Джон Келлехер - Наука о данных. Базовый курс
Здесь есть возможность читать онлайн «Джон Келлехер - Наука о данных. Базовый курс» — ознакомительный отрывок электронной книги совершенно бесплатно, а после прочтения отрывка купить полную версию. В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Город: Москва, Год выпуска: 2020, ISBN: 2020, Издательство: Альпина Паблишер, Жанр: Базы данных, на русском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.

- Название:Наука о данных. Базовый курс
- Автор:
- Издательство:Альпина Паблишер
- Жанр:
- Год:2020
- Город:Москва
- ISBN:978-5-9614-3378-4
- Рейтинг книги:3 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
Наука о данных. Базовый курс: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «Наука о данных. Базовый курс»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
Книга знакомит с основами науки о данных. В ней охватываются все ключевые аспекты, начиная с истории развития сбора и анализа данных и заканчивая этическими проблемами, связанными с конфиденциальностью информации. Авторы объясняют, как работают нейронные сети и машинное обучение, приводят примеры анализа бизнес-проблем и того, как их можно решить, рассказывают о сферах, на которые наука о данных окажет наибольшее влияние в будущем.
«Наука о данных» уже переведена на японский, корейский и китайский языки.
Наука о данных. Базовый курс — читать онлайн ознакомительный отрывок
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «Наука о данных. Базовый курс», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
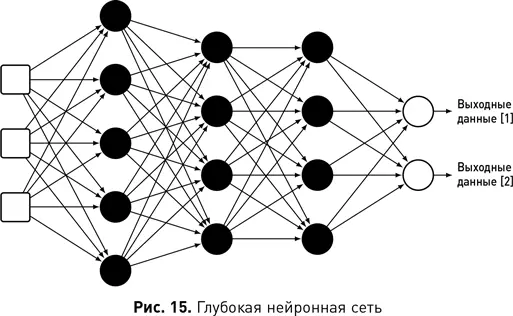
Сила глубоких нейронных сетей в том, что они могут автоматически изучать полезные атрибуты, такие как детекторы признаков в СНС. Глубокое обучение иногда так и называют — «обучение признакам», поскольку глубокие сети по сути изучают новое представление входных данных, которое лучше подходит для прогнозирования целевого выходного атрибута, чем исходный необработанный ввод. Каждый нейрон в сети определяет функцию, которая отображает значения в новый входной атрибут. Поэтому нейрон в первом слое сети может изучать функцию, которая преобразует необработанные входные значения (например, вес и рост) в более полезный атрибут (например, ИМТ). Однако выход этого нейрона наравне с его сестринскими нейронами в первом слое подается в нейроны второго слоя, изучающие функции, которые преобразуют выходные данные первого слоя в новые и еще более полезные представления. Этот процесс сопоставления входных данных с новыми атрибутами и передачи этих новых атрибутов в качестве входных данных для следующих функций распространяется по сети, и по мере того, как сеть становится глубже, она может изучать все более и более сложные сопоставления. Именно способность автоматически изучать сложные сопоставления входных данных с полезными атрибутами делает модели глубокого обучения настолько точными при выполнении задач с многомерным вводом (таких, как обработка изображений и текста).
Давно известно, что чем глубже нейронная сеть, тем более сложные отображения данных она способна изучать. Однако развитие глубокое обучение получило лишь в последние несколько лет, и причина этого заключается в том, что стандартная комбинация случайного веса с последующим алгоритмом обратного распространения ошибки не очень хорошо работала с глубокими сетями. Во-первых, ошибка в этом случае распределяется по мере того, как процесс возвращается со слоя на слой, так что к тому времени, когда алгоритм достигает ранних слоев глубокой сети, оценки ошибок уже не так полезны [21]. В результате слои в ранних частях сети не учатся полезным преобразованиям данных. Однако в последние годы были разработаны новые типы нейронов и адаптации к алгоритму обратного распространения, которые помогают решить эту проблему. Также было обнаружено, что требуется осторожная инициализация весов сети. Два других фактора, которые усложняли обучение глубоких сетей, заключались в том, что для обучения нейронной сети требуется большая вычислительная мощность и к тому же нейронные сети показывают максимальную эффективность на большом количестве обучающих данных. В последние годы большие вычислительные мощности стали доступнее, и это сделало обучение глубоких сетей осуществимым.
Линейная регрессия и нейронные сети лучше всего работают с числовыми входными данными. Если входные атрибуты в наборе данных в основном номинальные или порядковые, лучше использовать другие алгоритмы и модели машинного обучения, такие как деревья решений.
Дерево решений кодирует условный оператор если-то-иначе в древовидной структуре. Рис. 16 иллюстрирует дерево решений для проблемы, стоит ли смотреть фильм. Прямоугольники с закругленными углами представляют собой тесты атрибутов, а квадраты обозначают узлы решения, или классификации. Это дерево кодирует следующие правила: если фильм — комедия, то смотреть; если фильм не комедия, а триллер, то тоже смотреть; если он не комедия и не триллер, то не смотреть . Процесс решения для объекта в структуре дерева решений начинается с его вершины и спускается вниз, последовательно тестируя атрибуты объекта. Каждый узел дерева устанавливает один атрибут для тестирования, и процесс спускается вниз узел за узлом, выбирая следующую ветвь по метке, соответствующей значению теста атрибута. Финальное решение — это метка конечного (или листового) узла, к которому спускается объект.
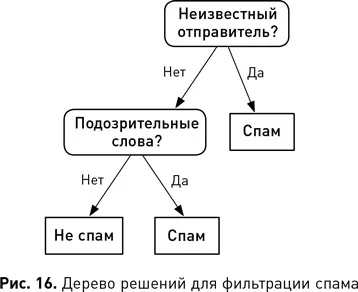
Все пути в структуре дерева решений от корня до листа определяются правилом классификации, состоящим из последовательных тестов. Цель обучения дерева решений состоит в том, чтобы найти такие правила классификации, которые делят обучающий набор данных на группы объектов, имеющих одинаковое значение целевого атрибута. Идея состоит в том, что если правило классификации может отделить от набора данных подмножество объектов с одинаковым целевым значением и если оно истинно для нового объекта (т. е. такого, который идет по этому пути в дереве), то вероятно, что правильный прогноз для этого нового объекта — целевое значение, общее для всех обучающих объектов, соответствующих этому правилу.
Читать дальшеИнтервал:
Закладка:
Похожие книги на «Наука о данных. Базовый курс»
Представляем Вашему вниманию похожие книги на «Наука о данных. Базовый курс» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.











Обсуждение, отзывы о книге «Наука о данных. Базовый курс» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.