Dan Sullivan - Official Google Cloud Certified Professional Data Engineer Study Guide
Здесь есть возможность читать онлайн «Dan Sullivan - Official Google Cloud Certified Professional Data Engineer Study Guide» — ознакомительный отрывок электронной книги совершенно бесплатно, а после прочтения отрывка купить полную версию. В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Жанр: unrecognised, на английском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.

- Название:Official Google Cloud Certified Professional Data Engineer Study Guide
- Автор:
- Жанр:
- Год:неизвестен
- ISBN:нет данных
- Рейтинг книги:4 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
Official Google Cloud Certified Professional Data Engineer Study Guide: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «Official Google Cloud Certified Professional Data Engineer Study Guide»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
, provides everything you need to prepare for this important exam and master the skills necessary to land that coveted Google Cloud Professional Data Engineer certification. Beginning with a pre-book assessment quiz to evaluate what you know before you begin, each chapter features exam objectives and review questions, plus the online learning environment includes additional complete practice tests.
Written by Dan Sullivan, a popular and experienced online course author for machine learning, big data, and Cloud topics,
is your ace in the hole for deploying and managing analytics and machine learning applications.
• Build and operationalize storage systems, pipelines, and compute infrastructure
• Understand machine learning models and learn how to select pre-built models
• Monitor and troubleshoot machine learning models
• Design analytics and machine learning applications that are secure, scalable, and highly available.
This exam guide is designed to help you develop an in depth understanding of data engineering and machine learning on Google Cloud Platform.
Official Google Cloud Certified Professional Data Engineer Study Guide — читать онлайн ознакомительный отрывок
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «Official Google Cloud Certified Professional Data Engineer Study Guide», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
NoSQL databases are less structured than relational databases, and there is no formal model, like relational algebra and forms of normalization, that apply to all NoSQL databases. The four types of NoSQL databases available in GCP are
Key-value
Document
Wide column
Graph
Each type of NoSQL database is suited for different use cases depending on data ingestion, entity relationships, and query requirements.
Key-Value Data Stores
Key-value data stores are databases that use associative arrays or dictionaries as the basic datatype. Keys are data used to look up values. An example of key-value data is shown in Table 1.7, which displays a mapping from names of machine instances to names of partitions associated with each instance.
Table 1.7 Examples of key-value data
| Key | Value |
| Instance1 | PartitionA |
| Instance2 | PartitionB |
| Instance3 | PartitionA |
| Instance4 | PartitionC |
Key-value data stores are simple, but it is possible to have more complex data structures as values. For example, a JSON object could be stored as a value. This would be reasonable use of a key-value data store if the JSON object was only looked up by the key, and there was no need to search on items within the JSON structure. In situations where items in the JSON structure should be searchable, a document database would be a better option.
Cloud Memorystore is a fully managed key-value data store based on Redis, a popular open source key-value datastore. As of this writing, Cloud Memorystore does not support persistence, so it should not be used for applications that do not need to save data to persistent storage. Open source Redis does support persistence. If you wanted to use Redis for a key-value store and wanted persistent storage, then you could run and manage your own Redis service in Compute Engine or Kubernetes Engine.
Document Databases
Document stores allow complex data structures, called documents , to be used as values and accessed in more ways than simple key lookup. When designing a data model for document databases , documents should be designed to group data that is read together.
Consider an online game that requires a database to store information about players’ game state. The player state includes
Player name
Health score
List of possessions
List of past session start and end times
Player ID
The player name, health score, and list of possessions are often read together and displayed for players. The list of sessions is used only by analysts reviewing how players use the game. Since there are two different use cases for reading the data, there should be two different documents. In this case, the first three attributes should be in one document along with the player ID, and the sessions should be in another document with player ID.
When you need a managed document database in GCP, use Cloud Datastore. Alternatively, if you wish to run your own document database, MongoDB, CouchDB, and OrientDB are options.
Wide-Column Databases
Wide-column databases are used for use cases with the following:
High volumes of data
Need for low-latency writes
More write operations than read operations
Limited range of queries—in other words, no ad hoc queries
Lookup by a single key
Wide-column databases have a data model similar to the tabular structure of relational tables, but there are significant differences. Wide-column databases are often sparse, with the exception of IoT and other time-series databases that have few columns that are almost always used.
Bigtable is GCP’s managed wide-column database. It is also a good option for migrating on-premises Hadoop HBase databases to a managed database because Bigtable has an HBase interface. If you wish to manage your own wide column, Cassandra is an open source option that you can run in Compute Engine or Kubernetes Engine.
Graph Databases
Another type of NoSQL database are graph databases , which are based on modeling entities and relationships as nodes and links in a graph or network. Social networks are a good example of a use case for graph databases. People could be modeled as nodes in the graph, and relationships between people are links, also called edges . For example, Figure 1.2shows an example graph of friends showing Chengdong with the most friends, 6, and Lem with the fewest, 1.
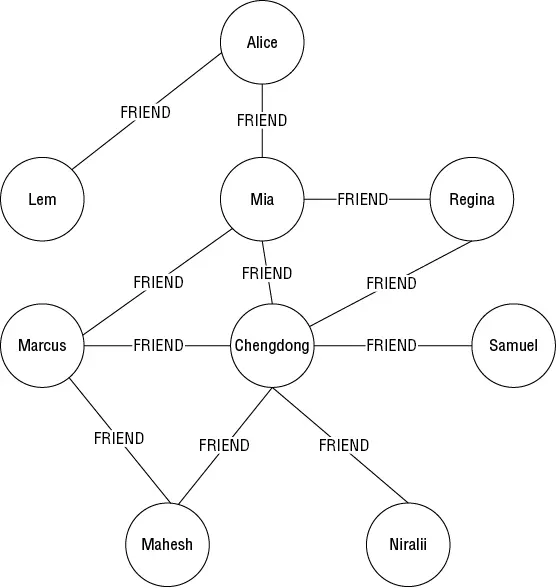
Figure 1.2 Example graph of friends
Data is retrieved from a graph using one of two types of queries. One type of query uses SQL-like declarative statements describing patterns to look for in a graph, such as the following the Cypher query language. This query returns a list of persons and friends of that person’s friends:
MATCH (n:Person)-[:FRIEND]-(f) MATCH (n)-[:FRIEND]-()-[:FRIEND]-(fof) RETURN n, fof
The other option is to use a traversal language, such as Gremlin, which specifies how to move from node to node in the graph.
GCP does not have a managed graph database, but Bigtable can be used as the storage backend for HGraphDB ( https://github.com/rayokota/hgraphdb) or JanusGraph ( https://janusgraph.org).
Exam Essentials
Know the four stages of the data lifecycle: ingest, storage, process and analyze, and explore and visualize.Ingestion is the process of bringing application data, streaming data, and batch data into the cloud. The storage stage focuses on persisting data to an appropriate storage system. Processing and analyzing is about transforming data into a form suitable for analysis. Exploring and visualizing focuses on testing hypotheses and drawing insights from data.
Understand the characteristics of streaming data.Streaming data is a set of data that is sent in small messages that are transmitted continuously from the data source. Streaming data may be telemetry data, which is data generated at regular intervals, and event data, which is data generated in response to a particular event. Stream ingestion services need to deal with potentially late and missing data. Streaming data is often ingested using Cloud Pub/Sub.
Understand the characteristics of batch data.Batch data is ingested in bulk, typically in files. Examples of batch data ingestion include uploading files of data exported from one application to be processed by another. Both batch and streaming data can be transformed and processed using Cloud Dataflow.
Know the technical factors to consider when choosing a data store.These factors include the volume and velocity of data, the type of structure of the data, access control requirements, and data access patterns.
Know the three levels of structure of data.These levels are structured, semi-structured, and unstructured. Structured data has a fixed schema, such as a relational database table. Semi-structured data has a schema that can vary; the schema is stored with data. Unstructured data does not have a structure used to determine how to store data.
Know which Google Cloud storage services are used with the different structure types.Structured data is stored in Cloud SQL and Cloud Spanner if it is used with a transaction processing system; BigQuery is used for analytical applications of structured data. Semi-structured data is stored in Cloud Datastore if data access requires full indexing; otherwise, it can be stored in Bigtable. Unstructured data is stored in Cloud Storage.
Читать дальшеИнтервал:
Закладка:
Похожие книги на «Official Google Cloud Certified Professional Data Engineer Study Guide»
Представляем Вашему вниманию похожие книги на «Official Google Cloud Certified Professional Data Engineer Study Guide» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.












Обсуждение, отзывы о книге «Official Google Cloud Certified Professional Data Engineer Study Guide» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.