Applied Modeling Techniques and Data Analysis 2
Здесь есть возможность читать онлайн «Applied Modeling Techniques and Data Analysis 2» — ознакомительный отрывок электронной книги совершенно бесплатно, а после прочтения отрывка купить полную версию. В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Жанр: unrecognised, на английском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.

- Название:Applied Modeling Techniques and Data Analysis 2
- Автор:
- Жанр:
- Год:неизвестен
- ISBN:нет данных
- Рейтинг книги:5 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
Applied Modeling Techniques and Data Analysis 2: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «Applied Modeling Techniques and Data Analysis 2»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
Applied Modeling Techniques and Data Analysis 2 — читать онлайн ознакомительный отрывок
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «Applied Modeling Techniques and Data Analysis 2», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
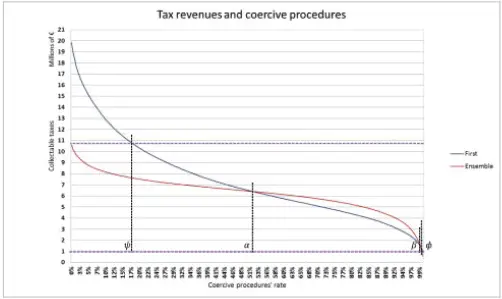
Figure 1.15. Models’ approximation. For a color version of this figure, see www.iste.co.uk/dimotikalis/analysis2.zip
Therefore, we have to study the two monotonically decreasing functions, say γ first( θ’”)and γ ens ( θ” ) to find out for which joint values of θ’and θ”, one model is better than the other.
Based on our data, these functions intersect at two points, where θ’ and θ” are, respectively, equal to α and β . Moreover:
– γ first(0) > γ ens(0), i.e. if all taxpayers were to pay their debts, the first model would be better than the ensemble one.
– γ first(1) > γ ens(1) since if all taxpayers were to undergo a coercive procedure, these functions’ values would be 0.05 times γ first(0) and γ ens(0), respectively (recall that in the case of coercive procedures, the collectable tax is assumed to be equal to the tax claim multiplied by a discount factor of 95%).
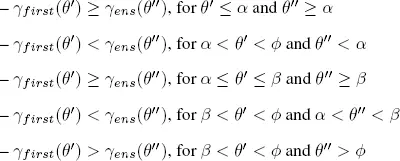
– There is a ψ such that γf irst( θ ‘) ≥ γ ens (θ”) , for θ’ ≤ ψ and for any θ” .
– There is a ø such that Yfi rs t(θ’)≥ γ ens (θ’’) , for θ’ ≥ ø and for any θ “.
Figure 1.16depicts, in a θ’ x θ” space, the regions where the two models represent the best choice (the dark gray region is where the first model is the best option, while in the light gray one, the ensemble model is better).
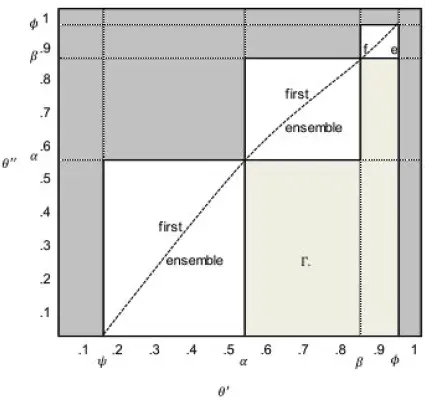
Figure 1.16. Values of θ’ and θ” determining the best model. For a color version of this figure, see www.iste.co.uk/dimotikalis/analysis2.zip
In the three white regions, the exact combinations of θ’ and θ” that guarantee whether a model is better than the other, depend on the relative slopes of γf irst ( θ’) and γ ens(θ” ).
As a general rule, if we expect small values of θ’ or high values of θ ‘, and also high values of θ’’ in our samples of auditable taxpayers, then the first model is likely to guarantee a higher revenue; otherwise, the ensemble model is the one that we should use. From Figure 1.16, we note that our experience on the 8,000 taxpayers dataset took us to point Γ, which lies in a region where the ensemble model is the best option.
Table 1.5. The most significant results of the models
| First model | Second model | Ensemble model | Test set | |
| Number of selected taxpayers | 415 | 415 | 415 | 2,676 |
| Interesting taxpayers rate | 82.20% | 32.77% | 42.89% | 43.12% |
| Coercive procedures rate | 70.12% | 17.35% | 24.58% | 38.12% |
| Average tax claim (€) | 49,094 | 20,388 | 26,219 | 22,339 |
| Average collectable tax (€) | 12,187 | 13,493 | 17,542 | 10,194 |
1.4. Discussion
The learning scheme developed in this chapter is aimed at computing a risk factor for each taxpayer, optimizing the tax authorities’ audit processes, taking into account two competing needs: the profitability of each tax notice and the effective collectability of the additional requested taxes.
The ensemble model seems to tackle both of the above-mentioned issues quite well.
Given that the whole test set’s average claim is € 22,339, while the average collectable taxes are equal to € 10,194, our procedure increases the first figure by 1.17% (€ 26,219) and the second by 72% (€ 17,542).
With respect to the scenario in which only the first model is put in place, by developing the twofold selection process as described above, the presence of coercive procedures dramatically plummets from 70% to 25%. Moreover, the selection of not interesting taxpayers, while causing a drop in the average tax claim (from € 49,094 to € 26,219), is more than compensated by the procedure’s capability of efficiently collecting the additional taxes charged to the selected taxpayers (from € 12,187 to 1 € 17,542).
Table 1.5summarizes the most significant results reached by the three models that have been built: the first model looks for interesting taxpayers; the second model is in search of solvent taxpayers; and the third model, called the ensemble model , is a combination of the first two. To better understand the figures referred to the models, the same information set is shown, related to the entire test set.
This result can be generalized, and the best selection strategy depends on our estimates of θ’ and θ” in the sets of the selected taxpayers.
1.5. Conclusion
The data analysis framework designed in this chapter gives an effective learning scheme aimed at improving the IRA’s ability to identify non-compliant taxpayers. It involves two C4.5 decision trees, predicting two different class values, based on two different predictive attribute sets. That is, the first model is built to identify the most likely non-compliant taxpayers, while the second one identifies the ones who are more likely going to pay the additional tax bill. This twofold selection process target is requested in order to maximize the overall audit effectiveness, so businesses will be audited, only if suggested by both models.
Tax evasion is a topic that has been studied extensively in the past (starting from Allingham and Sandmo 1972) and it is still a hot topic. Most models are usually mainly concerned with finding the best way to identify the most relevant cases of tax evasion. In this chapter, we go further, analyzing the overall effectiveness of the tax authorities activity, which has to take into account both the tax notices’ profitability and the collectability of the additional requested taxes.
The latter issue cannot be tackled without knowing the final stage of the tax notices. In fact, it is very difficult to have this kind of information at hand, even because a tax notice can come to an end years after it was sent to the taxpayer (especially when a tax court is addressed).
By ignoring the collectability aspect of the audit process, the selection processes may not be correctly targeted, or at least, may not satisfy the tax authorities’ needs i.e. relevant evasion phenomena may be discovered, but only little money may be collected.
Of course, the fight against tax evasion is not only a matter of collecting money, but should also have some other purposes, such as promoting taxpayers’ compliant behavior. Nonetheless, efficient tax bill collection is crucial from the state budget point of view, because public expenditures are strictly connected to public revenues.
The methodology we suggest here will soon be validated in real cases i.e. a sample of taxpayers will be selected according to the classification criteria developed in this chapter and will subsequently be involved in some audit processes.
Читать дальшеИнтервал:
Закладка:
Похожие книги на «Applied Modeling Techniques and Data Analysis 2»
Представляем Вашему вниманию похожие книги на «Applied Modeling Techniques and Data Analysis 2» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.












Обсуждение, отзывы о книге «Applied Modeling Techniques and Data Analysis 2» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.