Тимур Машнин - Технология хранения и обработки больших данных Hadoop
Здесь есть возможность читать онлайн «Тимур Машнин - Технология хранения и обработки больших данных Hadoop» — ознакомительный отрывок электронной книги совершенно бесплатно, а после прочтения отрывка купить полную версию. В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Год выпуска: 2021, ISBN: 2021, Жанр: Прочая околокомпьтерная литература, Программирование, Интернет, на русском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.

- Название:Технология хранения и обработки больших данных Hadoop
- Автор:
- Жанр:
- Год:2021
- ISBN:978-5-532-96881-3
- Рейтинг книги:3 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
Технология хранения и обработки больших данных Hadoop: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «Технология хранения и обработки больших данных Hadoop»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
Технология хранения и обработки больших данных Hadoop — читать онлайн ознакомительный отрывок
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «Технология хранения и обработки больших данных Hadoop», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
Поэтому с помощью этой команду скопируем их в HDFS, где Hive может легко получить к ним доступ.
Вы могли заметить, что мы импортировали данные в каталоги Hive.
И Hive и Impala читают данные из файла в HDFS, и они даже обмениваются метаданными о таблицах.
Отличие состоит в том, что Hive выполняет запросы, компилируя их в задания MapReduce.
В то время как Impala является механизмом системы параллельных запросов, которые считывают данные непосредственно из самой файловой системы, в более быстром и интерактивном режиме.
Таким образом, мы загрузили данные с помощью Sqoop в HTFS, преобразовав их в формат Avro, и импортировали файлы схем, для их использования при запросе этих данных.
И теперь, давайте перейдем к следующему упражнению.
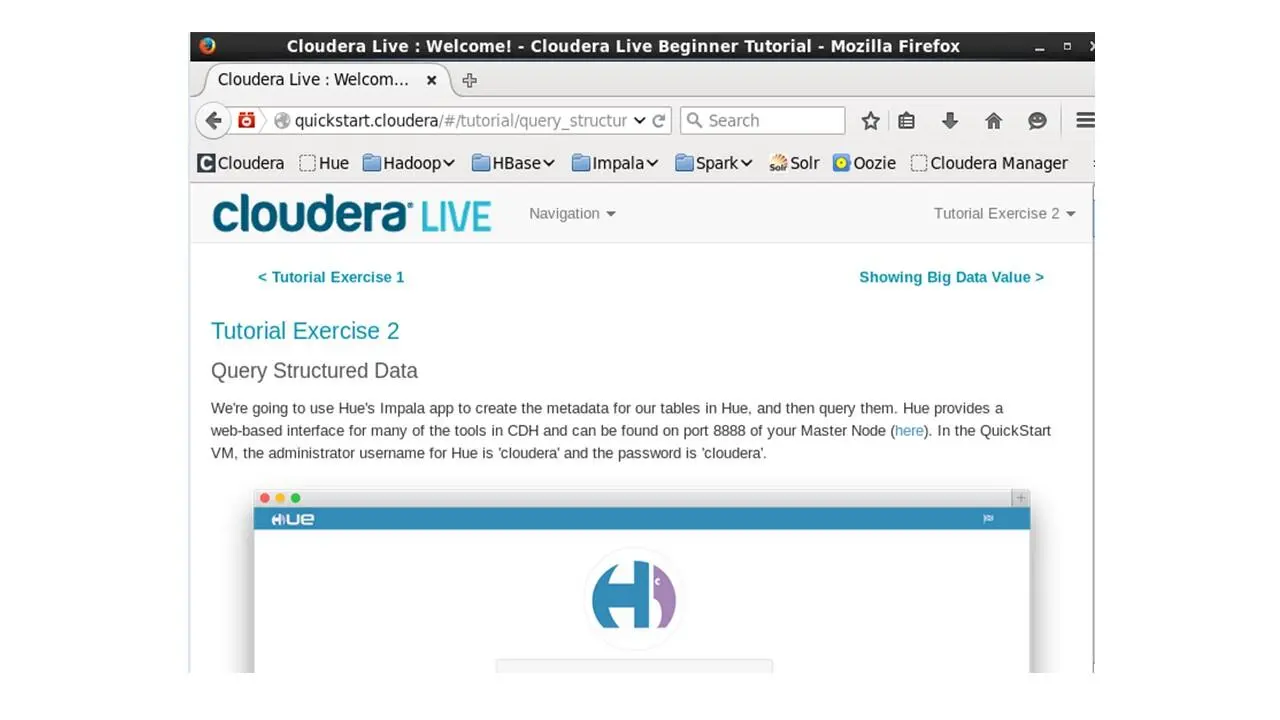
Здесь мы будем использовать Hue, приложение Impala, для создания метаданных для наших таблиц.
Мы создадим эти метаданные, а затем сделаем запрос к нашей таблице используя Hue.
Hue предоставляет веб-интерфейс, который доступен на порту 8888.
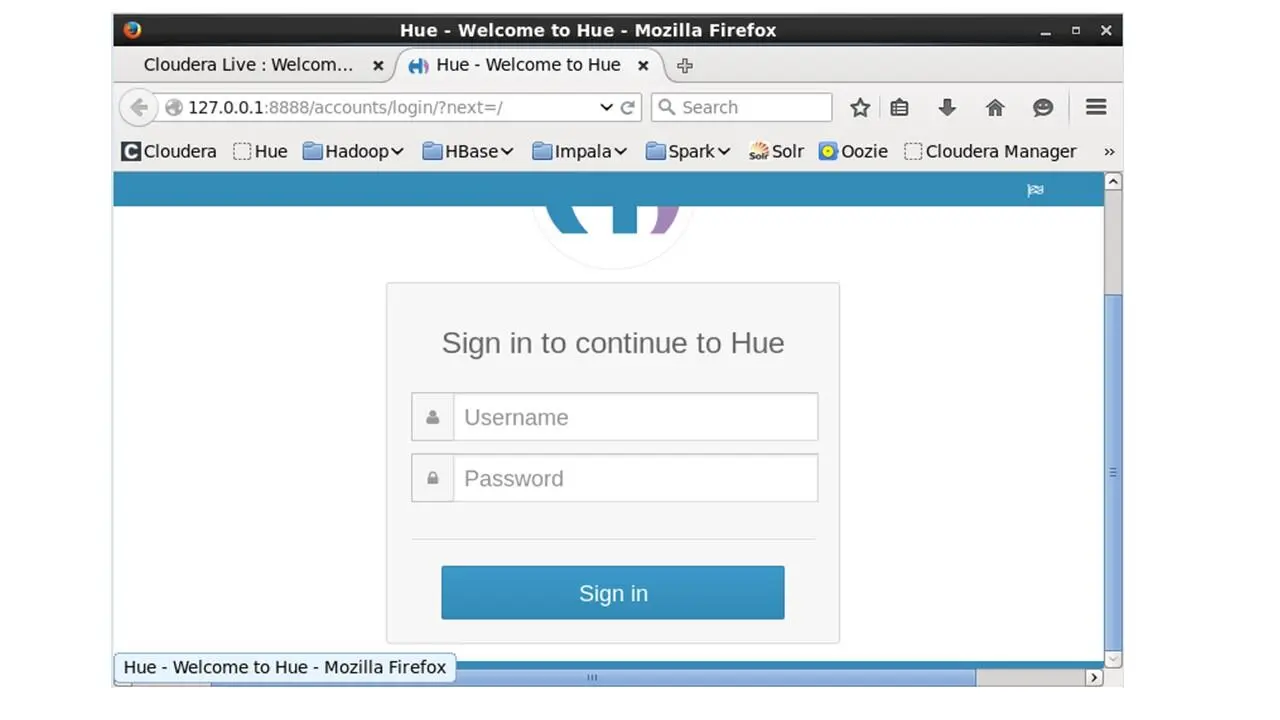
Чтобы войти в Hue, введем сloudera в качестве имени пользователя и пароля.
Далее в меню Query Editors откроем Impala.
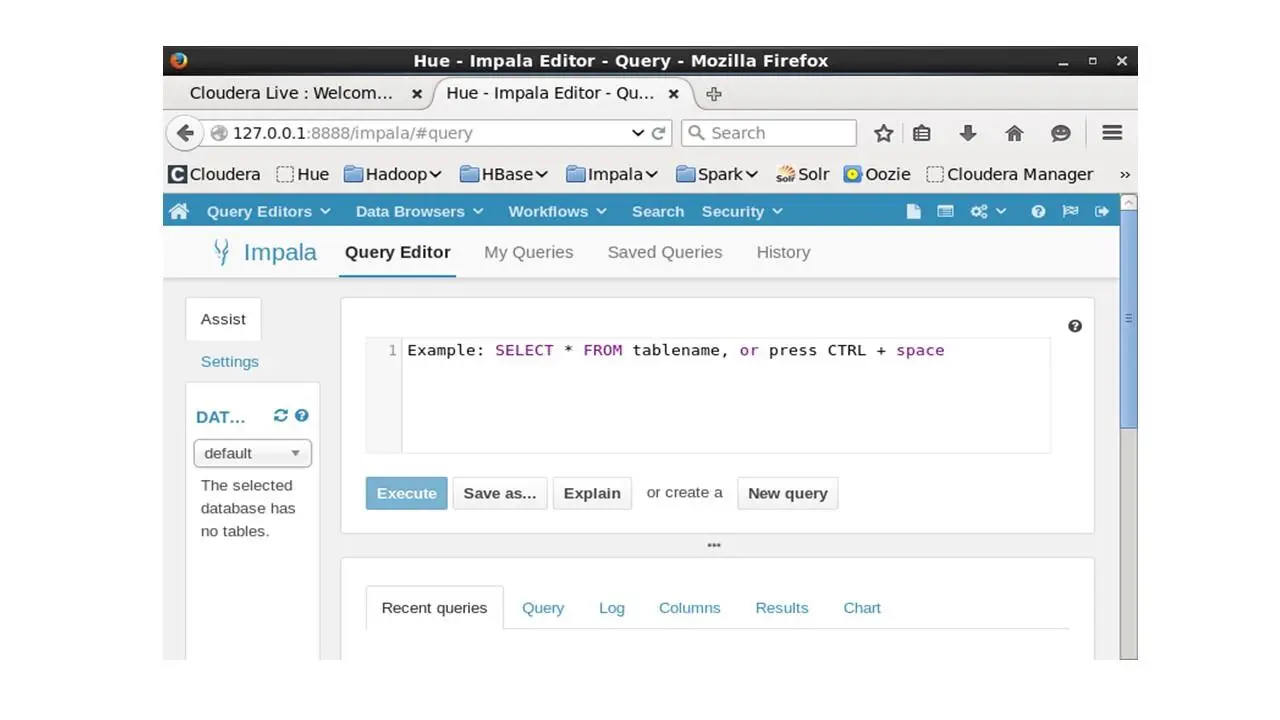
Скопируем и вставим код, который создаст таблицы.
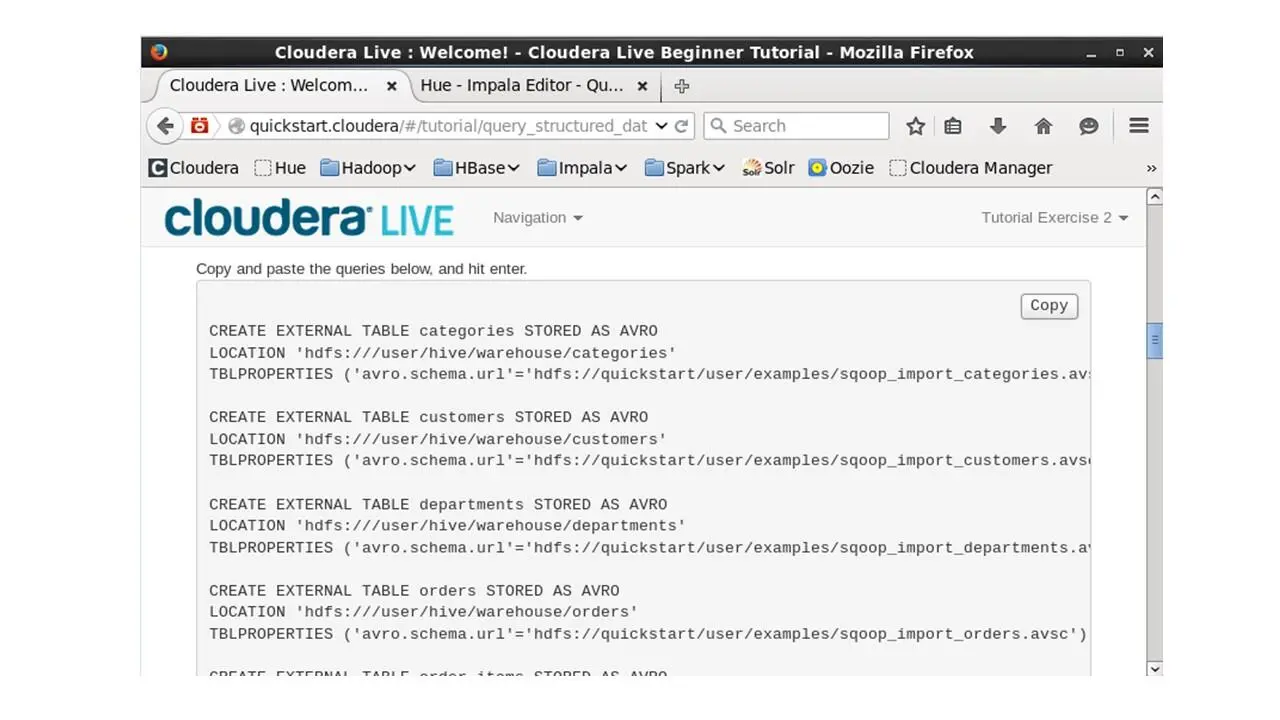
И обновим данные в левой колонке, чтобы увидеть созданные таблицы.
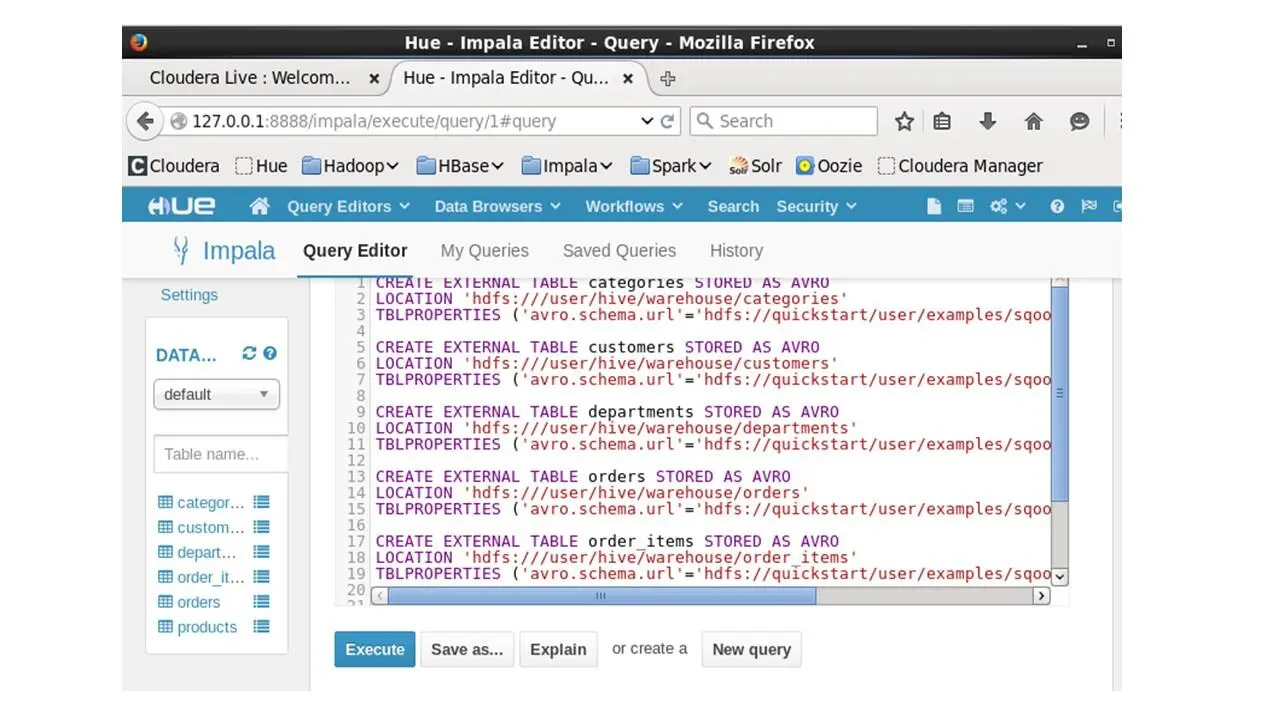
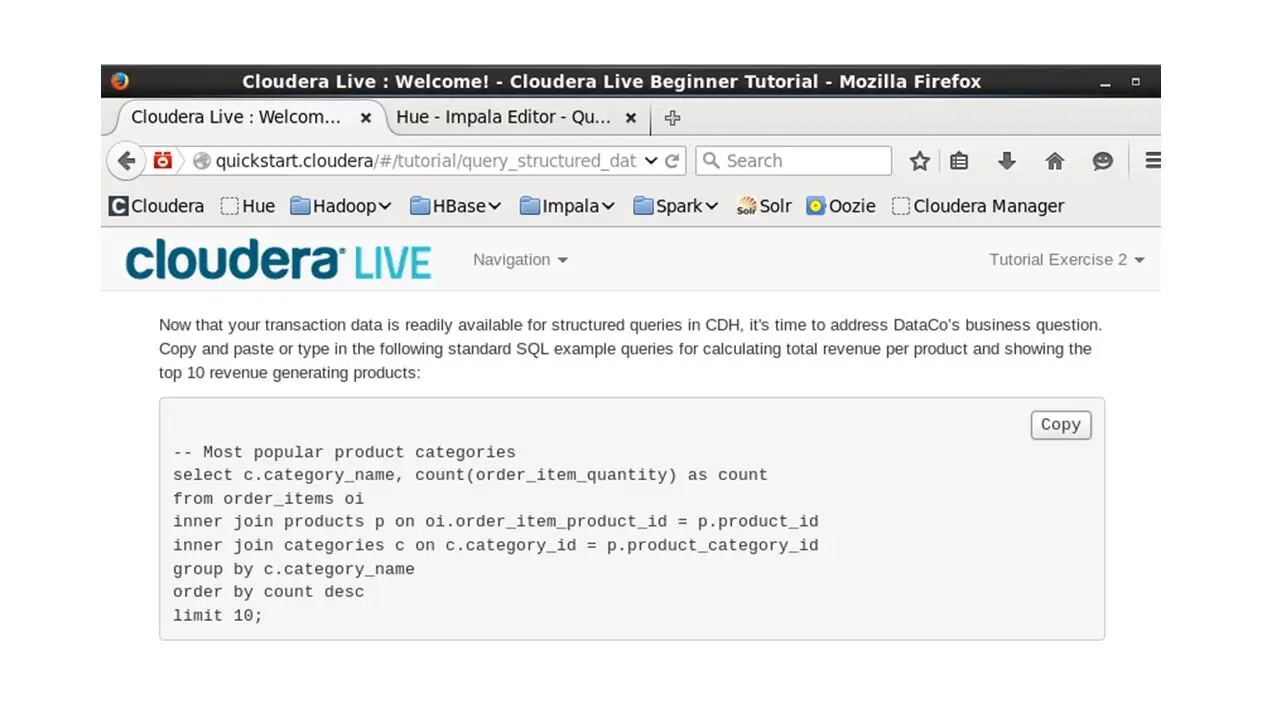
Теперь, когда данные доступны для запросов, мы можем ответить на вопрос, какие продукты покупают клиенты.
Для этого скопируем и вставим SQL запросы для расчета общей выручки по продукту и отображения 10 лучших продуктов, приносящих доход.
После выполнения, в Hue, мы увидим результаты запроса.
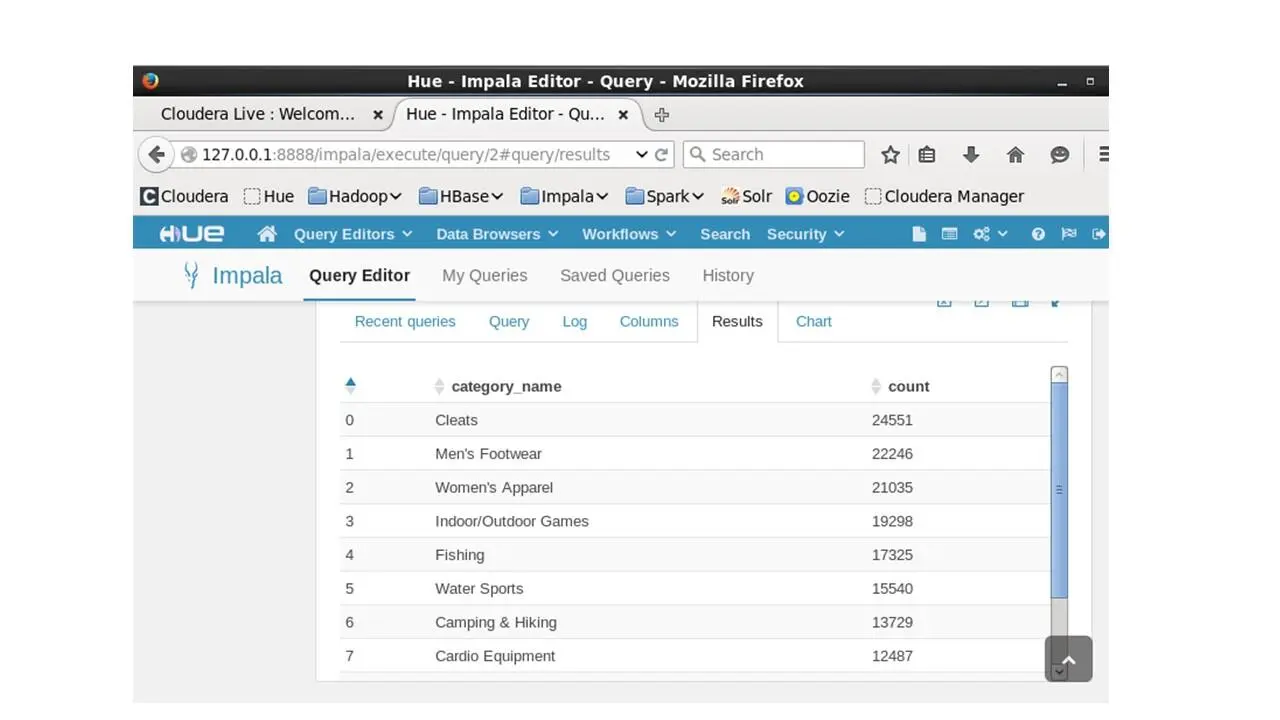
Таким образом мы узнали, как создавать и запрашивать таблицы с помощью Impala.
Теперь, давайте перейдем к следующему уроку.
И далее мы должны посмотреть, какие преимущества дает стек Cloudera по сравнению с традиционными системами.
Здесь мы попытаемся соотнести структурированные данные с неструктурированными данными и сможем ответить на вопрос – являются ли наиболее просматриваемые товары наиболее продаваемыми.
Конец ознакомительного фрагмента.
Текст предоставлен ООО «ЛитРес».
Прочитайте эту книгу целиком, на ЛитРес.
Безопасно оплатить книгу можно банковской картой Visa, MasterCard, Maestro, со счета мобильного телефона, с платежного терминала, в салоне МТС или Связной, через PayPal, WebMoney, Яндекс.Деньги, QIWI Кошелек, бонусными картами или другим удобным Вам способом.
Интервал:
Закладка:
Похожие книги на «Технология хранения и обработки больших данных Hadoop»
Представляем Вашему вниманию похожие книги на «Технология хранения и обработки больших данных Hadoop» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.












Обсуждение, отзывы о книге «Технология хранения и обработки больших данных Hadoop» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.