein-coding gene at map location 18q21.2, and information on the genomic context of DCC , as well as alternative gene names and information on the encoded protein, is provided. An extensive collection of links to other National Center for Biotechnology Information (NCBI) and external databases is also provided. See text for details.
Returning to the Abstract view presented in Figure 2.3, at the bottom of the Discovery Column is a series of hard-link connections to other databases within the Entrez system that can take the user directly to an extensive set of information related to the content of the publication of interest. Here, selecting the Gene link takes the user to Entrez Gene, a feature of Entrez that provides a wealth of information about the gene in question ( Figure 2.5). The data are gathered from a variety of sources, including RefSeq. Here, we see that DCC is the official symbol of a protein-coding gene for a netrin-1 receptor in humans. The Genomic context section of this page indicates that the DCC is a protein-coding gene at map location 18q21.2. Immediately below, summary information on the genomic region, transcripts, and products of the DCC gene are presented graphically, with genomic coordinates provided. Additional content not shown in the figure can be found by scrolling down the Gene page, where the user will find relevant functional information (such as gene expression data), associated phenotypes, information on protein–protein interactions, pathway information, Gene Ontology assignments, and homologies to similar sequences in selected organisms. Shortcut links to these sections can be found in the Table of contents at the top of the Discovery Column. Further down the Discovery Column are extensive lists of links to additional resources provided through NCBI and other sources. One link of note is the SNP: Gene View link, taking the user to data derived from dbSNP ( Figure 2.6). The information found within dbSNP goes beyond just single-nucleotide polymorphisms (SNPs), including data on short genetic variations such as short insertions and deletions, short tandem repeats, and microsatellites. Here, we will focus on the table shown in Figure 2.6, which is a straightforward way to view information about individual SNPs. Each SNP entry occupies two or more lines of the table, with one line showing the contig reference (the more common allele) and the other showing the SNP (the less common allele). Consider the first three lines of the table, showing a contig reference G for which there are two documented SNPs, changing the G at that position to either an A or a C. At the protein level, this changes the amino acid at position 2 of the DCC protein from glutamic acid to lysine (for the G-to-A substitution) or to glutamine (for the G-to-C substitution). These rows are colored red since these are “non-synonymous SNPs” – that is, the SNP produces a discrete change at the amino acid level. In contrast, consider the first set of green rows in the table, with the green indicating that this is a “synonymous SNP,” where the codons for the contig reference (G) and the SNP allele (A) ultimately produce the same amino acid (Glu); this is not altogether surprising, with the SNP being in the wobble position of the codon, where there is often redundancy in the genetic code. Additional information on human SNPs can be found in Chapter 15.
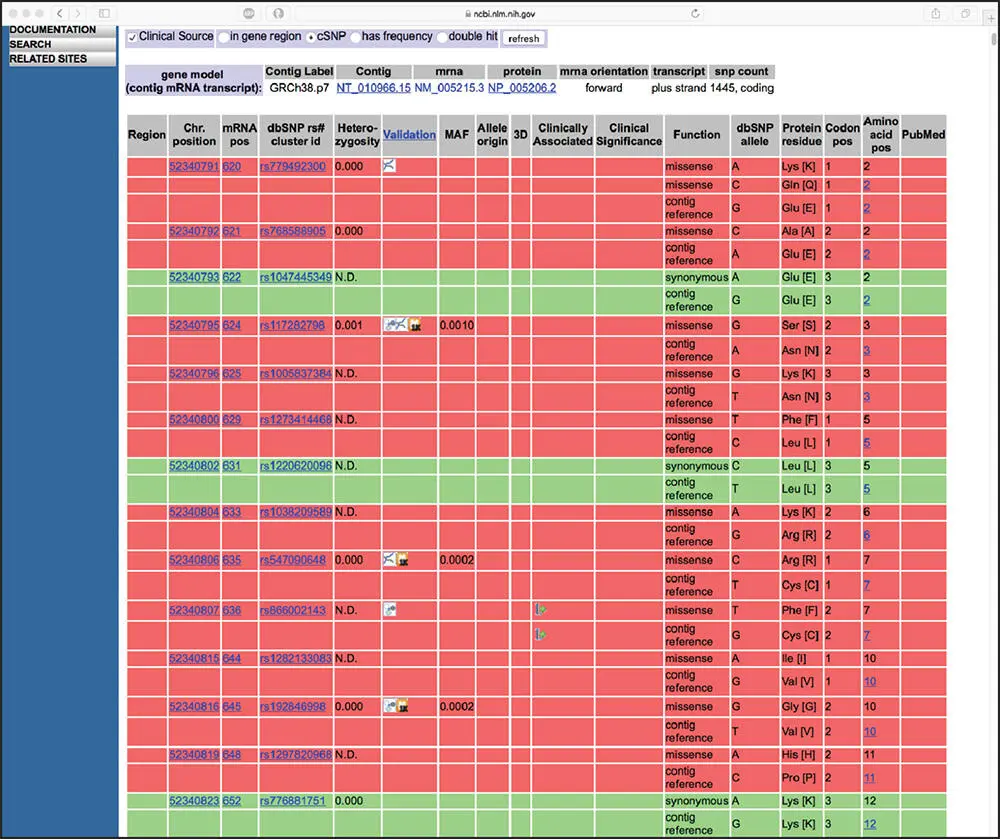
Figure 2.6 A section of the Database of Single Nucleotide Polymorphisms (dbSNP) GeneView page providing information on each SNP identified within the human DCC gene. See text for details.
Starting again from the Abstract view shown in Figure 2.3, protein sequences from RefSeq that have been linked to this abstract can be found by clicking on the Protein (RefSeq) link found in the Related information section on the right-hand side of the page, producing the view shown in Figure 2.7. Note that all but one of the entries is marked as “predicted”; the final entry in the list has an accession number beginning with NP, indicating that it contains an experimentally determined or verified sequence (see Box 1.2). Clicking on the first line of that entry (number 6) takes the user to the view shown in Figure 2.8, the RefSeq entry for the netrin receptor, the protein product of the DCC gene. The feature table – the section of the GenBank entry listing the location and characteristics of each of the documented biological features found within this protein sequence, such as post-translational modifications, recognizable repeat units, secondary structural regions, and clinically relevant variation – is particularly long in this case. This makes it difficult to determine the relative orientation of the features to one another and may lead the user to miss important interactions or relationships between biological features. Fortunately, a viewer that provides a bird's eye view of the elements found within the feature table is available by clicking on the Graphics link at the top of the entry, producing the more accessible display shown in Figure 2.9. Zoom controls are provided, and hovering over any of the elements in the display produces a pop-up containing the specific information for that feature from the GenBank entry.
Читать дальшеИнтервал:
Закладка:
Похожие книги на «Bioinformatics»
Представляем Вашему вниманию похожие книги на «Bioinformatics» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.




Обсуждение, отзывы о книге «Bioinformatics» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.