Тимур Машнин - Технология хранения и обработки больших данных Hadoop
Здесь есть возможность читать онлайн «Тимур Машнин - Технология хранения и обработки больших данных Hadoop» — ознакомительный отрывок электронной книги совершенно бесплатно, а после прочтения отрывка купить полную версию. В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Год выпуска: 2021, ISBN: 2021, Жанр: Прочая околокомпьтерная литература, Программирование, Интернет, на русском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.

- Название:Технология хранения и обработки больших данных Hadoop
- Автор:
- Жанр:
- Год:2021
- ISBN:978-5-532-96881-3
- Рейтинг книги:3 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
Технология хранения и обработки больших данных Hadoop: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «Технология хранения и обработки больших данных Hadoop»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
Технология хранения и обработки больших данных Hadoop — читать онлайн ознакомительный отрывок
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «Технология хранения и обработки больших данных Hadoop», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
Это обеспечивает масштабируемую технологию параллельных баз данных на вершине Hadoop.
И это позволяет отправлять SQL-подобные запросы с гораздо более высокими скоростями и с гораздо меньшей задержкой.
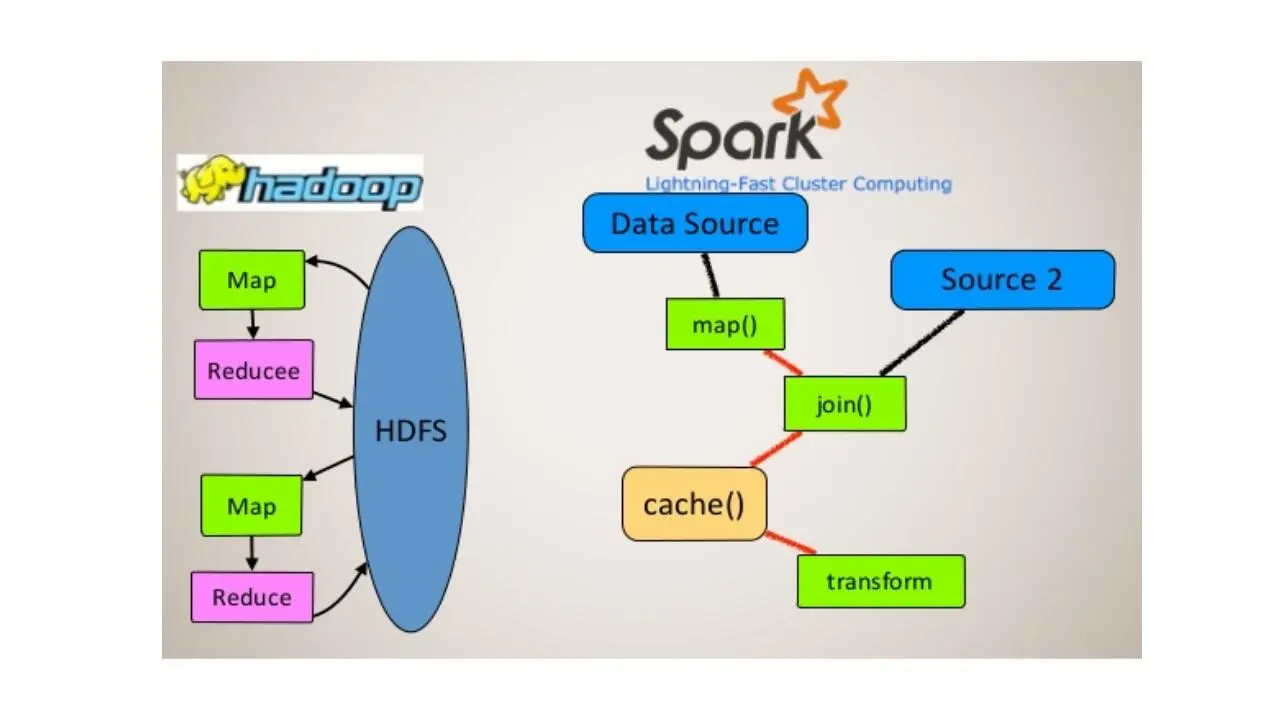
Еще один дополнительный компонент, это Spark.
Хотя Hadoop широко используется для анализа распределенных данных, в настоящее время существует ряд альтернатив, которые предоставляют некоторые интересные преимущества по сравнению с традиционной платформой Hadoop.
И Spark – это одна из таких альтернатив.
Apache Spark – это фреймворк экосистемы Hadoop с открытым исходным кодом для реализации распределённой обработки данных.
В отличие от классического обработчика Hadoop, реализующего двухуровневую концепцию MapReduce с дисковым хранилищем, Spark использует специализированные примитивы для рекуррентной обработки в оперативной памяти, благодаря чему позволяет получать значительный выигрыш в скорости работы для некоторых классов задач, в частности, возможность многократного доступа к загруженным в память пользовательским данным делает библиотеку привлекательной для алгоритмов машинного обучения.
И Spark поддерживает язык Scala, и предоставляет уникальную среду для обработки данных.
Для управления кластерами Spark поддерживает автономные нативные кластеры Spark, или вы можете запустить Spark поверх Hadoop Yarn.
Что касается распределенного хранилища, Spark может взаимодействовать с любой системой хранения, включая HDFS, Amazon S3 или с каким-либо другим пользовательским решением.
Cloudera QuickStart VM

Для начала работы нам нужно скачать виртуальную машину Cloudera, позволяющую ознакомиться со стеком Cloudera Hadoop.
После скачивания и распаковки архива, запустим виртуальную машину.
Для этого в VirtualBox импортируем скачанную конфигурацию ovf.
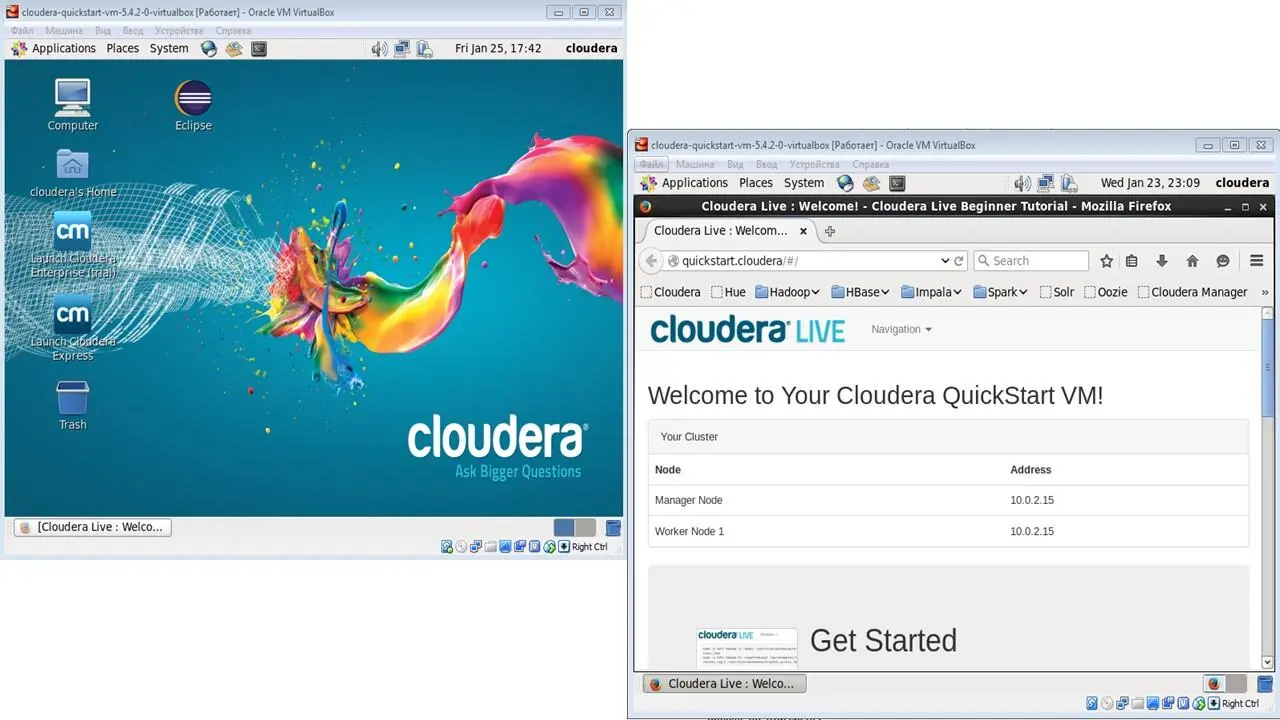
После запуска виртуальной машины Cloudera QuickStart вы увидите рабочий стол и открытый браузер.
И если вы посмотрите на этот браузер, вы увидите, что здесь представлено несколько разных сервисов Cloudera.
Здесь есть Hue, Hadoop, HBase, Impala, Spark, и т. д.
Это все приложения стека Cloudera Hadoop.
Здесь браузер выступает как клиент, для доступа к этим сервисам, запущенным на виртуальной машине, для доступа с помощью URL адреса.
И давайте пройдемся по ним и узнаем, что они нам могут предоставить.
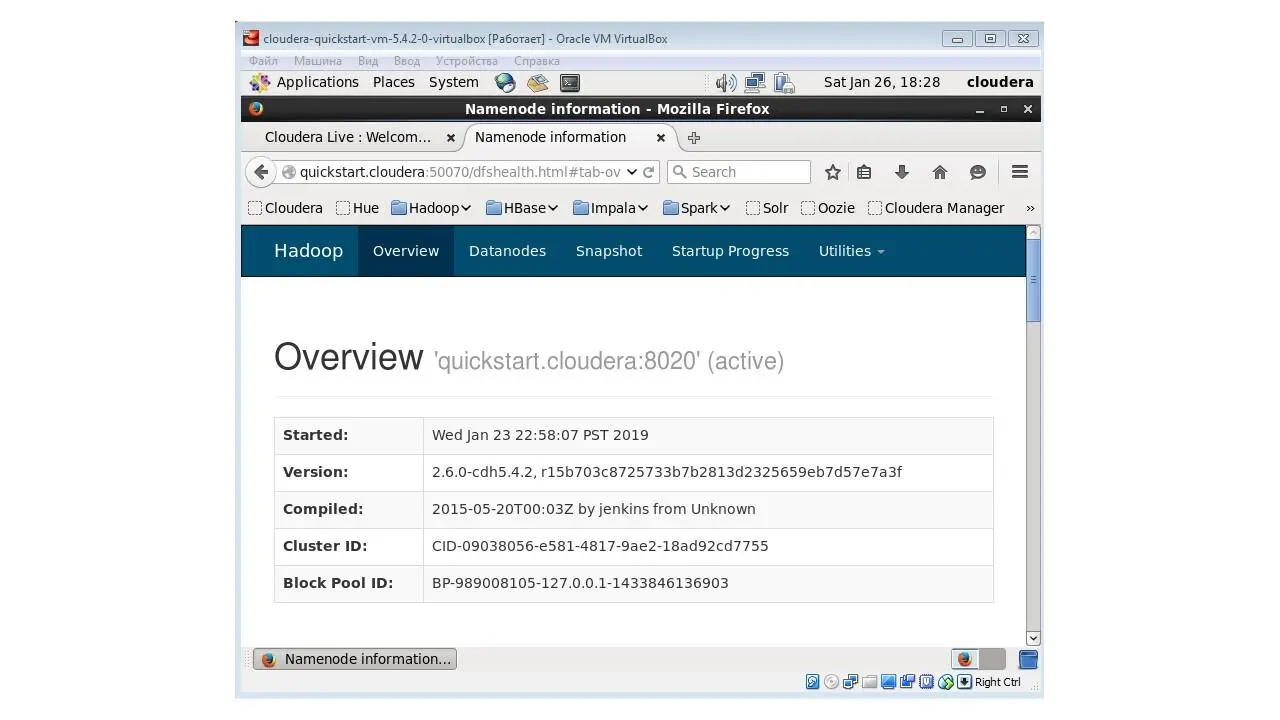
Откроем вкладку Overview NameNode Hadoop.
Здесь мы видим обзор нашего стека Hadoop.
Мы можем видеть, когда произошла инициализация этого стека.
И этот обзор дает нам полную сводку по всем конфигурациям, количеству файлов и т. д.
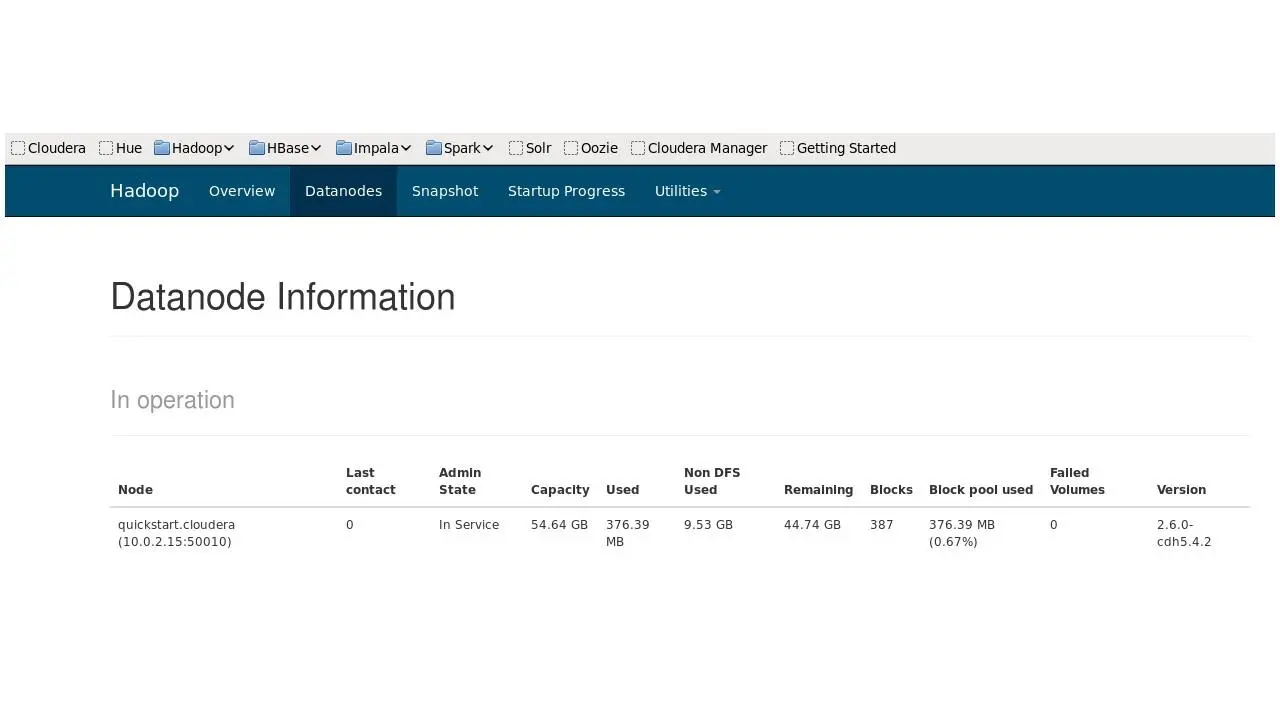
Давайте откроем вкладку Datanodes.
Этот сервис позволяет посмотреть на все имеющиеся у нас Datanodes.
Напомним, что кластер HDFS состоит из одного NameNode, главного сервера, который управляет пространством имен файловой системы и регулирует доступ клиентов к файлам.
И существуют узлы данных Datanodes, обычно по одному на узел кластера, которые управляют хранилищем, подключенным к узлам.
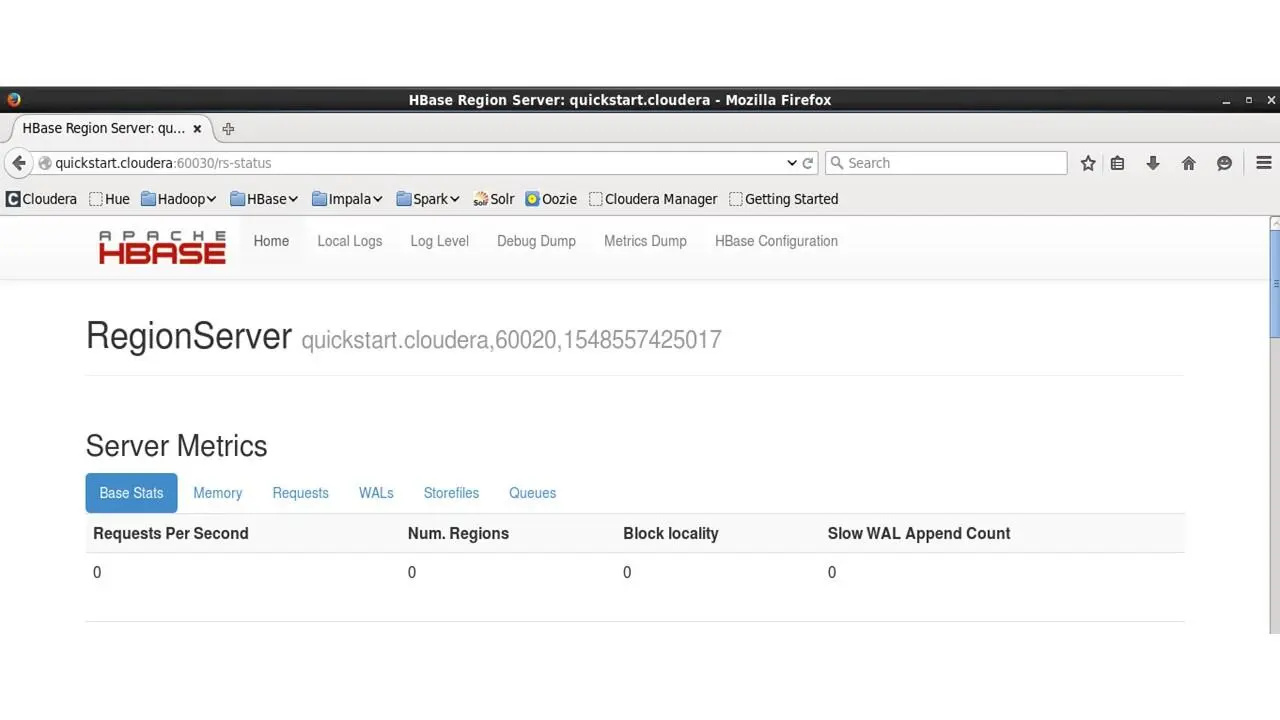
Откроем вкладку RegionServer HBase/
HBase – это столбцовое хранилище данных, которое хранит неструктурированные данные в файловой системе Hadoop.
Здесь показывается количество запросов, которые делаются для чтения и записи в базу данных HBase.
И мы можем видеть все вызовы и задачи, которые были переданы в базу данных.
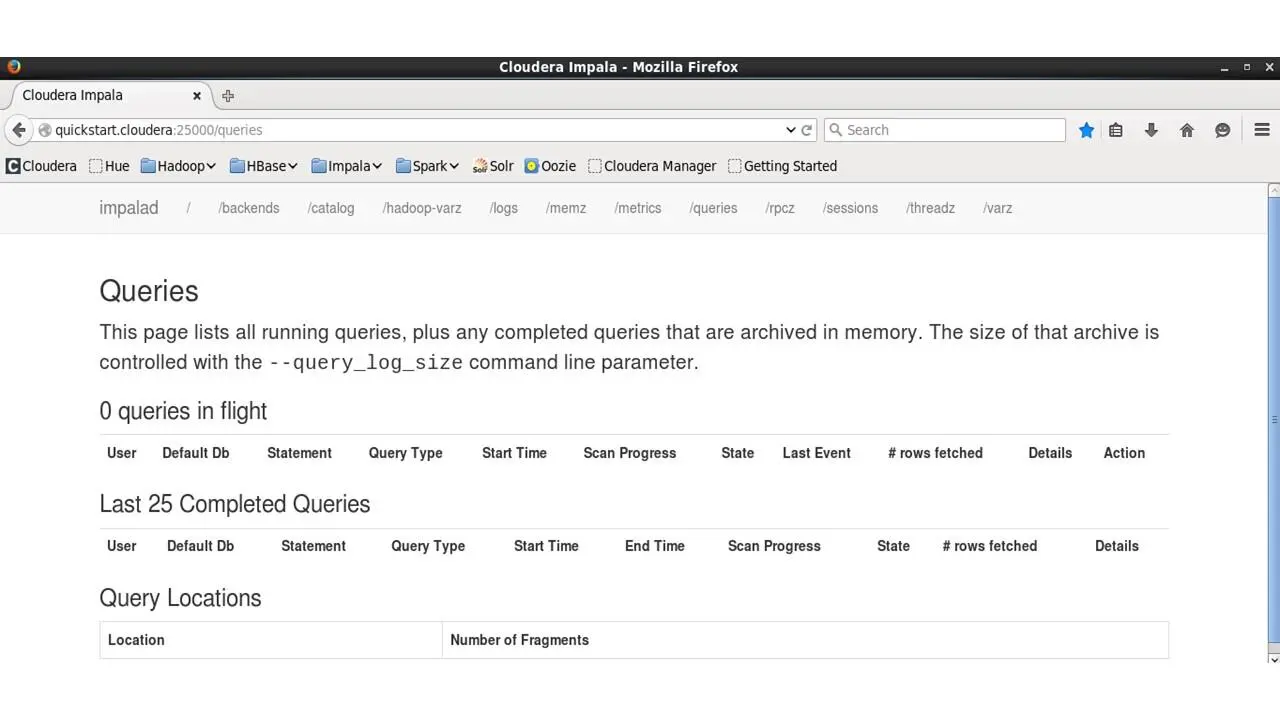
Impala позволяет нам отправлять высокопроизводительные SQL-подобные запросы к данным, хранящимся в HDFS.
И здесь мы можем посмотреть последние 25 выполненных запросов, мы можем посмотреть на запросы, которые происходят прямо сейчас, мы можем посмотреть на местоположения и фрагменты, к которым были отправлены эти запросы.
Читать дальшеИнтервал:
Закладка:
Похожие книги на «Технология хранения и обработки больших данных Hadoop»
Представляем Вашему вниманию похожие книги на «Технология хранения и обработки больших данных Hadoop» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.












Обсуждение, отзывы о книге «Технология хранения и обработки больших данных Hadoop» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.