Тимур Машнин - Технология хранения и обработки больших данных Hadoop
Здесь есть возможность читать онлайн «Тимур Машнин - Технология хранения и обработки больших данных Hadoop» — ознакомительный отрывок электронной книги совершенно бесплатно, а после прочтения отрывка купить полную версию. В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Год выпуска: 2021, ISBN: 2021, Жанр: Прочая околокомпьтерная литература, Программирование, Интернет, на русском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.

- Название:Технология хранения и обработки больших данных Hadoop
- Автор:
- Жанр:
- Год:2021
- ISBN:978-5-532-96881-3
- Рейтинг книги:3 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
Технология хранения и обработки больших данных Hadoop: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «Технология хранения и обработки больших данных Hadoop»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
Технология хранения и обработки больших данных Hadoop — читать онлайн ознакомительный отрывок
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «Технология хранения и обработки больших данных Hadoop», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
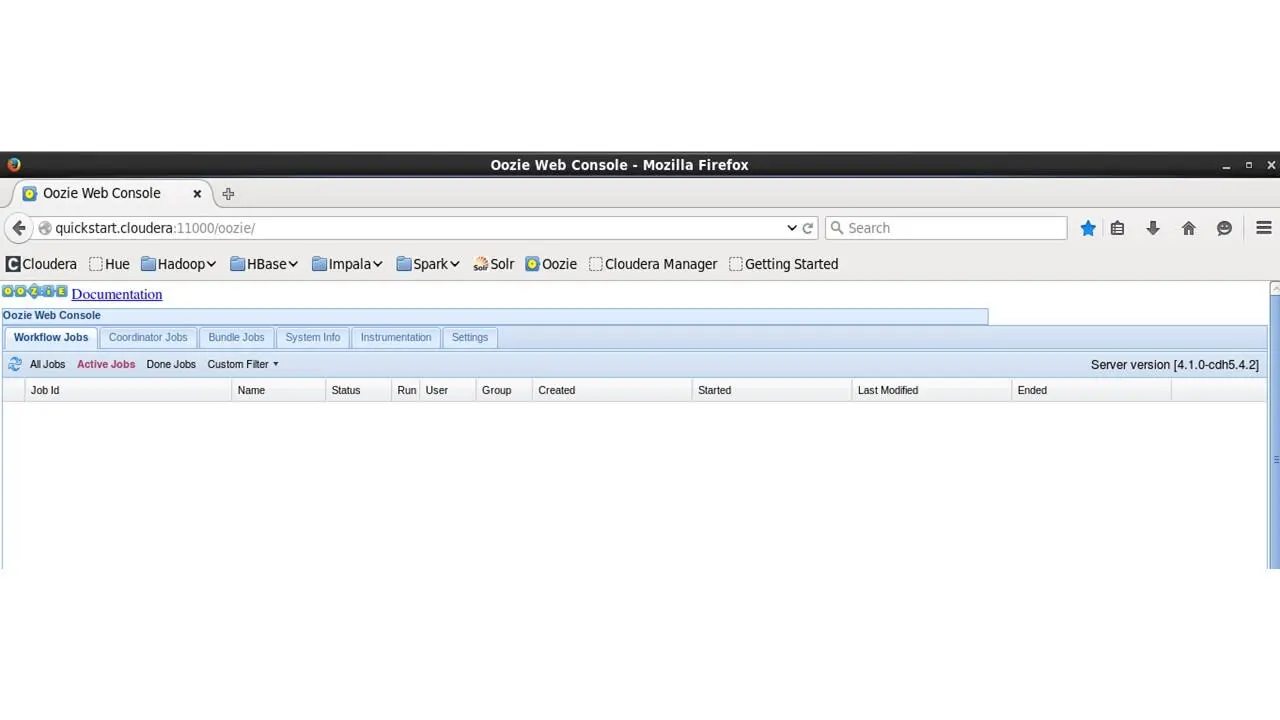
Далее, давайте откроем вкладку Oozie.
Здесь мы можем увидеть количество отправленных заданий, когда они были запущены, и т. д.
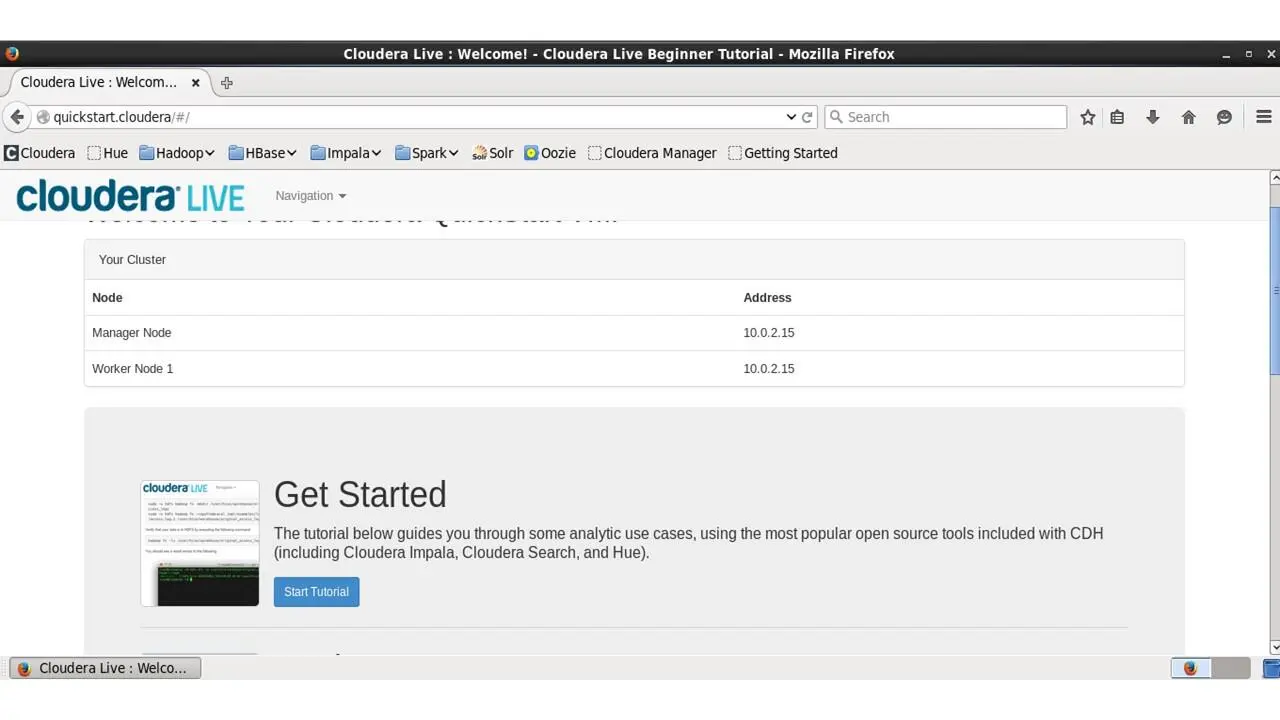
Теперь, давайте вернемся к исходной веб-странице, странице приветствия, и нажмем Start Tutorial.
И этот урок предложит нам введение в стек Cloudera.
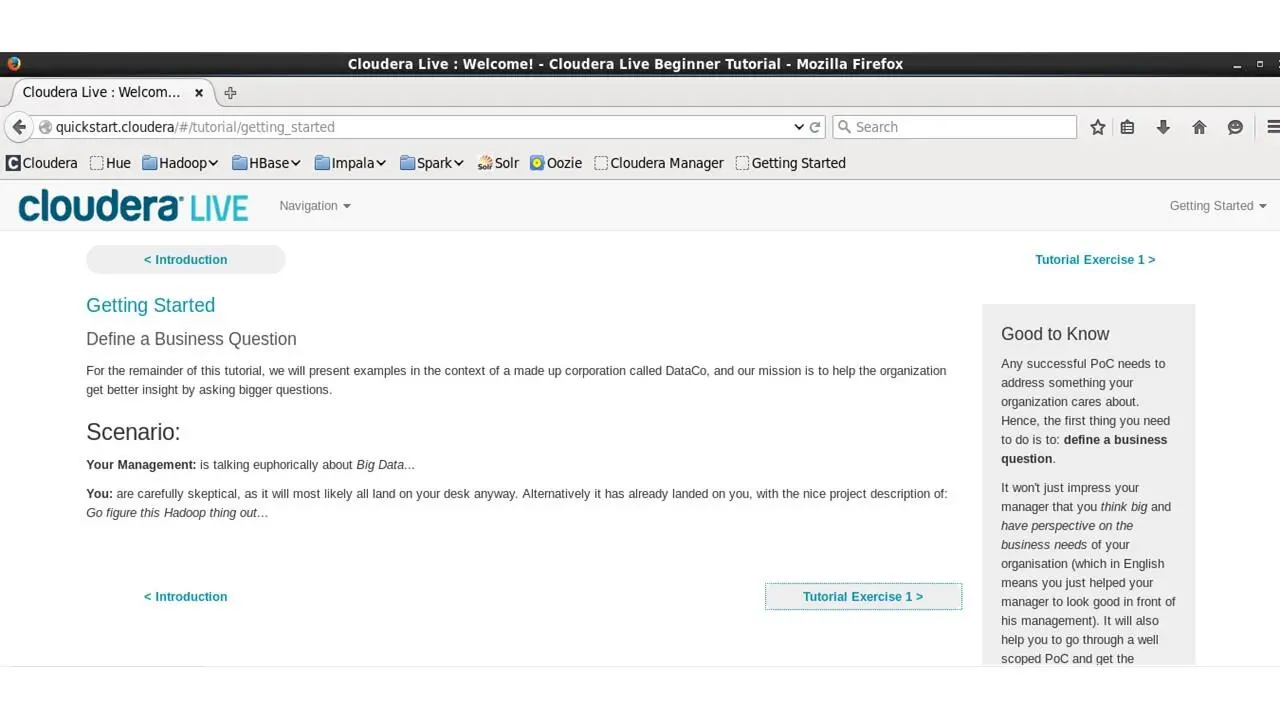
На этой странице говорится, что в этом уроке представлены примеры в контексте созданной корпорации под названием DataCo.
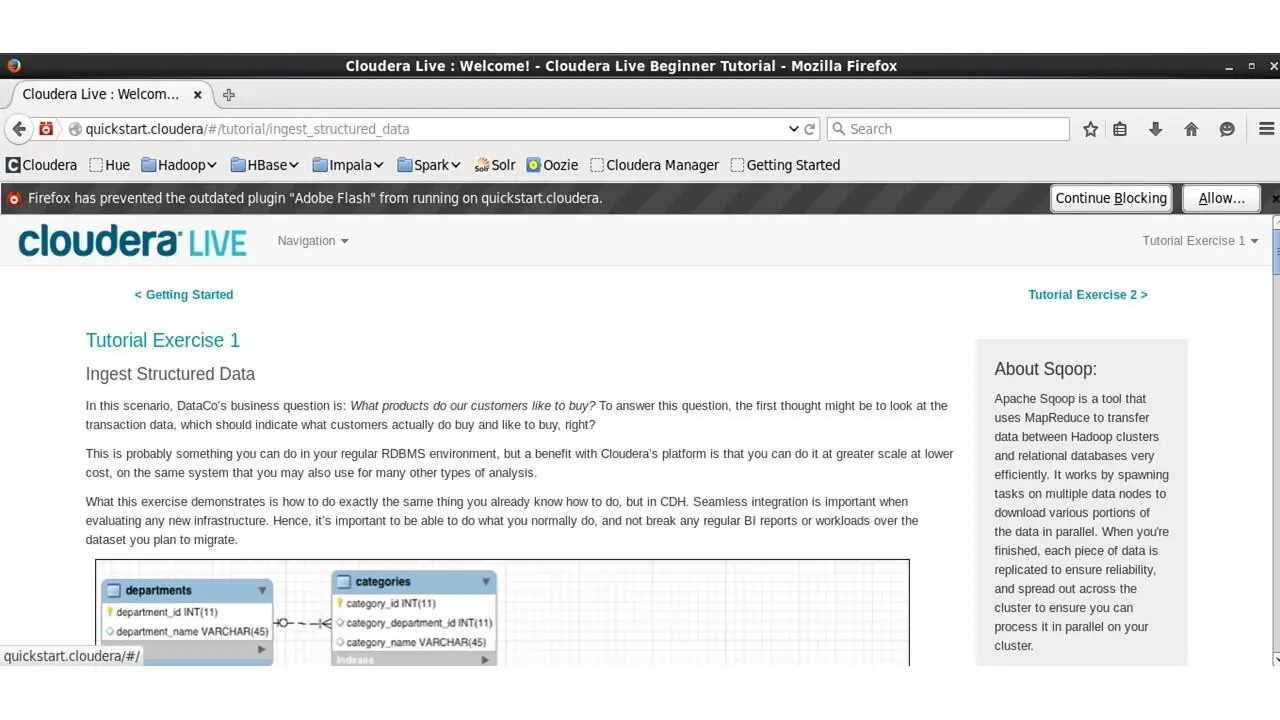
И вопрос первого упражнения – какие продукты любят покупать клиенты корпорации?
Чтобы ответить на этот вопрос, вы можете посмотреть на данные транзакций, которые должны указать, что клиенты покупают.
Вероятно, вы можете это сделать в обычной реляционной базе данных.
Но преимущество платформы Cloudera заключается в том, что вы можете делать это в большем масштабе при меньших затратах.
Здесь сбоку есть информация о Scoop.
Это инструмент, который использует Map Reduce для эффективной передачи данных между кластером Hadoop и реляционной базой данных.
Он работает путем порождения нескольких узлов данных, чтобы загружать различные части данных параллельно.
И по окончании, каждый фрагмент данных будет реплицирован для обеспечения доступности и распределения по кластеру, чтобы вы могли параллельно обрабатывать данные в кластере.
И в платформу Cloudera включены две версии Sqoop.
Sqoop1 – это толстый клиент.
И Scoop2 состоит из центрального сервера и тонкого клиента, который вы можете использовать для подключения к серверу.
Ниже, вы можете посмотреть структуру таблицы данных.
Чтобы проанализировать данные транзакций на платформе Cloudera, нам нужно ввести их в распределенную файловую систему Hadoop (HDFS).
И нам нужен инструмент, который легко переносит структурированные данные из реляционной базы данных в HDFS, сохраняя при этом структуру.
И Apache Sqoop является этим инструментом.
С помощью Sqoop мы можем автоматически загружать данные из MySQL в HDFS, сохраняя при этом структуру.
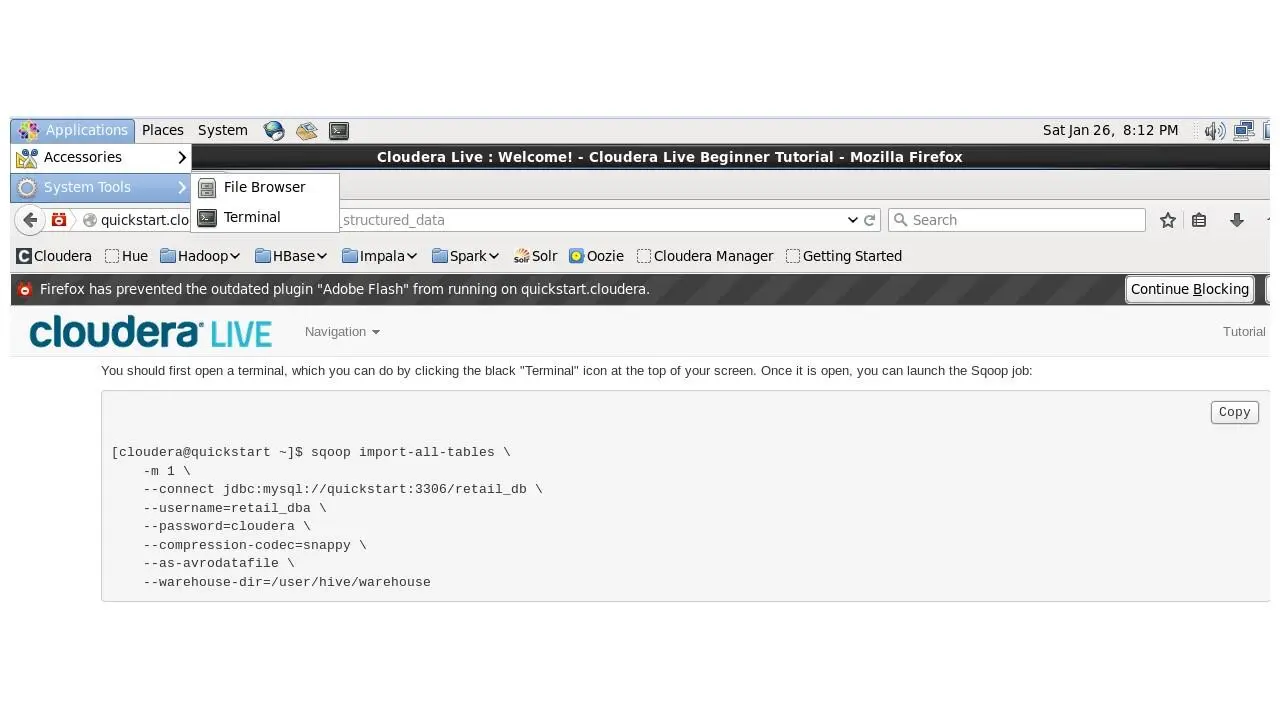
Вверху в меню откроем терминал, и запустим это задание Sqoop.
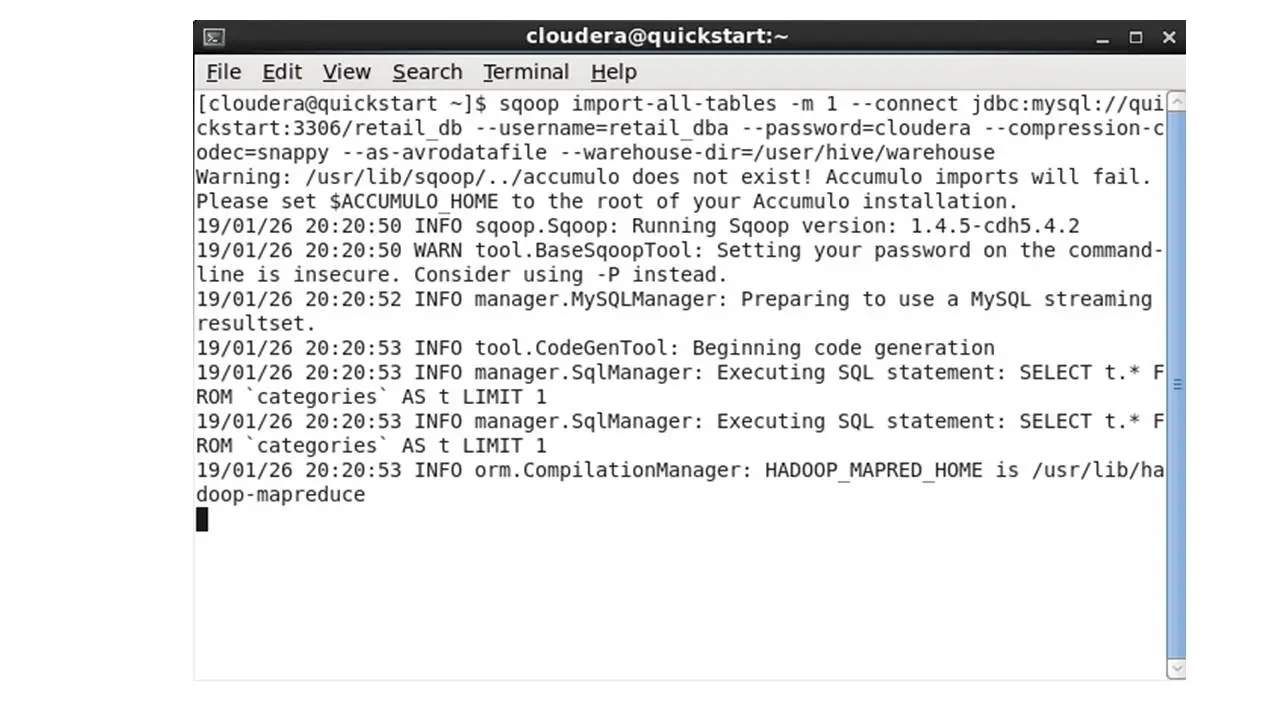
Эта команда запускает задания MapReduce для экспорта данных из базы данных MySQL и размещения этих файлов экспорта в формате Avro в HDFS.
Эта команда также создает схему Avro, чтобы мы могли легко загрузить таблицы Hive для последующего использования в Impala.
Impala – это механизм аналитических запросов.
И Avro – это формат файлов, оптимизированный для Hadoop.
Таким образом, мы скопируем код и запустим команду в терминале.
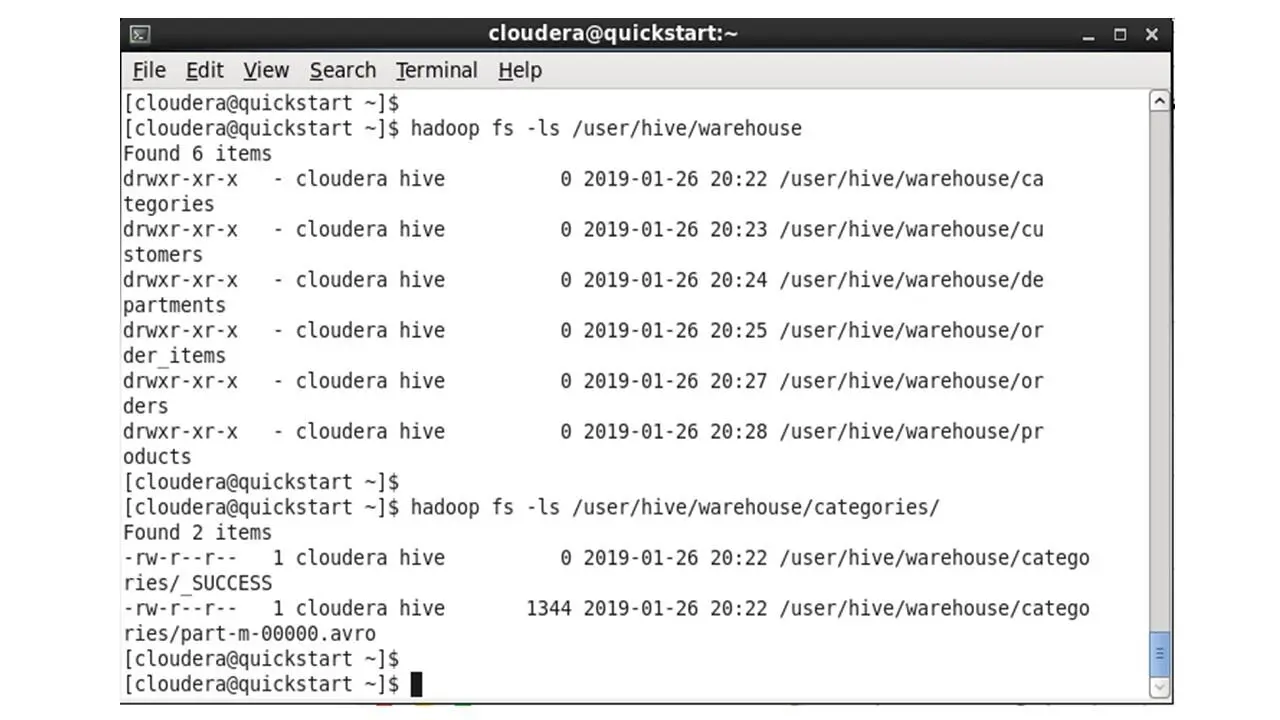
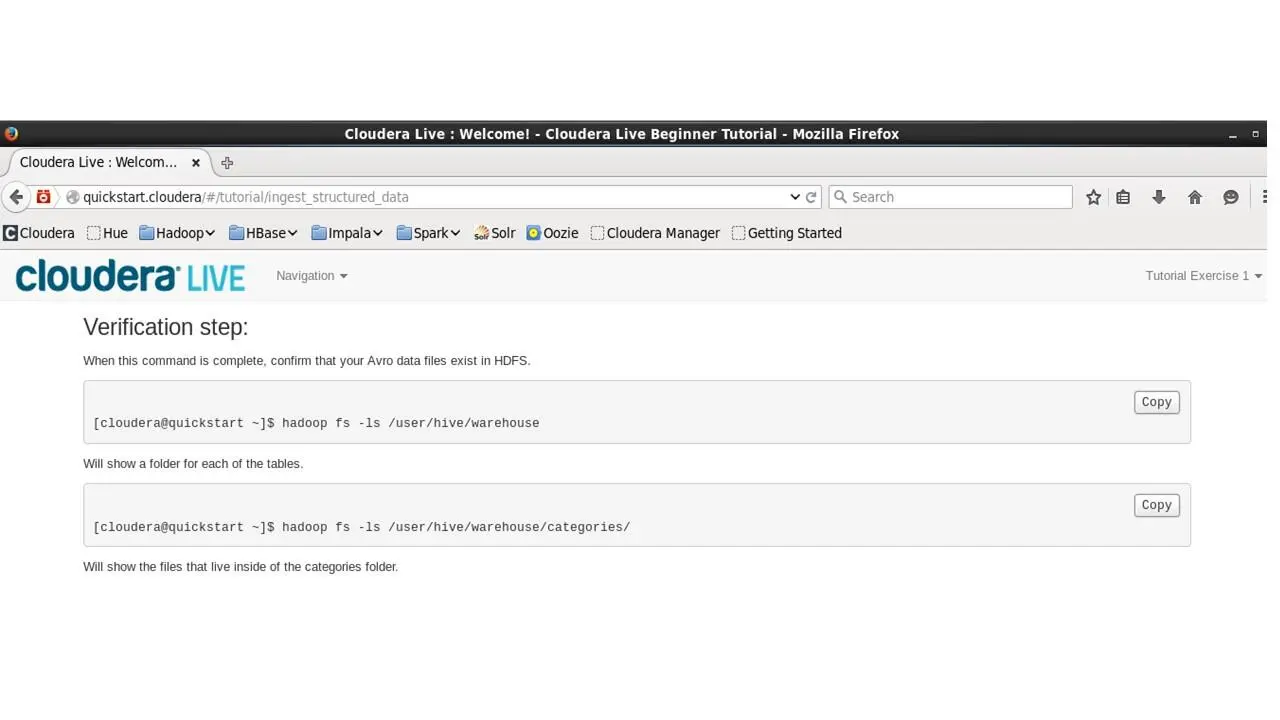
После выполнения задания, чтобы подтвердить, что данные существуют в HDFS, мы скопируем следующие команды в терминал.
Которые покажут папку для каждой из таблиц и покажут файлы в папке категорий.
Инструмент Sqoop также должен был создать файлы схемы для этих данных.
И эта команда должна показать avsc схемы для шести таблиц базы данных.
Таким образом, схемы и данные хранятся в отдельных файлах.
И схема применяется к данным, только когда данные запрашиваются.
И это то, что мы называем схемой на чтение.
Это дает гибкость при запросе данных с помощью SQL.
И это отличие от традиционных баз данных, которые требуют, чтобы у вас была четкая схема, прежде чем вводить в базу какие-либо данные. Здесь мы вводим данные, а уже потом применяем к ним схему.
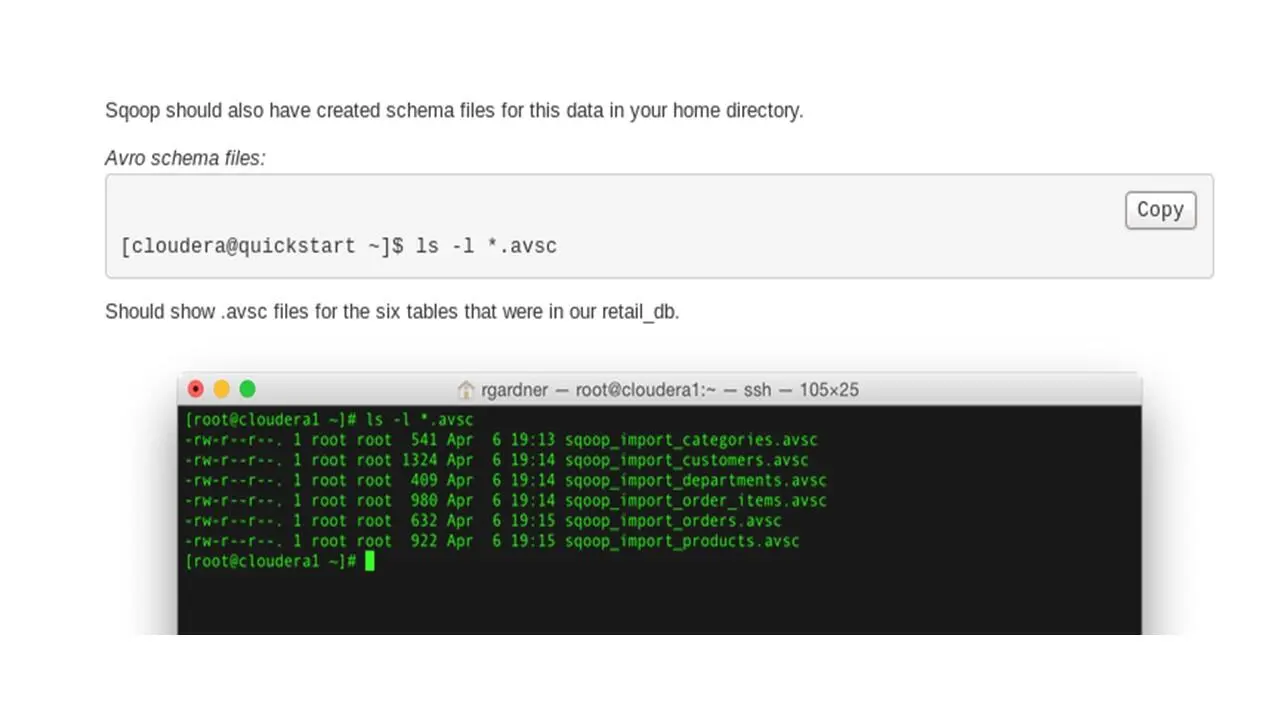
Теперь, так как мы хотим использовать Apache Hive, нам понадобятся файлы схем.
Читать дальшеИнтервал:
Закладка:
Похожие книги на «Технология хранения и обработки больших данных Hadoop»
Представляем Вашему вниманию похожие книги на «Технология хранения и обработки больших данных Hadoop» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.












Обсуждение, отзывы о книге «Технология хранения и обработки больших данных Hadoop» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.