Валентин Арьков - Эконометрические оценки. Учебное пособие
Здесь есть возможность читать онлайн «Валентин Арьков - Эконометрические оценки. Учебное пособие» — ознакомительный отрывок электронной книги совершенно бесплатно, а после прочтения отрывка купить полную версию. В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. ISBN: , Жанр: Прочая околокомпьтерная литература, Прочая научная литература, Математика, на русском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.
- Название:Эконометрические оценки. Учебное пособие
- Автор:
- Жанр:
- Год:неизвестен
- ISBN:9785005530646
- Рейтинг книги:5 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
Эконометрические оценки. Учебное пособие: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «Эконометрические оценки. Учебное пособие»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
Эконометрические оценки. Учебное пособие — читать онлайн ознакомительный отрывок
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «Эконометрические оценки. Учебное пособие», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
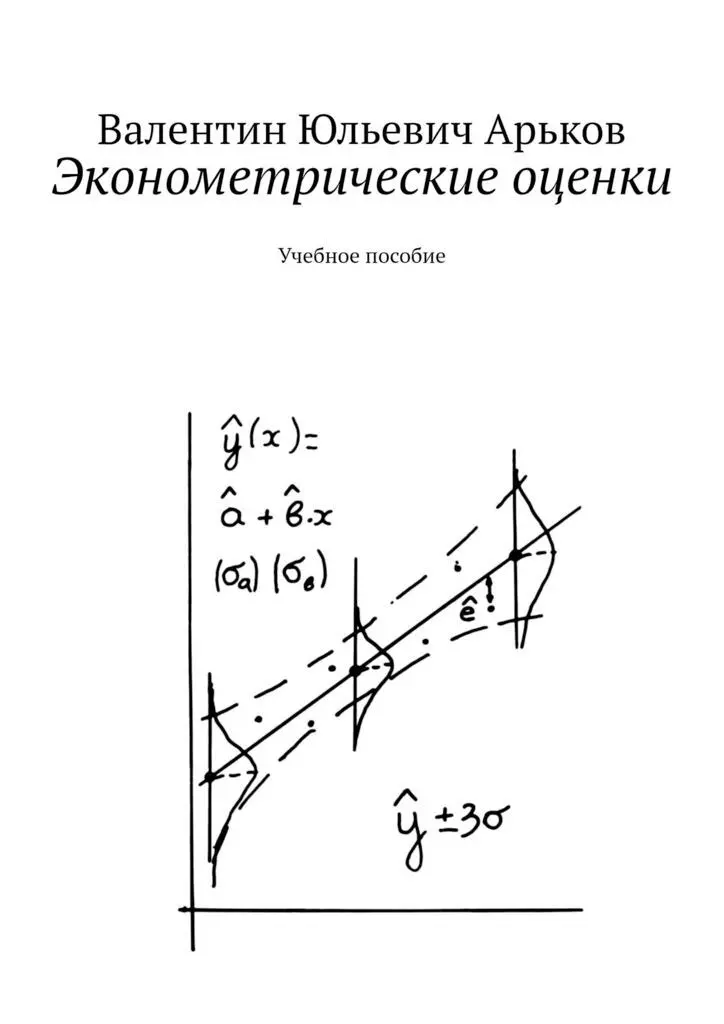
Вам предстоит проделать показанные эксперименты. Повторите этот опыт несколько раз, чтобы убедиться, что оценка вероятности немного меняется. Но в среднем оценка «крутится» вокруг точного значения, см. рис.

Рис. План задания
Jupyter Lab
Следующий эксперимент мы проделаем в питоне. Или в Python – если больше нравятся английские названия.
Здесь мы с вами познакомимся с некоторыми приемами работы в диалоговой среде Anaconda / Jupyter Lab и некоторыми командами Python.
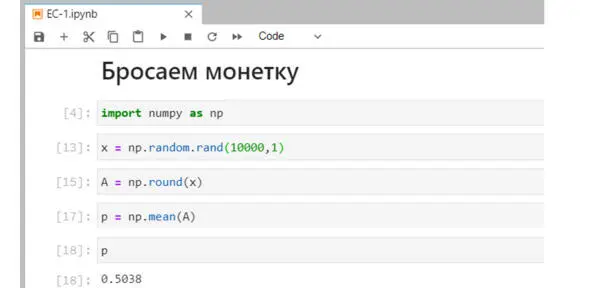
Рис. Программа в Jupyter Lab
В первой строчке мы импортируем библиотеку numpyи назначаем ей псевдоним np – для краткости. Это библиотека для работы с числовыми массивами. В обычном, базовом питоне мы тоже можем создавать различные объекты. Однако, numpyпозволяет работать с матрицами, то есть с массивами / таблицами чисел. Это могут быть столбцы, или строки, или таблички чисел. Все они условно называются массивами.
Дальше мы будем обращаться к функциям из этой библиотеки np.
Вторая строка – вызов генератора случайных чисел с равномерным распределением. В аргументах функции randуказываем размеры массива, который хотим получить: 10000 строк и 1 столбец.
Следующим шагом мы округляем эти числа с помощью функции round.
Далее находим среднее значение для всего этого массива чисел. Это делает функция mean. Полученную оценку вероятности выводим на экран.
Здесь надо отметить один любопытный момент. Функции для вычисления среднего значения могут называться MEANи AVERAGE. Могут быть и другие названия. Причём это происходит в рамках одного пакета программ – если это делали в разное время и разные команды разработчиков. За этим приходится следить. Конечно же, мы всегда можем посмотреть справку под названием help. Там же обычно даются примеры использования команды.
Запускаем нашу программу несколько раз и наблюдаем, что выводится на экран в качестве оценки вероятности.
Google Colab
Мы можем проделать наши опыты с теми же результатами и в облачном сервисе Google Colaboratory, см. рис.
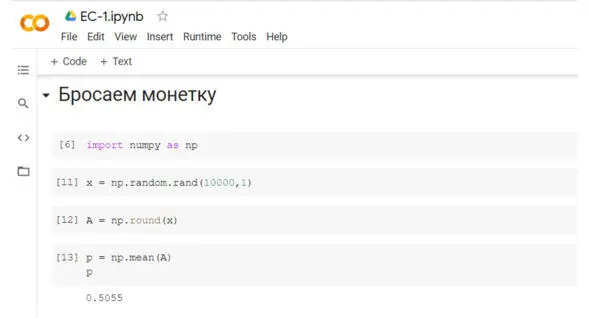
Рис. Программма в Google Colab
Внешне всё очень похоже на Anaconda / Jupyter Lab. Мы получаем практически стопроцентную совместимость с программой, отлаженной на локальном компьютере. Тем не менее, иногда бывает тонкости. Colab работает с самыми последними версиями библиотек. И нам не требуется постоянно их обновлять вручную.
Итак, мы запускаем Colab. Нас спрашивают, хотим ли мы открыть существующий файл или создать новый. Создаем новый блокнот.
Вводим первую команду, нажимаем комбинацию клавиш [Shift+Enter]. Проходит некоторое время на запуск – в правой верхней части экрана выводится сообщение про соединение с виртуальной машиной: Connect.
Обратим внимание, что при вводе функцию сразу появляется всплывающая подсказка.
Когда ячейка выполнилась, слева от этой ячейки блокнота видим комментарий в квадратных скобках – выводится какое-то число. Это порядковый номер выполненной ячейки. Ячейки можно запускать в разном порядке, и это будет отображаться в квадратных скобках.
И ещё один момент: при вычислении среднего значения не уточняется метод расчёта. В описании функции говорится: arithmetic mean, то есть среднее арифметическое. На занятиях по статистике вы можете узнать, что среднее можно считать десятью разными способами. Но средняя арифметическая простая используется чаще всего.
Чтобы вывести полученную оценку на экран мы просто вводим имя переменной.
Запускаем несколько раз: Runtime – Run All.
Для вывода на экран можно также использовать команду print. Это обеспечит побольше знаков после запятой. Здесь можно задать любой формат вывода.
Подведём итоги. Неважно, какими средствами анализа мы пользуемся. Результаты обработки данных каждый раз представляют собой случайные числа. Они будут приближаться к точному, правильному значению. Но оценка содержит внутри себя случайность.
Ваша задача – потренироваться и убедиться в следующем. Оценки – это результат обработки реальных данных. Исходные данные содержат случайность. Поэтому оценки тоже являются случайными числами. Нужно проделать этот опыт на локальном компьютере и в облаке, см. рис.
Читать дальшеИнтервал:
Закладка:
Похожие книги на «Эконометрические оценки. Учебное пособие»
Представляем Вашему вниманию похожие книги на «Эконометрические оценки. Учебное пособие» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.







Обсуждение, отзывы о книге «Эконометрические оценки. Учебное пособие» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.