Vahid Mirjalili - Python Machine Learning
Здесь есть возможность читать онлайн «Vahid Mirjalili - Python Machine Learning» — ознакомительный отрывок электронной книги совершенно бесплатно, а после прочтения отрывка купить полную версию. В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Жанр: unrecognised, на испанском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.

- Название:Python Machine Learning
- Автор:
- Жанр:
- Год:неизвестен
- ISBN:нет данных
- Рейтинг книги:4 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
Python Machine Learning: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «Python Machine Learning»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
Modernizado y ampliado para incluir las tecnologías de código abierto más recientes, como scikit-learn, Keras y TensorFlow, este manual proporciona el conocimiento práctico y las técnicas necesarias para crear eficaces aplicaciones de aprendizaje automático y aprendizaje profundo en Python.
El conocimiento y la experiencia únicos de Sebastian Raschka y Vahid Mirjalili presentan los algoritmos de aprendizaje automático y aprendizaje profundo, antes de continuar con temas avanzados en análisis de datos.
Combinan los principios teóricos del aprendizaje automático con un enfoque práctico de codificación para una comprensión completa de la teoría del aprendizaje automático y la implementación con Python.
Aprenderás a:
Explorar y entender los frameworks clave para la ciencia de datos, el aprendizaje automático y el aprendizaje profundo
Formular nuevas preguntas sobre datos con modelos de aprendizaje automático y redes neuronales
Aprovechar el poder de las últimas librerías de código abierto de Python para aprendizaje automático
Dominar la implementación de redes neuronales profundas con la librería de TensorFlow
Incrustar modelos de aprendizaje automáticos en aplicacions web accesibles
Predecir resultados objetivos continuos con análisis de regresión
Descubrir patrones ocultos y estructuras en datos con agrupamientos
Analizar imágenes mediante técnicas de aprendizaje profundo
Profundizar en datos de medios sociales y textuales con el análisis de sentimientos
Python Machine Learning — читать онлайн ознакомительный отрывок
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «Python Machine Learning», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
Los tres tipos de aprendizaje automático
En esta sección, echaremos un vistazo a los tres tipos de aprendizaje automático: aprendizaje supervisado, aprendizaje no supervisado y aprendizaje reforzado. Vamos a aprender las diferencias fundamentales entre los tres tipos distintos de aprendizaje y, mediante ejemplos conceptuales, desarrollaremos una intuición para los ámbitos de problemas prácticos donde pueden ser aplicados:
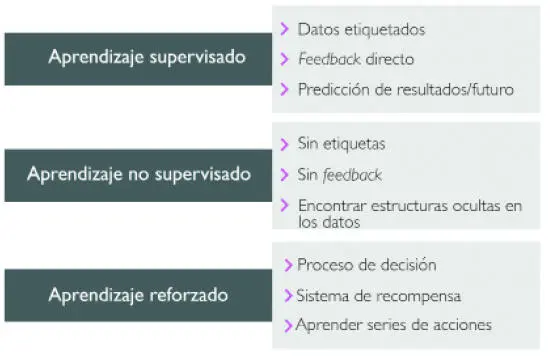
Hacer predicciones sobre el futuro con el aprendizaje supervisado
El objetivo principal del aprendizaje supervisado es aprender un modelo, a partir de datos de entrenamiento etiquetados, que nos permite hacer predicciones sobre datos futuros o no vistos. Aquí, el término supervisado se refiere a un conjunto de muestras donde las señales de salida deseadas (etiquetas) ya se conocen.
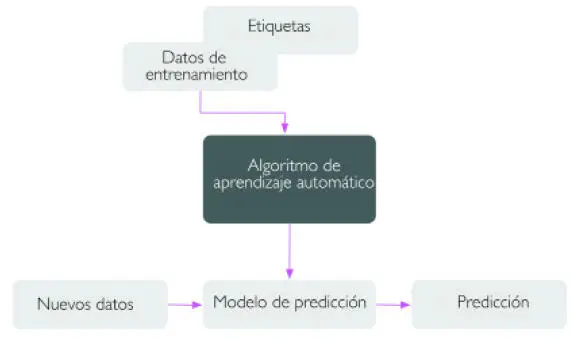
Considerando el ejemplo del filtro de correo no deseado, podemos entrenar un modelo utilizando un algoritmo de aprendizaje automático supervisado en un cuerpo de correos electrónicos etiquetados –correos que están correctamente marcados como «correo no deseado» o como «no correo no deseado»– para predecir si un nuevo correo electrónico pertenece a una u otra categoría. Una tarea de aprendizaje supervisado con etiquetas de clase discretas, como en el ejemplo anterior del filtro de correo no deseado, también se conoce como tarea de clasificación. Otra subcategoría del aprendizaje supervisado es la regresión, donde la señal resultante es un valor continuo.
Clasificación para predecir etiquetas de clase
La clasificación es una subcategoría del aprendizaje supervisado cuyo objetivo es predecir las etiquetas de clase categórica de nuevas instancias, basadas en observaciones pasadas. Estas etiquetas de clase son discretas, valores desordenados que se pueden entender como membresías grupales de las instancias. El ejemplo que hemos mencionado anteriormente de la detección de correo no deseado representa un típico ejemplo de una tarea de clasificación binaria, donde el algoritmo de aprendizaje automático aprende un conjunto de reglas para distinguir entre dos posibles clases: mensajes que son o no son correo no deseado.
Sin embargo, el conjunto de etiquetas de clase no tiene que ser de naturaleza binaria. El modelo predictivo aprendido mediante un algoritmo de aprendizaje supervisado puede asignar cualquier etiqueta de clase que se presente en el conjunto de datos de entrenamiento a una nueva instancia sin etiqueta. Un ejemplo típico de una tarea de clasificación multiclase es el reconocimiento de un carácter manuscrito. Aquí, podemos recoger un conjunto de datos de entrenamiento que consiste en múltiples ejemplos manuscritos de cada letra del alfabeto. Ahora, si un usuario proporciona un nuevo carácter manuscrito desde un dispositivo de entrada, nuestro modelo predictivo será capaz de predecir la letra correcta del alfabeto con cierta precisión. Sin embargo, nuestro sistema de aprendizaje automático no sería capaz de reconocer de forma correcta ningún dígito del cero al nueve, por ejemplo, si no formaran parte de nuestro conjunto de datos de entrenamiento.
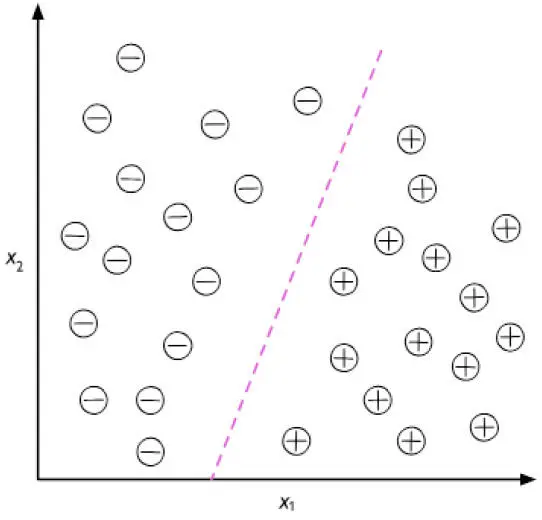
La siguiente figura ilustra el concepto de una tarea de clasificación binaria que da 30 muestras de entrenamiento; 15 de estas muestras están etiquetadas como clase negativa (signo menos) y otras 15 como clase positiva (signo más). En este caso, nuestro conjunto de datos es bidimensional, lo que significa que cada muestra tiene dos valores asociados: 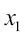 y
y 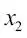 . Ahora, podemos utilizar un algoritmo de aprendizaje automático supervisado para aprender una regla –el límite de decisión está representado con una línea discontinua– que puede separar las dos clases y clasificar nuevos datos dentro de cada categoría dados sus valores de y :
. Ahora, podemos utilizar un algoritmo de aprendizaje automático supervisado para aprender una regla –el límite de decisión está representado con una línea discontinua– que puede separar las dos clases y clasificar nuevos datos dentro de cada categoría dados sus valores de y :
Regresión para predecir resultados continuos
En la sección anterior hemos aprendido que la tarea de clasificación consiste en asignar etiquetas categóricas y sin orden a instancias. Un segundo tipo de aprendizaje supervisado es la predicción de resultados continuos, también conocida como análisis de regresión. En el análisis de regresión, tenemos un número de variables predictoras (explicativas) y una variable de respuesta continua (resultado o destino), y tenemos que encontrar una relación entre estas variables que nos permita predecir un resultado.
Por ejemplo, supongamos que queremos predecir los resultados del examen de selectividad de matemáticas de nuestros alumnos. Si existe una relación entre el tiempo que han pasado estudiando para la prueba y los resultados finales, podríamos utilizarla como dato de entrenamiento para aprender un modelo que utilice el tiempo de estudio para predecir los resultados de la prueba de futuros estudiantes que deseen pasar este examen.
 |
 |
El término regresión fue ideado por Francis Galton en su artículo Regression towards Mediocrity in Hereditary Stature [Regresión hacia la mediocridad en estatura hereditaria] en 1886. Galton describió el fenómeno biológico según el cual la variación de altura en una población no aumenta con el tiempo. Él observó que la altura de los padres no pasa a los hijos, pero que, en cambio, la altura de los hijos está retrocediendo hacia la media de la población. |  |
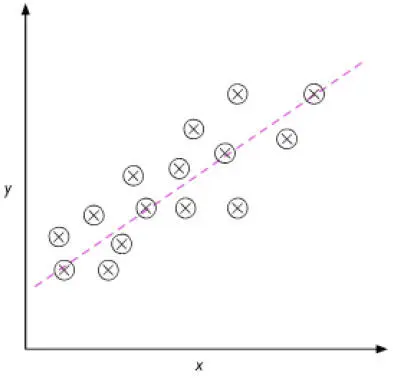
La siguiente figura ilustra el concepto de regresión lineal. Dada una variable predictora x y una variable de respuesta y, aplicamos una línea fina a este dato, que minimiza la distancia –normalmente, la distancia cuadrada de promedio– entre los puntos de muestra y la línea aplicada. Ahora podemos utilizar la intersección y la pendiente aprendidas de este dato para predecir la variable de resultado del nuevo dato:
Resolver problemas interactivos con aprendizaje reforzado
Otro tipo de aprendizaje automático es el aprendizaje reforzado. En este tipo de aprendizaje, el objetivo es desarrollar un sistema (agente) que mejore su rendimiento basado en interacciones con el entorno. Como la información sobre el estado actual del entorno normalmente también incluye una señal de recompensa, podemos pensar en el aprendizaje reforzado como un campo relacionado con el aprendizaje supervisado. Sin embargo, en el aprendizaje reforzado este feedback no es el valor o la etiqueta correctos sobre el terreno, sino una medida de cómo ha sido medida la acción por parte de una función de recompensa. A través de su interacción con el entorno, un agente puede utilizar el aprendizaje reforzado para aprender una serie de acciones que maximicen esta recompensa mediante un enfoque experimental de ensayo-error o una planificación deliberativa.
Читать дальшеИнтервал:
Закладка:
Похожие книги на «Python Machine Learning»
Представляем Вашему вниманию похожие книги на «Python Machine Learning» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.












Обсуждение, отзывы о книге «Python Machine Learning» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.