Qing Li - Real-Time Concepts for Embedded Systems
Здесь есть возможность читать онлайн «Qing Li - Real-Time Concepts for Embedded Systems» весь текст электронной книги совершенно бесплатно (целиком полную версию без сокращений). В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Город: San Francisco, Год выпуска: 2003, ISBN: 2003, Издательство: CMP books, Жанр: ОС и Сети, на английском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.

- Название:Real-Time Concepts for Embedded Systems
- Автор:
- Издательство:CMP books
- Жанр:
- Год:2003
- Город:San Francisco
- ISBN:1-57820-124-1
- Рейтинг книги:4 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
Real-Time Concepts for Embedded Systems: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «Real-Time Concepts for Embedded Systems»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
Delve into the details of real-time programming so you can develop a working knowledge of the common design patterns and program structures of real-time operating systems (RTOS). The objects and services that are a part of most RTOS kernels are described and real-time system design is explored in detail. You learn how to decompose an application into units and how to combine these units with other objects and services to create standard building blocks. A rich set of ready-to-use, embedded design “building blocks” is also supplied to accelerate your development efforts and increase your productivity.
Experienced developers new to embedded systems and engineering or computer science students will both appreciate the careful balance between theory, illustrations, and practical discussions. Hard-won insights and experiences shed new light on application development, common design problems, and solutions in the embedded space. Technical managers active in software design reviews of real-time embedded systems will find this a valuable reference to the design and implementation phases.
Qing Li is a senior architect at Wind River Systems, Inc., and the lead architect of the company’s embedded IPv6 products. Qing holds four patents pending in the embedded kernel and networking protocol design areas. His 12+ years in engineering include expertise as a principal engineer designing and developing protocol stacks and embedded applications for the telecommunications and networks arena. Qing was one of a four-member Silicon Valley startup that designed and developed proprietary algorithms and applications for embedded biometric devices in the security industry.
Caroline Yao has more than 15 years of high tech experience ranging from development, project and product management, product marketing, business development, and strategic alliances. She is co-inventor of a pending patent and recently served as the director of partner solutions for Wind River Systems, Inc. About the Authors
Real-Time Concepts for Embedded Systems — читать онлайн бесплатно полную книгу (весь текст) целиком
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «Real-Time Concepts for Embedded Systems», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
· run to completion, or
· endless loop.
Both task structures are relatively simple. Run-to-completion tasks are most useful for initialization and startup. They typically run once, when the system first powers on. Endless-loop tasks do the majority of the work in the application by handling inputs and outputs. Typically, they run many times while the system is powered on.
5.5.1 Run-to-Completion Tasks
An example of a run-to-completion task is the application-level initialization task, shown in Listing 5.1. The initialization task initializes the application and creates additional services, tasks, and needed kernel objects.
Listing 5.1: Pseudo code for a run-to-completion task.
RunToCompletionTask () {
Initialize application
Create ‘endless loop tasks'
Create kernel objects
Delete or suspend this task
}
The application initialization task typically has a higher priority than the application tasks it creates so that its initialization work is not preempted. In the simplest case, the other tasks are one or more lower priority endless-loop tasks. The application initialization task is written so that it suspends or deletes itself after it completes its work so the newly created tasks can run.
5.5.2 Endless-Loop Tasks
As with the structure of the application initialization task, the structure of an endless loop task can also contain initialization code. The endless loop's initialization code, however, only needs to be executed when the task first runs, after which the task executes in an endless loop, as shown in Listing 5.2.
The critical part of the design of an endless-loop task is the one or more blocking calls within the body of the loop. These blocking calls can result in the blocking of this endless-loop task, allowing lower priority tasks to run.
Listing 5.2: Pseudo code for an endless-loop task.
EndlessLoopTask () {
Initialization code
Loop Forever {
Body of loop
Make one or more blocking calls
}
}
5.6 Synchronization, Communication, and Concurrency
Tasks synchronize and communicate amongst themselves by using intertask primitives , which are kernel objects that facilitate synchronization and communication between two or more threads of execution. Examples of such objects include semaphores, message queues, signals, and pipes, as well as other types of objects. Each of these is discussed in detail in later chapters of this book.
The concept of concurrency and how an application is optimally decomposed into concurrent tasks is also discussed in more detail later in this book. For now, remember that the task object is the fundamental construct of most kernels. Tasks, along with task-management services, allow developers to design applications for concurrency to meet multiple time constraints and to address various design problems inherent to real-time embedded applications.
5.7 Points to Remember
Some points to remember include the following:
· Most real-time kernels provide task objects and task-management services that allow developers to meet the requirements of real-time applications.
· Applications can contain system tasks or user-created tasks, each of which has a name, a unique ID, a priority, a task control block (TCB), a stack, and a task routine.
· A real-time application is composed of multiple concurrent tasks that are independent threads of execution, competing on their own for processor execution time.
· Tasks can be in one of three primary states during their lifetime: ready, running, and blocked.
· Priority-based, preemptive scheduling kernels that allow multiple tasks to be assigned to the same priority use task-ready lists to help scheduled tasks run.
· Tasks can run to completion or can run in an endless loop. For tasks that run in endless loops, structure the code so that the task blocks, which allows lower priority tasks to run.
· Typical task operations that kernels provide for application development include task creation and deletion, manual task scheduling, and dynamic acquisition of task information.
Chapter 6: Semaphores
6.1 Introduction
Multiple concurrent threads of execution within an application must be able to synchronize their execution and coordinate mutually exclusive access to shared resources. To address these requirements, RTOS kernels provide a semaphore object and associated semaphore management services.
This chapter discusses the following:
· defining a semaphore,
· typical semaphore operations, and
· common semaphore use.
6.2 Defining Semaphores
A semaphore (sometimes called a semaphore token ) is a kernel object that one or more threads of execution can acquire or release for the purposes of synchronization or mutual exclusion.
When a semaphore is first created, the kernel assigns to it an associated semaphore control block (SCB), a unique ID, a value (binary or a count), and a task-waiting list, as shown in Figure 6.1.
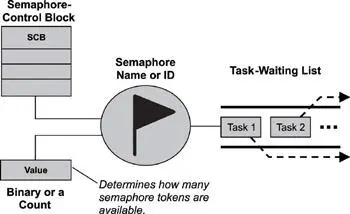
Figure 6.1: A semaphore, its associated parameters, and supporting data structures.
A semaphore is like a key that allows a task to carry out some operation or to access a resource. If the task can acquire the semaphore, it can carry out the intended operation or access the resource. A single semaphore can be acquired a finite number of times. In this sense, acquiring a semaphore is like acquiring the duplicate of a key from an apartment manager-when the apartment manager runs out of duplicates, the manager can give out no more keys. Likewise, when a semaphore’s limit is reached, it can no longer be acquired until someone gives a key back or releases the semaphore.
The kernel tracks the number of times a semaphore has been acquired or released by maintaining a token count, which is initialized to a value when the semaphore is created. As a task acquires the semaphore, the token count is decremented; as a task releases the semaphore, the count is incremented.
If the token count reaches 0, the semaphore has no tokens left. A requesting task, therefore, cannot acquire the semaphore, and the task blocks if it chooses to wait for the semaphore to become available. (This chapter discusses states of different semaphore variants and blocking in more detail in "Typical Semaphore Operations", section 6.3.)
The task-waiting list tracks all tasks blocked while waiting on an unavailable semaphore. These blocked tasks are kept in the task-waiting list in either first in/first out (FIFO) order or highest priority first order.
When an unavailable semaphore becomes available, the kernel allows the first task in the task-waiting list to acquire it. The kernel moves this unblocked task either to the running state, if it is the highest priority task, or to the ready state, until it becomes the highest priority task and is able to run. Note that the exact implementation of a task-waiting list can vary from one kernel to another.
A kernel can support many different types of semaphores, including binary, counting, and mutual-exclusion (mutex) semaphores.
6.2.1 Binary Semaphores
A binary semaphore can have a value of either 0 or 1. When a binary semaphore’s value is 0, the semaphore is considered unavailable (or empty); when the value is 1, the binary semaphore is considered available (or full ). Note that when a binary semaphore is first created, it can be initialized to either available or unavailable (1 or 0, respectively). The state diagram of a binary semaphore is shown in Figure 6.2.
Читать дальшеИнтервал:
Закладка:
Похожие книги на «Real-Time Concepts for Embedded Systems»
Представляем Вашему вниманию похожие книги на «Real-Time Concepts for Embedded Systems» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.












Обсуждение, отзывы о книге «Real-Time Concepts for Embedded Systems» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.