Pedro Domingos - The Master Algorithm - How the Quest for the Ultimate Learning Machine Will Remake Our World
Здесь есть возможность читать онлайн «Pedro Domingos - The Master Algorithm - How the Quest for the Ultimate Learning Machine Will Remake Our World» весь текст электронной книги совершенно бесплатно (целиком полную версию без сокращений). В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Жанр: Прочая околокомпьтерная литература, на английском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.

- Название:The Master Algorithm: How the Quest for the Ultimate Learning Machine Will Remake Our World
- Автор:
- Жанр:
- Год:неизвестен
- ISBN:нет данных
- Рейтинг книги:4 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
The Master Algorithm: How the Quest for the Ultimate Learning Machine Will Remake Our World: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «The Master Algorithm: How the Quest for the Ultimate Learning Machine Will Remake Our World»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
Machine learning is the automation of discovery-the scientific method on steroids-that enables intelligent robots and computers to program themselves. No field of science today is more important yet more shrouded in mystery. Pedro Domingos, one of the field’s leading lights, lifts the veil for the first time to give us a peek inside the learning machines that power Google, Amazon, and your smartphone. He charts a course through machine learning’s five major schools of thought, showing how they turn ideas from neuroscience, evolution, psychology, physics, and statistics into algorithms ready to serve you. Step by step, he assembles a blueprint for the future universal learner-the Master Algorithm-and discusses what it means for you, and for the future of business, science, and society.
If data-ism is today’s rising philosophy, this book will be its bible. The quest for universal learning is one of the most significant, fascinating, and revolutionary intellectual developments of all time. A groundbreaking book, The Master Algorithm is the essential guide for anyone and everyone wanting to understand not just how the revolution will happen, but how to be at its forefront.
The Master Algorithm: How the Quest for the Ultimate Learning Machine Will Remake Our World — читать онлайн бесплатно полную книгу (весь текст) целиком
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «The Master Algorithm: How the Quest for the Ultimate Learning Machine Will Remake Our World», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
Imagine for a moment trying to pull off such a stunt. You sneak into an absent doctor’s office, and before long a patient comes in and tells you all his symptoms. Now you have to diagnose him, except you know nothing about medicine. All you have is a cabinet full of patient files: their symptoms, diagnoses, treatments undergone, and so on. What do you do? The easiest way out is to look in the files for the patient whose symptoms most closely resemble your current one’s and make the same diagnosis. If your bedside manner is as convincing as Abagnale’s, that might just do the trick. The same idea applies well beyond medicine. If you’re a young president faced with a world crisis, as Kennedy was when a US spy plane revealed Soviet nuclear missiles being deployed in Cuba, chances are there’s no script ready to follow. Instead, you look for historical analogs of the current situation and try to learn from them. The Joint Chiefs of Staff urged an attack on Cuba, but Kennedy, having just read The Guns of August , a best-selling account of the outbreak of World War I, was keenly aware of how easily that could escalate into all-out war. So he opted for a naval blockade instead, perhaps saving the world from nuclear war.
Analogy was the spark that ignited many of history’s greatest scientific advances. The theory of natural selection was born when Darwin, on reading Malthus’s Essay on Population , was struck by the parallels between the struggle for survival in the economy and in nature. Bohr’s model of the atom arose from seeing it as a miniature solar system, with electrons as the planets and the nucleus as the sun. Kekulé discovered the ring shape of the benzene molecule after daydreaming of a snake eating its own tail.
Analogical reasoning has a distinguished intellectual pedigree. Aristotle expressed it in his law of similarity: if two things are similar, the thought of one will tend to trigger the thought of the other. Empiricists like Locke and Hume followed suit. Truth, said Nietzche, is a mobile army of metaphors. Kant was also a fan. William James believed that “this sense of sameness is the very keel and backbone of our thinking.” Some contemporary psychologists even argue that human cognition in its entirety is a fabric of analogies. We rely on it to find our way around a new town and to understand expressions like “see the light” and “stand tall.” Teenagers who insert “like” into every sentence they say would probably, like, agree that analogy is important, dude.
Given all this, it’s not surprising that analogy plays a prominent role in machine learning. It got off to a slow start, though, and was initially overshadowed by neural networks. Its first algorithmic incarnation appeared in an obscure technical report written in 1951 by two Berkeley statisticians, Evelyn Fix and Joe Hodges, and was not published in a mainstream journal until decades later. But in the meantime, other papers on Fix and Hodges’s algorithm started to appear and then to multiply until it was one of the most researched in all of computer science. The nearest-neighbor algorithm, as it’s called, is the first stop on our tour of analogy-based learning. The second is support vector machines, an idea that took machine learning by storm around the turn of the millennium and was only recently overshadowed by deep learning. The third and last is full-blown analogical reasoning, which has been a staple of psychology and AI for several decades, and a background theme in machine learning for nearly as long.
The analogizers are the least cohesive of the five tribes. Unlike the others, which have a strong identity and common ideals, the analogizers are more of a loose collection of researchers, united only by their reliance on similarity judgments as the basis for learning. Some, like the support vector machine folks, might even object to being brought under such an umbrella. But it’s raining deep models outside, and I think they would benefit greatly from making common cause. Similarity is one of the central ideas in machine learning, and the analogizers in all their guises are its keepers. Perhaps in a future decade, machine learning will be dominated by deep analogy, combining in one algorithm the efficiency of nearest-neighbor, the mathematical sophistication of support vector machines, and the power and flexibility of analogical reasoning. (There, I just gave away one of my secret research projects.)
Match me if you can
Nearest-neighbor is the simplest and fastest learning algorithm ever invented. In fact, you could even say it’s the fastest algorithm of any kind that could ever be invented. It consists of doing exactly nothing, and therefore takes zero time to run. Can’t beat that. If you want to learn to recognize faces and have a vast database of images labeled face/not face, just let it sit there. Don’t worry, be happy. Without knowing it, those images already implicitly form a model of what a face is. Suppose you’re Facebook and you want to automatically identify faces in photos people upload as a prelude to tagging them with their friends’ names. It’s nice to not have to do anything, given that Facebook users upload upward of three hundred million photos per day. Applying any of the learners we’ve seen so far to them, with the possible exception of Naïve Bayes, would take a truckload of computers. And Naïve Bayes is not smart enough to recognize faces.
Of course, there’s a price to pay, and the price comes at test time. Jane User has just uploaded a new picture. Is it a face? Nearest-neighbor’s answer is: find the picture most similar to it in Facebook’s entire database of labeled photos-its “nearest neighbor”-and if that picture contains a face, so does this one. Simple enough, but now you have to scan through potentially billions of photos in (ideally) a fraction of a second. Like a lazy student who doesn’t bother to study for the test, nearest-neighbor is caught unprepared and has to scramble. But unlike real life, where your mother taught you to never leave until tomorrow what you can do today, in machine learning procrastination can really pay off. In fact, the entire genre of learning that nearest-neighbor is part of is sometimes called “lazy learning,” and in this context there’s nothing pejorative about the term.
The reason lazy learners are a lot smarter than they seem is that their models, although implicit, can in fact be extremely sophisticated. Consider the extreme case where we have only one example of each class. For instance, we’d like to guess where the border between two countries is, but all we know is their capitals’ locations. Most learners would be stumped, but nearest-neighbor happily guesses that the border is a straight line lying halfway between the two cities:

The points on the line are at the same distance from the two capitals; points to the left of the line are closer to Positiville, so nearest-neighbor assumes they’re part of Posistan and vice versa. Of course, it would be a lucky day if that was the exact border, but as an approximation it’s probably a lot better than nothing. It’s when we know a lot of towns on both sides of the border, though, that things get really interesting:
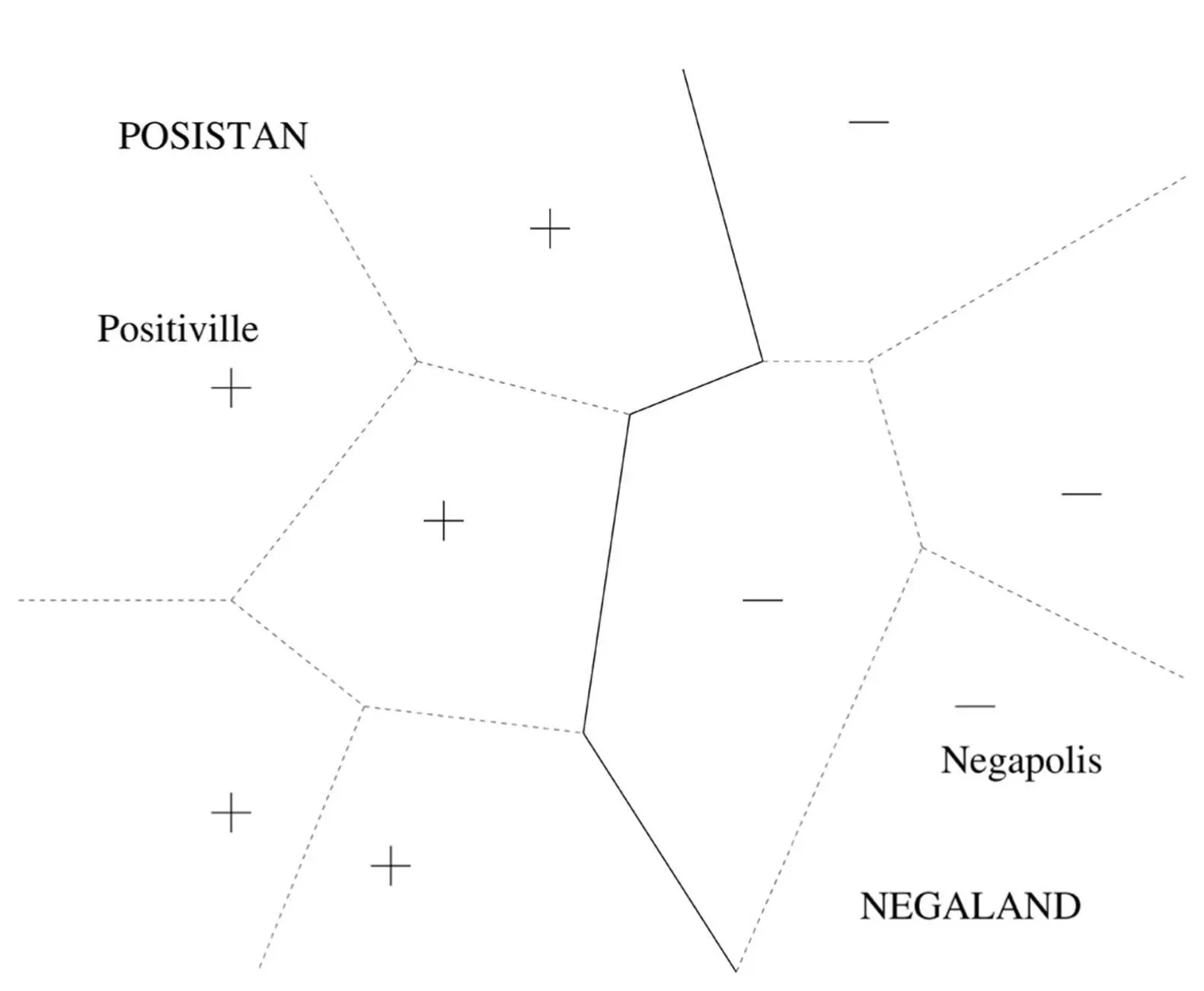
Nearest-neighbor is able to implicitly form a very intricate border, even though all it’s doing is remembering where the towns are and assigning points to countries accordingly! We can think of the “metro area” of a town as all the points that are closer to it than to any other town; the boundaries between metro areas are shown as dashed lines in the diagram. Now Posistan is just the union of the metro areas of all its cities, as is Negaland. In contrast, a decision tree (for example) would only be able to form borders running alternately north-south and east-west, probably a much worse approximation to the real border. Thus, even though decision tree learners are “eager,” trying hard at learning time to figure out where the border lies, “lazy” nearest-neighbor actually wins out.
Читать дальшеИнтервал:
Закладка:
Похожие книги на «The Master Algorithm: How the Quest for the Ultimate Learning Machine Will Remake Our World»
Представляем Вашему вниманию похожие книги на «The Master Algorithm: How the Quest for the Ultimate Learning Machine Will Remake Our World» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.












Обсуждение, отзывы о книге «The Master Algorithm: How the Quest for the Ultimate Learning Machine Will Remake Our World» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.