Тимур Машнин - Технология хранения и обработки больших данных Hadoop
Здесь есть возможность читать онлайн «Тимур Машнин - Технология хранения и обработки больших данных Hadoop» — ознакомительный отрывок электронной книги совершенно бесплатно, а после прочтения отрывка купить полную версию. В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Год выпуска: 2021, ISBN: 2021, Жанр: Прочая околокомпьтерная литература, Программирование, Интернет, на русском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.

- Название:Технология хранения и обработки больших данных Hadoop
- Автор:
- Жанр:
- Год:2021
- ISBN:978-5-532-96881-3
- Рейтинг книги:3 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
Технология хранения и обработки больших данных Hadoop: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «Технология хранения и обработки больших данных Hadoop»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
Технология хранения и обработки больших данных Hadoop — читать онлайн ознакомительный отрывок
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «Технология хранения и обработки больших данных Hadoop», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
Каждый Hadoop кластер обычно состоит из одного узла Namenode и кластера узлов Datanode, которые и формируют этот кластер.
И каждая система HDFS хранит большие файлы, как правило, в диапазоне от гигабайтов до терабайтов.
И надежность системы HDFS достигается путем репликации многочисленных хостов.
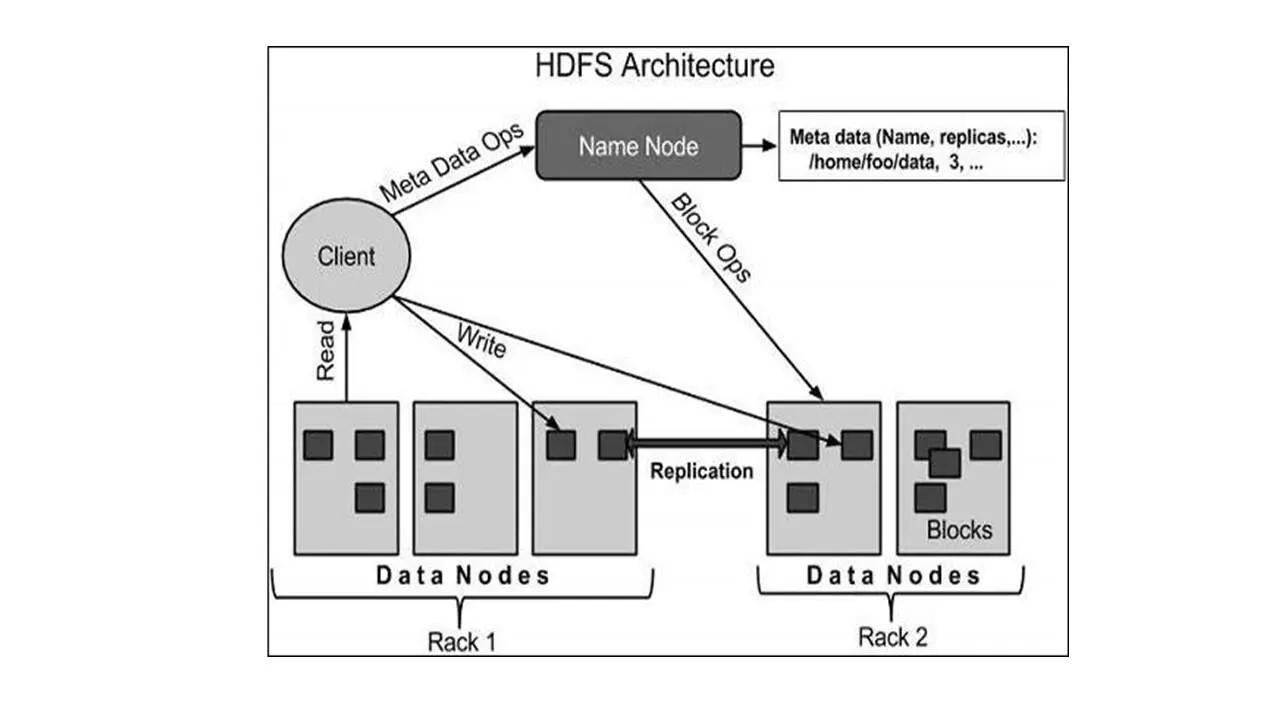
Также файловая система HTFS поддерживает так называемый вторичный узел NameNote, который регулярно подключается к первичному узлу NameNote и создает снимки его состояния, запоминая, что система сохраняет в локальных и удаленных каталогах.
В каждой системе, основанной на Hadoop, содержится какая-то версия движка MapReduce.
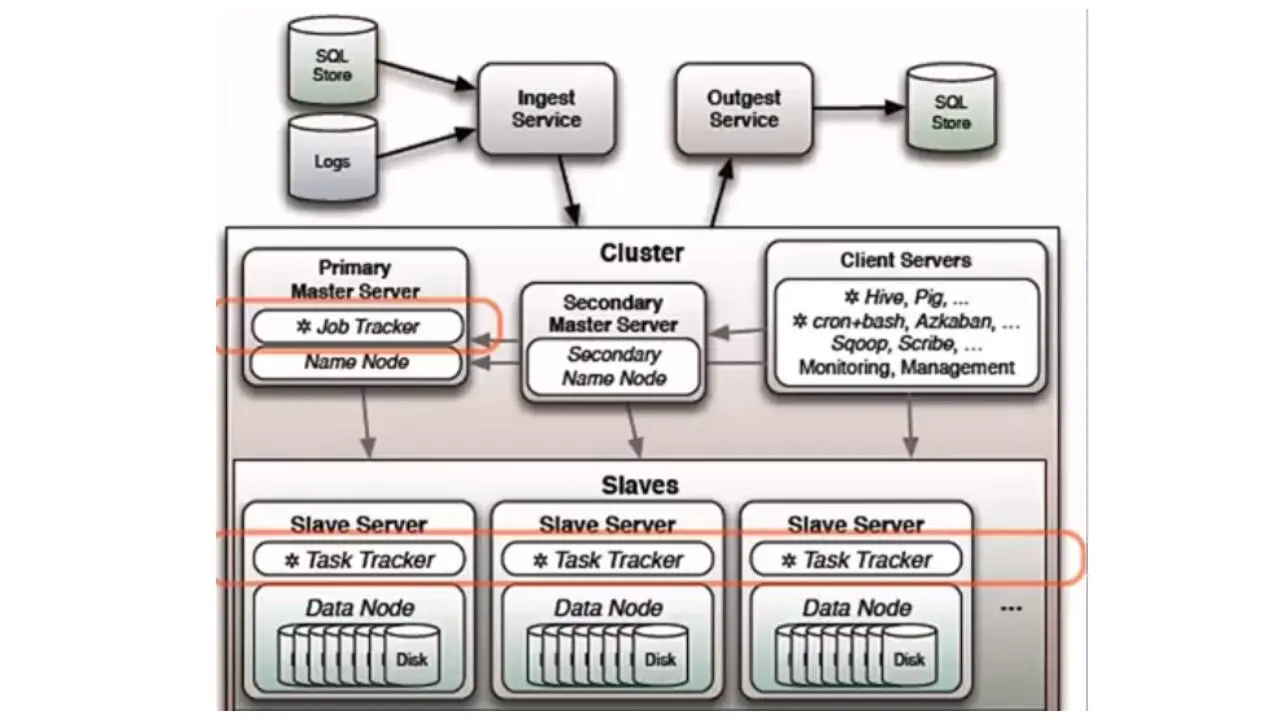
Типичный движок MapReduce содержит средство отслеживания работы, в которое клиентские приложения могут отправлять задания MapReduce.
И этот трекер работы передает задачи всем доступным трекерам задач, которые есть в кластере.
Таким образом, классический Hadoop MapReduce представляет собой один процесс JobTracker и произвольное количество процессов TaskTracker, или по-другому один мастер узел и множество узлов slave.
MapReduce выполняет работу над огромным набором данных, обрабатывая данные и сохраняя их в HDFS таким образом, что извлечение данных производится проще, чем в традиционном хранилище.
Модель MapReduce следует принципам функционального программирования, вследствие чего пользовательские вычисления выполняются как функции map и reduce, обрабатывающие данные в виде пар ключ-значение.
Hadoop предоставляет высокоуровневый программный интерфейс для реализации пользовательских функций map и reduce на различных языках.
Также Hadoop предоставляет инфраструктуру для выполнения заданий MapReduce в виде серий задач map и reduce.
Задачи map вызывают функции map для обработки наборов входных данных.
Затем задачи reduce вызывают функции reduce для обработки промежуточных данных, сгенерированных функциями map, формируя окончательные выходные данные.
Задачи map и reduce выполняются изолированно друг от друга, что обеспечивает параллельность и отказоустойчивость вычислений.
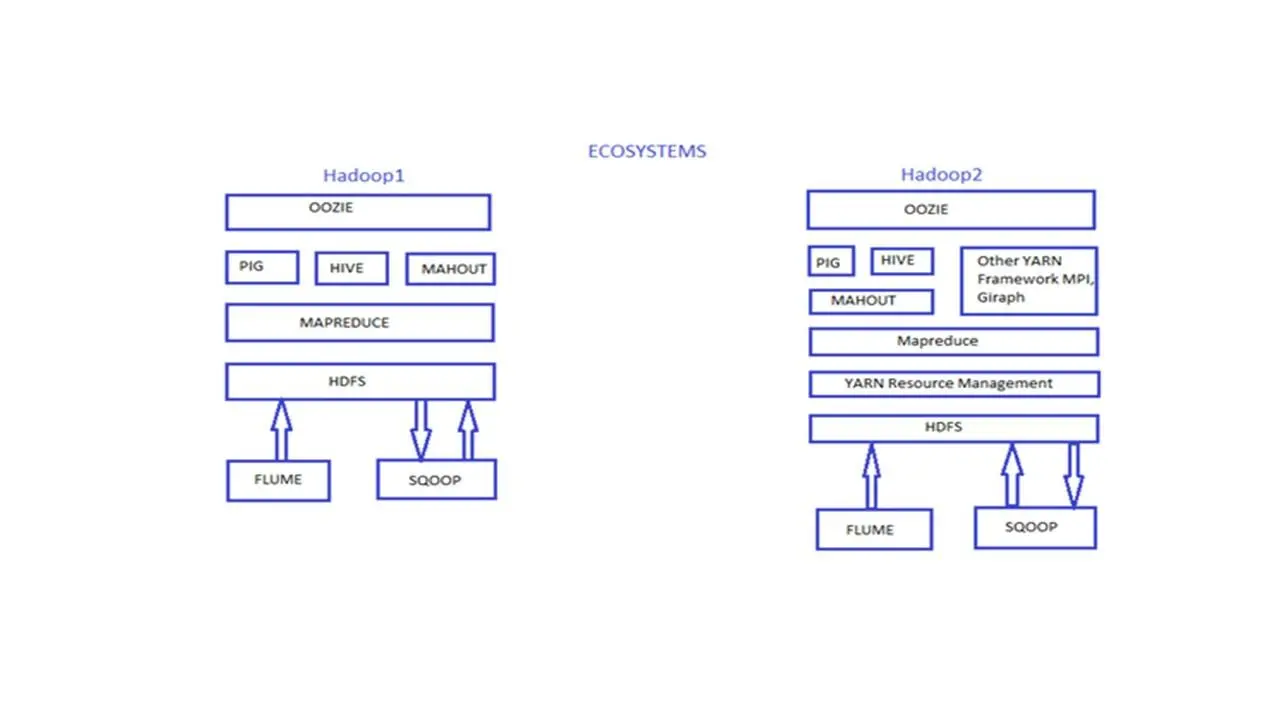
Hadoop версии 1 содержал компоненты HDFS и Map Reduce.
И Hadoop версии 1 разрабатывался только для выполнения заданий MapReduce.
А Hadoop версии 2 уже содержит компоненты HDFS и YARN/Map Reduce версии 2.
В классическом Map Reduce, когда мастер узел перестает работать, тогда все его узлы slave автоматически перестают работать.
И мы должны перезапустить весь кластер и заново начать выполнять работу.
Это единственный сценарий, когда выполнение работы может прерваться, и это создает единственную точку отказа.
Компонент YARN или Yet Another Resource Negotiator решает эту проблему благодаря своей архитектуре.
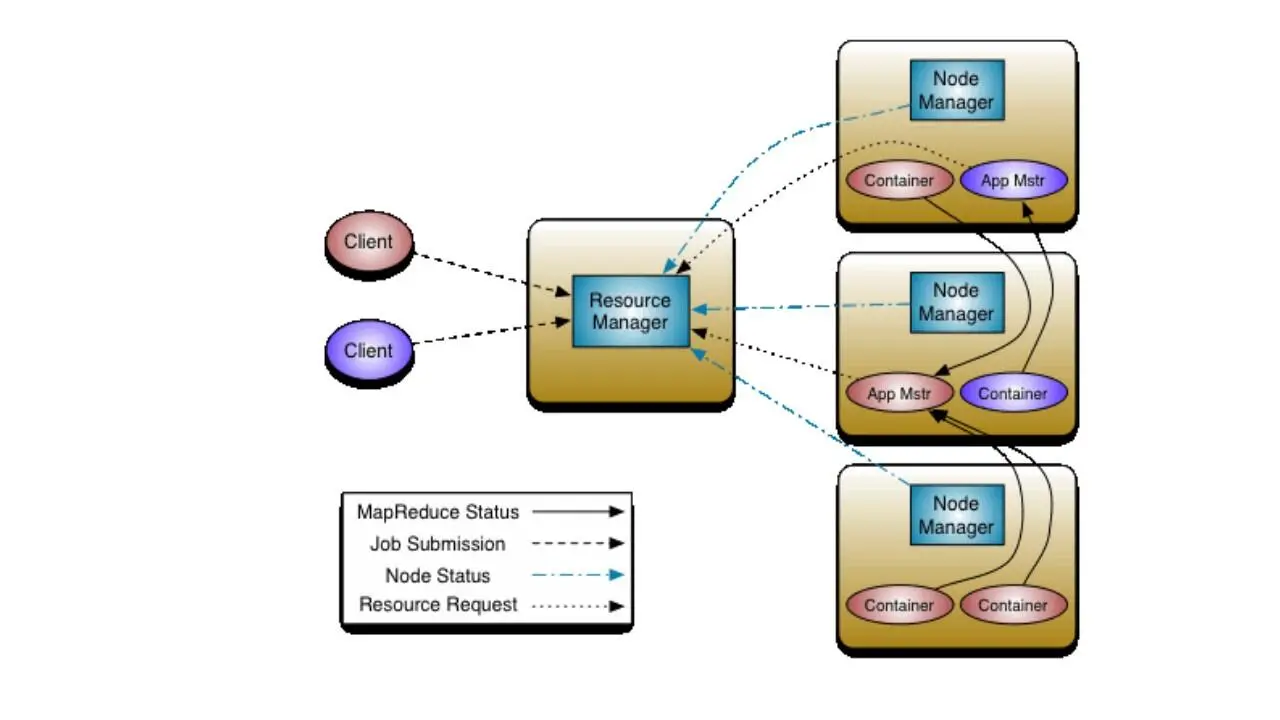
YARN основывается на концепции нескольких мастер узлов и нескольких подчиненных slave узлов, и если один мастер узел выйдет из строя, тогда другой мастер узел возобновит процесс и продолжит выполнение.
Классический Map Reduce отвечает как за управление ресурсами, так и за обработку данных.
В Hadoop версии 2, YARN разделяет функций управления ресурсами и планирования/мониторинга заданий на отдельные демоны.
YARN – это универсальная платформа для запуска любого распределенного приложения, и здесь Map Reduce – это распределенное приложение, которое работает поверх YARN.
Таким образом, YARN отвечает за управление ресурсами, то есть решает, какая работа будет выполняться и какой системой.
Тогда как Map Reduce является фреймворком программирования, который отвечает за то, как выполнить конкретную работу, используя два компонента mapper и reducer.
YARN отделяет компоненты управления ресурсами от компонентов обработки, и YARN не сводится только к MapReduce.
Диспетчер ресурсов resource manager YARN оптимизирует использование кластера и поддерживает другие рабочие процессы, кроме Map Reduce.
Поэтому здесь мы можем добавлять дополнительные программные модели, такие как обработка графов или итеративное моделирование, которые могут обрабатывать данные, используя те же кластеры и общие ресурсы.
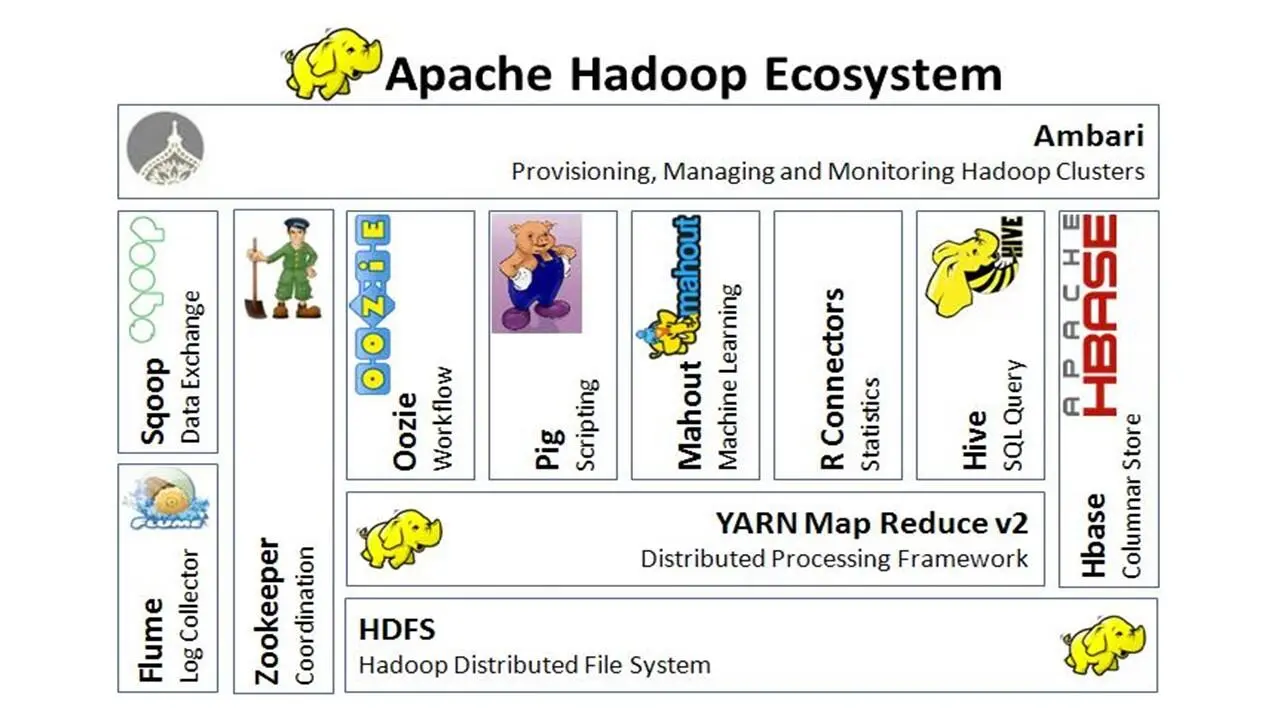
Поверх HDFS и Yarn могут работать множество компонентов, и эта архитектура также развивалась с течением времени.
Читать дальшеИнтервал:
Закладка:
Похожие книги на «Технология хранения и обработки больших данных Hadoop»
Представляем Вашему вниманию похожие книги на «Технология хранения и обработки больших данных Hadoop» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.












Обсуждение, отзывы о книге «Технология хранения и обработки больших данных Hadoop» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.