Тимур Машнин - Введение в технологию Блокчейн
Здесь есть возможность читать онлайн «Тимур Машнин - Введение в технологию Блокчейн» — ознакомительный отрывок электронной книги совершенно бесплатно, а после прочтения отрывка купить полную версию. В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Год выпуска: 2021, Жанр: Интернет, Прочая околокомпьтерная литература, Справочники, на русском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.

- Название:Введение в технологию Блокчейн
- Автор:
- Жанр:
- Год:2021
- ISBN:нет данных
- Рейтинг книги:3 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
Введение в технологию Блокчейн: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «Введение в технологию Блокчейн»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
Введение в технологию Блокчейн — читать онлайн ознакомительный отрывок
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «Введение в технологию Блокчейн», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
Тимур Машнин
Введение в технологию Блокчейн
Введение в криптографию и криптовалюты
Начнем мы свое обсуждение с криптографических хеш-функций. Мы поговорим о том, что они собой представляют, и каковы их свойства. А потом мы обсудим их приложения.
Итак, криптографическая хэш-функция является математической функцией. И она обладает рядом свойств.

Прежде всего, хеш-функция может принимать любую строку любого размера как входной параметр. И хеш-функция производит вывод строки фиксированного размера, мы будем использовать 256 бит, потому что это делает биткойн.
И хеш-функция должна быть эффективно вычисляемой, обрабатывая заданную строку за разумный промежуток времени.
Также хэш-функция должна быть криптографически безопасна.
В частности, функция не должна иметь коллизий или конфликтов, она должна иметь свойство скрытия, и она должна быть головоломкой.
Первое свойство, которое нам нужно иметь для криптографической хеш-функции это то, что она не содержит конфликтов.
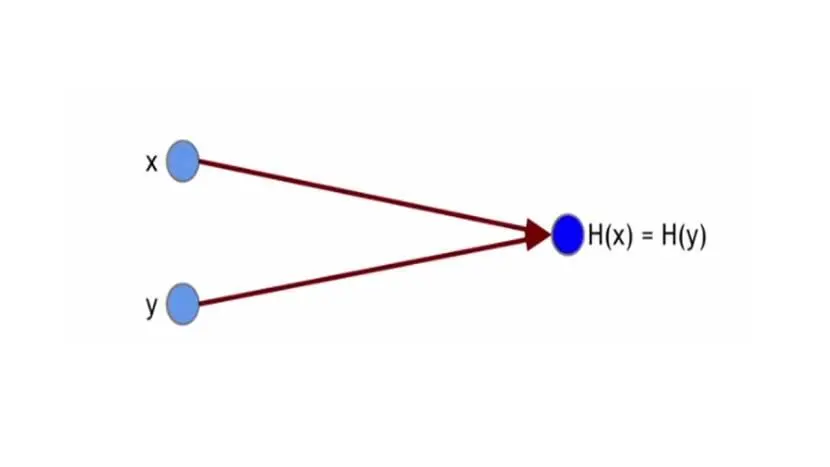
И это означает, что нельзя найти две разные строки с одинаковой хэш-функцией.
Теоретически коллизии существуют, так как на вход вы берете строку любой длины, а на выходе получаете строку 256 бит.
Вопрос в том, могут ли эти коллизии быть найденными обычными людьми, использующими обычные компьютеры?
С точки зрения вероятности, если взять 2 в 130 степени случайно выбранных входных строк, то с вероятностью 99.8 %, по крайней мере, две из них будут конфликтовать, независимо от используемой хэш функции.
Но, конечно, проблема в том, что вы должны вычислить хэш функцию 2 в 130 степени раз.
И это, конечно, астрономическое число.
Не существует хеш функции, для которой было бы доказано, что она свободна от конфликтов.
Просто эти конфликты трудно найти, и мы принимаем то, что мы используем хэш функцию, свободную от конфликтов.
Если мы можем предположить, что у нас есть хеш-функция, свободная от коллизий, тогда мы можем использовать результаты этой хэш-функции как дайджест сообщений.
И я имею в виду следующее.
Если мы знаем, что x и y имеют одинаковый хеш, тогда можно с уверенностью предположить, что x и y одинаковы. И это позволяет нам использовать хэши как своего рода дайджест сообщений.
Предположим, например, что у нас есть большой файл.
И мы хотели бы уметь распознавать, будет ли другой файл таким же, как этот файл.
Один из способов сделать это, это сохранить весь большой файл. И затем, когда мы получим другой файл, просто сравнить их.
Но поскольку у нас есть хэш функция и хэши файлов, которые, как мы считаем, свободны от конфликтов, более эффективно просто запомнить хэш исходного файла.
Затем, если кто-то показывает нам новый файл и утверждает, что это то же самое, мы можем вычислить хэш этого нового файла и сравнить хеши.
Если хеши одинаковы, мы делаем вывод, что файлы одинаковые.
И это дает нам очень эффективный способ запомнить то, что мы видели раньше, так как хэш невелик, это всего лишь 256 бит, в то время как исходный файл может быть очень большим.
Второе свойство, которое мы хотим от хэш-функции, состоит в том, что она является скрывающей.
Если у нас есть результат хэш-функции, тогда нет никакого способа определить, что из себя представляет вход хэш функции.
Это работает, когда вход хэш функции представляет собой огромный набор различных вариантов, так что нельзя простым перебором, вычисляя хэши, найти соответствие хэша и определенного входа.
Если же у нас набор входных значений небольшой, мы можем решить эту проблему с помощью соединения нашего входного значения со значением, которое было выбрано из очень большого набора значений.
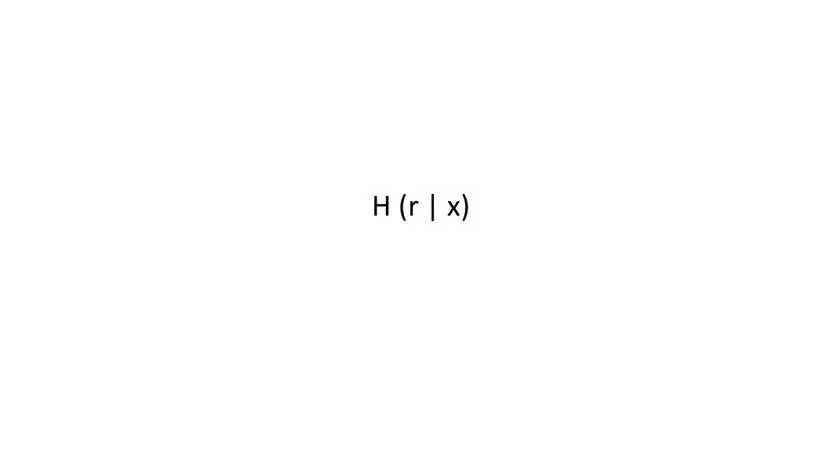
Таким образом, хэш функция H (r | x) означает взять все биты r и поместить после них все биты x.
Если r – случайное значение, выбранное из широкого распределения, то, учитывая H (r | x), невозможно найти x.
Таким образом хэш r соединенного с x, будет скрывать x.
Теперь давайте посмотрим на применение этого скрывающего свойства.
Предположим, что мы берем число, заворачиваем его в конверт, и помещаем его на стол, где каждый может увидеть конверт. Но пока вы не открыли конверт, это число является секретом.
Читать дальшеИнтервал:
Закладка:
Похожие книги на «Введение в технологию Блокчейн»
Представляем Вашему вниманию похожие книги на «Введение в технологию Блокчейн» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.












Обсуждение, отзывы о книге «Введение в технологию Блокчейн» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.