Fog Computing
Здесь есть возможность читать онлайн «Fog Computing» — ознакомительный отрывок электронной книги совершенно бесплатно, а после прочтения отрывка купить полную версию. В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Жанр: unrecognised, на английском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.

- Название:Fog Computing
- Автор:
- Жанр:
- Год:неизвестен
- ISBN:нет данных
- Рейтинг книги:5 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
Fog Computing: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «Fog Computing»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
focuses on the technological aspects of employing fog computing in various application domains, such as smart healthcare, industrial process control and improvement, smart cities, and virtual learning environments. In addition, the Machine-to-Machine (M2M) communication methods for fog computing environments are covered in depth.
Presented in two parts—Fog Computing Systems and Architectures, and Fog Computing Techniques and Application—this book covers such important topics as energy efficiency and Quality of Service (QoS) issues, reliability and fault tolerance, load balancing, and scheduling in fog computing systems. It also devotes special attention to emerging trends and the industry needs associated with utilizing the mobile edge computing, Internet of Things (IoT), resource and pricing estimation, and virtualization in the fog environments.
Includes chapters on deep learning, mobile edge computing, smart grid, and intelligent transportation systems beyond the theoretical and foundational concepts Explores real-time traffic surveillance from video streams and interoperability of fog computing architectures Presents the latest research on data quality in the IoT, privacy, security, and trust issues in fog computing
provides a platform for researchers, practitioners, and graduate students from computer science, computer engineering, and various other disciplines to gain a deep understanding of fog computing.
Fog Computing — читать онлайн ознакомительный отрывок
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «Fog Computing», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
1 Latency constraints. The fog shares the same fundamental characteristics as the cloud in being able to perform different computational tasks closer to the end-user, making it ideal for latency-sensitive applications for which their requirements are too stringent for deployment in the cloud.
2 Network bandwidth constraints. Since the fog offers the possibility of performing data processing tasks closer to the edge of the network, lowering in the process the amount of raw data sent to the cloud, it is the perfect device to apply data analytics to obtain fast responses and send to the cloud for storage purposes only filtered data.
3 Resource constrained devices. Fog computing can perform computational tasks for constrained edge devices like smartphones and sensors. By offloading parts of the application from such constrained devices to nearby fog nodes, the energy consumption and life-cycle cost are decreased.
4 Increased availability. Another important aspect of fog computing represents the possibility of operating autonomously without reliable network connectivity to the cloud, increasing the availability of an application.
5 Better security and privacy. A fog device can process the private data locally without sending it to the cloud for further processing, ensuring better privacy and offering total control of collected data to the user. Furthermore, such devices can increase security as well, being able to perform a wide range of security functions, manage and update the security credential of constrained devices and monitor the security status of nearby devices.
The previous section introduces the edge computing paradigm as a solution to the cloud computing inefficiency for data processing when the data is produced and consumed at the edge of the network. Fog computing focuses more on the infrastructure side by providing more powerful fog devices (i.e. fog node may be high computation device, access points, etc.) while edge computing focuses more toward the “things” side (i.e. smartphone, smartwatch, gateway, etc.). The key difference between the edge computing and fog computing is where the computation is placed. While fog computing pushes processing into the lowest level of the network, edge computing pushes computation into devices, such as smartphones or devices with computation capabilities.
2.3.1 Fog Computing Architecture
Fog computing architecture is composed of highly dispersed heterogeneous devices with the intent of enabling deployment of IoT applications that require storage, computation, and networking resources distributed at different geographical locations [21]. Multiple high-level fog architectures have been proposed in the literature [22–24] that describe a three-layer architecture containing (1) the smart devices and sensor layer which collects data and send it forward to layer two for further processing, (2) the fog layer applies computational resources to analyze the received data and prepares it for the cloud, and (3) the cloud layer, which performs high intensive analysis tasks.
Bonomi et al. [10] present a fog software architecture (see Figure 2.4) consisting of the following key objectives:
Heterogeneous physical resources. Fog nodes are heterogeneous devices deployed on different components, such as edge routers, access points, and high-end servers. Each component has a different set of characteristics (i.e. RAM and storage) that enables a new set of functionalities. This platform can run on multiple OSes and software applications, deriving a wide range of hardware and software capabilities.
Fog abstraction layer. The fog abstraction layer consists of multiple generic application programming interfaces (APIs) enabling monitoring and controlling available physical resources like CPU, memory, energy, and network. This layer has the role of making accessible the uniform and programmable interface for seamless resource management and control. Furthermore, using generic APIs, it supports virtualization by monitoring and managing multiple hypervisors and OSes on a single machine with the purpose of improving resource utilization. Using virtualization enables the possibility of having multitenancy by supporting security, privacy, and isolation policies to ensure the isolation of different tenants on the same machine.
Fog service orchestration layer. The fog service orchestration layer has a distributed functionality and provides dynamic and policy-based management of fog services. This layer has to manage a diverse number of fog nodes capabilities; thus, a set of new technologies and components are introduced to aid this process. One of these components is a software agent called foglet capable of performing the orchestration functionality by analyzing the deployed services on the current fog node and its physical health. Other components are a distributed database that stores policies and resource metadata, a scalable communication bus to send control messages for resource management, and a distributed policy engine that has a single global view and can perform local changes on each fog node.
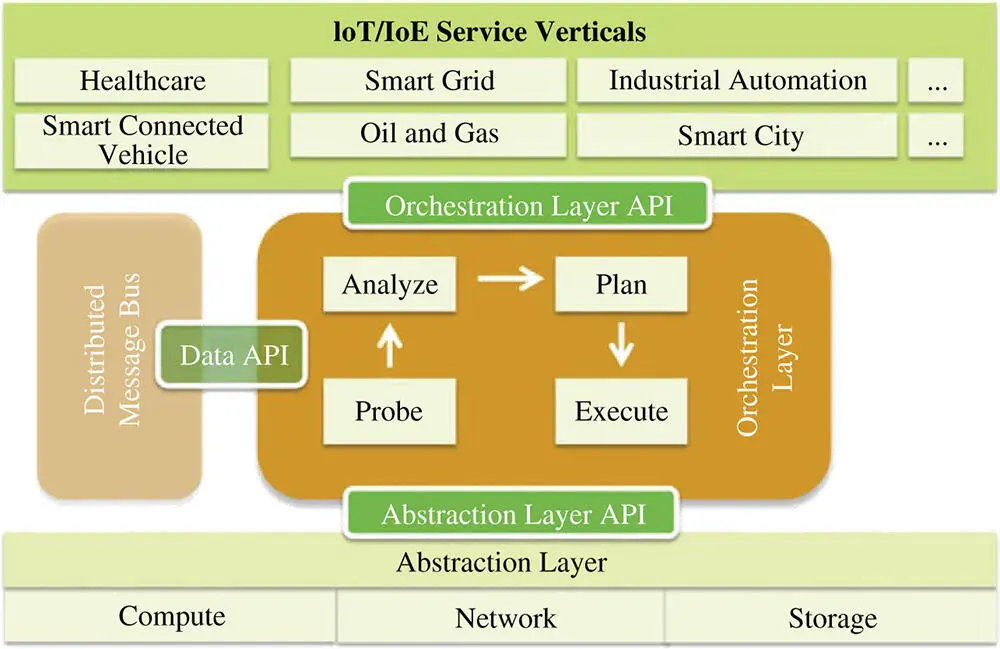
Figure 2.4 Fog computing architecture [10]. ( See color plate section for the color representation of this figure )
2.4 Fog and Edge Illustrative Use Cases
In this section, we present two illustrative use cases for both the fog and edge paradigms with the purpose of showing key features, helping us to further understand the concept and applicability in real-world applications.
2.4.1 Edge Computing Use Cases
The rapid growth of big data frameworks and applications such as smart cities, smart vehicles, healthcare, and manufacturing has pushed edge computing among the major topics in academia and industry. With the increasing demand for high availability in such systems, system requirements tend to increase over time. The stringent requirements of IoT systems have recently suggested the architectural placement of a computing entity closer to the network edge. This architectural shifting has many benefits, such as process optimization and interaction speed. For example, if a wearable ECG sensor were to use the cloud instead of the edge it will consistently send all data up to the centralized cloud. As a consequence, in such a scenario it will cause high communication latency and unreliable availability between the sensor and the centralized cloud. In real-time, safety-critical IoT use-cases, devices must comply to stringent constraints to avoid any fatal events. In this scenario, the latency delay introduced by sending the data to the cloud and back is inadmissible. Thus, in case of a critical event detected by the sensor, a local decision must be taken by the edge device, rather than sending data to the cloud.
Edge computing is well suited for IoT deployments where both storing and processing data can be leveraged locally. For example, consider a smart home where the sensory information is stored on the edge device. Simply by doing encryption and storing sensory information locally, edge computing shifts many security concerns from the centralized cloud to its edge devices. In addition, IoT applications consume less bandwidth, and they work even when the connection to the cloud is affected. Furthermore, edge devices may assist in scheduling the operational time of each appliance, minimizing the electricity cost in a smart home [25]. This strategy considers user preferences on each appliance determined from appliance-level energy consumption. All such examples can benefit from the edge computing paradigm and to demonstrate the role of this paradigm in different scenarios, we describe in this section two possible use cases in healthcare [12] and a smart home [3, 15].
Читать дальшеИнтервал:
Закладка:
Похожие книги на «Fog Computing»
Представляем Вашему вниманию похожие книги на «Fog Computing» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.












Обсуждение, отзывы о книге «Fog Computing» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.