Vahid Mirjalili - Python Machine Learning
Здесь есть возможность читать онлайн «Vahid Mirjalili - Python Machine Learning» — ознакомительный отрывок электронной книги совершенно бесплатно, а после прочтения отрывка купить полную версию. В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Жанр: unrecognised, на испанском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.

- Название:Python Machine Learning
- Автор:
- Жанр:
- Год:неизвестен
- ISBN:нет данных
- Рейтинг книги:4 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
Python Machine Learning: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «Python Machine Learning»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
Modernizado y ampliado para incluir las tecnologías de código abierto más recientes, como scikit-learn, Keras y TensorFlow, este manual proporciona el conocimiento práctico y las técnicas necesarias para crear eficaces aplicaciones de aprendizaje automático y aprendizaje profundo en Python.
El conocimiento y la experiencia únicos de Sebastian Raschka y Vahid Mirjalili presentan los algoritmos de aprendizaje automático y aprendizaje profundo, antes de continuar con temas avanzados en análisis de datos.
Combinan los principios teóricos del aprendizaje automático con un enfoque práctico de codificación para una comprensión completa de la teoría del aprendizaje automático y la implementación con Python.
Aprenderás a:
Explorar y entender los frameworks clave para la ciencia de datos, el aprendizaje automático y el aprendizaje profundo
Formular nuevas preguntas sobre datos con modelos de aprendizaje automático y redes neuronales
Aprovechar el poder de las últimas librerías de código abierto de Python para aprendizaje automático
Dominar la implementación de redes neuronales profundas con la librería de TensorFlow
Incrustar modelos de aprendizaje automáticos en aplicacions web accesibles
Predecir resultados objetivos continuos con análisis de regresión
Descubrir patrones ocultos y estructuras en datos con agrupamientos
Analizar imágenes mediante técnicas de aprendizaje profundo
Profundizar en datos de medios sociales y textuales con el análisis de sentimientos
Python Machine Learning — читать онлайн ознакомительный отрывок
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «Python Machine Learning», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
Los paquetes adicionales que se utilizarán en este libro se pueden instalar mediante el programa de instalación pip, que forma parte de la librería estándar de Python desde la versión 3.3. Puedes encontrar más información sobre el pip en https://docs.python.org/3/installing/index.html.
Una vez hemos instalado Python con éxito, podemos ejecutar el pip desde el terminal para instalar los paquetes de Python adicionales:
pip install SomePackage
Los paquetes ya instalados pueden ser actualizados con el comando --upgrade:
pip install SomePackage --upgrade
Utilizar la distribución y el gestor de paquetes Anaconda de Python
Una distribución de Python alternativa muy recomendada para cálculo científico es Anaconda, de Continuum Analytics. Anaconda es una distribución gratuita (incluso para uso comercial) de Python preparada para la empresa, que incluye todos los paquetes de Python esenciales para la ciencia de datos, matemáticas e ingeniería en una distribución multiplataforma fácil de usar. El instalador de Anaconda se puede descargar desde http://continuum.io/downloadsy hay disponible una guía de inicio rápido de Anaconda en https://conda.io/docs/test-drive.html.
Tras haber instalado Anaconda con éxito, podemos instalar los nuevos paquetes de Python mediante el siguiente comando:
conda install SomePackage
Los paquetes existentes se pueden actualizar mediante el siguiente comando:
conda update SomePackage
Paquetes para cálculo científico, ciencia de datos y aprendizaje automático
En este libro, utilizaremos principalmente matrices multidimensionales de NumPy para almacenar y manipular datos. De forma ocasional, utilizaremos pandas, una librería creada sobre NumPy que proporciona herramientas de manipulación de datos de alto nivel que permiten trabajar con datos tabulados de un modo más conveniente. Para aumentar nuestra experiencia de aprendizaje y visualizar datos cuantitativos, que a menudo es extremadamente útil para dar sentido a todo esto de manera intuitiva, utilizaremos la librería Matplotlib, que se puede personalizar en muchos aspectos.
Las versiones de los principales paquetes de Python que se han utilizado para escribir este libro son las que aparecen en la siguiente lista. Asegúrate de que la versión de los paquetes que has instalado sea igual o superior a estas versiones para garantizar que los ejemplos de código funcionen correctamente:
•NumPy 1.12.1
•SciPy 0.19.0
•scikit-learn 0.18.1
•Matplotlib 2.0.2
•pandas 0.20.1
Resumen
En este capítulo, hemos explorado el aprendizaje automático desde un nivel muy alto y nos hemos familiarizado con el panorama general y los principales conceptos que vamos a explorar con mayor detalle en los próximos capítulos. Hemos aprendido que el aprendizaje supervisado está compuesto por dos importantes subcampos: clasificación y regresión. Mientras que los modelos de clasificación nos permiten categorizar objetos en clases conocidas, podemos utilizar el análisis de regresión para predecir el resultado continuo de variables de destino. El aprendizaje sin supervisión no solo ofrece técnicas útiles para descubrir estructuras en datos sin etiquetar, sino que también puede ser útil para la compresión de datos en las etapas de preprocesamiento de características. Nos hemos referido brevemente a la hoja de ruta típica para aplicar el aprendizaje automático a problemas concretos, que usaremos como base para discusiones más profundas y ejemplos prácticos en los siguientes capítulos. Además, hemos preparado nuestro entorno Python e instalado y actualizado los paquetes necesarios para estar listos para ver en acción el aprendizaje automático.
Más adelante en este libro, además del aprendizaje automático en sí mismo, también presentaremos diferentes técnicas para preprocesar nuestros conjuntos de datos, que nos ayudarán a conseguir el mejor rendimiento de los distintos algoritmos de aprendizaje automático. Si bien cubriremos los algoritmos de clasificación de forma bastante extensa en todo el libro, también exploraremos diferentes técnicas para el análisis de regresión y la agrupación.
Tenemos un emocionante viaje por delante, en el que descubriremos potentes técnicas en el amplio campo del aprendizaje automático. Sin embargo, nos acercaremos al aprendizaje automático paso a paso, generando nuestro conocimiento de forma gradual a lo largo de los capítulos que componen este libro. En el capítulo siguiente, empezaremos este viaje implementando uno de los algoritmos de aprendizaje automático para clasificación, que nos prepara para el Capítulo 3, Un recorrido por los clasificadores de aprendizaje automático con scikit-learn, donde nos acercaremos a algoritmos de aprendizaje automático más avanzados con la librería de código abierto scikit-learn.

Entrenar algoritmos simples de aprendizaje automático para clasificación
En este capítulo, utilizaremos dos de los primeros algoritmos de aprendizaje automático descritos algorítmicamente para clasificación: el perceptrón y las neuronas lineales adaptativas. Empezaremos implementando un perceptrón paso a paso en Python y entrenándolo para que clasifique diferentes especies de flores en el conjunto de datos Iris. Esto nos ayudará a entender el concepto de algoritmos de aprendizaje automático para clasificación y cómo pueden ser implementados de forma eficiente en Python.
Tratar los conceptos básicos de la optimización utilizando neuronas lineales adaptativas sentará las bases para el uso de clasificadores más potentes con la librería de aprendizaje automático scikit-learn, como veremos en el Capítulo 3, Un recorrido por los clasificadores de aprendizaje automático con scikit-learn.
Los temas que trataremos en este capítulo son los siguientes:
•Crear una intuición para algoritmos de aprendizaje automático.
•Utilizar pandas, NumPy y Matplotlib para leer, procesar y visualizar datos.
•Implementar algoritmos de clasificación lineal en Python.
Neuronas artificiales: un vistazo a los inicios del aprendizaje automático
Antes de hablar con más detalle del perceptrón y de los algoritmos relacionados, echemos un vistazo a los comienzos del aprendizaje automático. Para tratar de entender cómo funciona el cerebro biológico, para diseñar la Inteligencia Artificial, Warren McCullock y Walter Pitts publicaron, en 1943, el primer concepto de una célula cerebral simplificada, la denominada neurona McCullock-Pitts (MCP), recogido en su libro A Logical Calculus of the Ideas Immanent in Nervous Activity [Un cálculo lógico de las ideas inmanentes en la actividad nerviosa], W. S. McCulloch y W. Pitts, Bulletin of Mathematical Biophysics [Boletín de Biofísica Matemática], 5(4): 115-133, 1943. Las neuronas son células nerviosas interconectadas en el cerebro que participan en el proceso y la transmisión de señales eléctricas y químicas, como se ilustra en la siguiente figura:
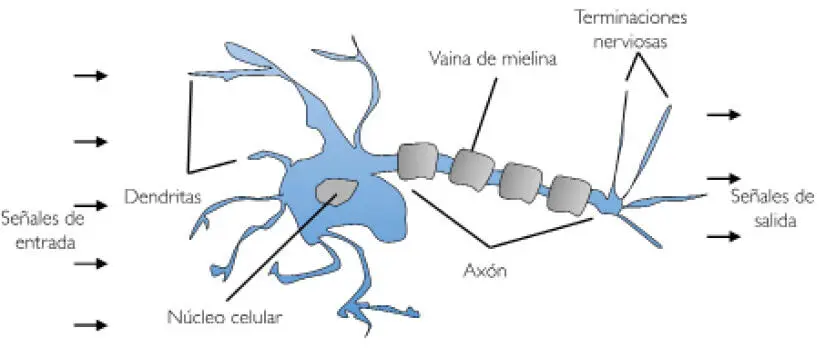
McCullock y Pitts describieron una célula nerviosa como una simple puerta lógicacon salidas binarias; múltiples señales llegan a las dendritas, a continuación se integran en el cuerpo de la célula y, si la señal acumulada supera un umbral determinado, se genera una señal de salida que será transmitida por el axón.
Solo unos años después, Frank Rosenblatt publicó el primer concepto de la regla de aprendizaje del perceptrón, basado en el modelo de la neurona MCP, en The Perceptron: A Perceiving and Recognizing Automaton [El perceptrón: un autómata de percepción y reconocimiento], F. Rosenblatt, Cornell Aeronautical Laboratory, 1957). Con esta regla del perceptrón, Rosenblatt propuso un algoritmo que podía automáticamente aprender los coeficientes de peso óptimo que luego se multiplican con las características de entrada para tomar la decisión de si una neurona se activa o no. En el contexto del aprendizaje supervisado y la clasificación, un algoritmo como este podría utilizarse para predecir si una muestra pertenece a una clase o a otra.
Читать дальшеИнтервал:
Закладка:
Похожие книги на «Python Machine Learning»
Представляем Вашему вниманию похожие книги на «Python Machine Learning» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.












Обсуждение, отзывы о книге «Python Machine Learning» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.