Джон Келлехер - Наука о данных. Базовый курс
Здесь есть возможность читать онлайн «Джон Келлехер - Наука о данных. Базовый курс» — ознакомительный отрывок электронной книги совершенно бесплатно, а после прочтения отрывка купить полную версию. В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Город: Москва, Год выпуска: 2020, ISBN: 2020, Издательство: Альпина Паблишер, Жанр: Базы данных, на русском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.

- Название:Наука о данных. Базовый курс
- Автор:
- Издательство:Альпина Паблишер
- Жанр:
- Год:2020
- Город:Москва
- ISBN:978-5-9614-3378-4
- Рейтинг книги:3 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
Наука о данных. Базовый курс: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «Наука о данных. Базовый курс»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
Книга знакомит с основами науки о данных. В ней охватываются все ключевые аспекты, начиная с истории развития сбора и анализа данных и заканчивая этическими проблемами, связанными с конфиденциальностью информации. Авторы объясняют, как работают нейронные сети и машинное обучение, приводят примеры анализа бизнес-проблем и того, как их можно решить, рассказывают о сферах, на которые наука о данных окажет наибольшее влияние в будущем.
«Наука о данных» уже переведена на японский, корейский и китайский языки.
Наука о данных. Базовый курс — читать онлайн ознакомительный отрывок
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «Наука о данных. Базовый курс», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
Предположим, что нейроны в сети на рис. 13 используют функцию активации tanh. Тогда вычисление, выполняемое нейроном F , может быть представлено как:
Выходные данные = tanh (ω C,FC + ω D,FD + ω E,FE ).
Математическое представление обработки, выполняемой в нейроне F, показывает, что конечное выходное значение сети рассчитывается с использованием набора функций. Компоновка функций означает, что выходные данные одной функции используются в качестве входных данных для другой. В этом случае выходы нейронов C, D и E используются в качестве входов для нейрона F , поэтому функция, выполняемая в F , скомпонована из функций, выполняемых в C, D и E .
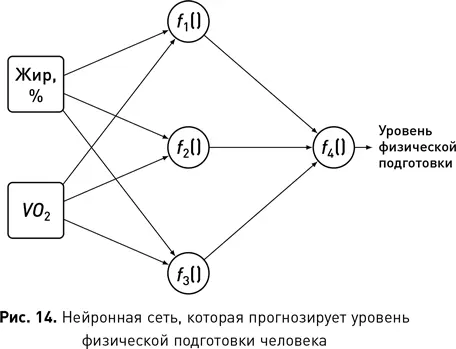
Для наглядности этого описания на рис. 14 показана нейронная сеть, которая принимает значение процентного содержания жира в организме человека и его МПК (максимальное потребление кислорода [17]) в качестве входных данных и вычисляет индивидуальный уровень физической подготовки [18]. Все нейроны в среднем слое сети вычисляют функцию на основе процентного содержания жира и МПК: f 1(), f 2() и f 3(). Каждая из этих функций моделирует взаимодействие между входами иначе, чем две другие. Эти функции по существу представляют собой новые атрибуты, которые получены сетью из необработанных входных данных. Они схожи с атрибутом ИМТ, описанным ранее, который был рассчитан как функция веса и роста. Иногда оказывается возможным интерпретировать выходные данные нейрона внутри сети, насколько это позволяет предметная область, и понять, почему этот производный атрибут полезен для сети. Однако чаще производный атрибут, рассчитанный нейроном, не будет нести никакого смысла для человека. Просто эти атрибуты фиксируют взаимодействия между другими атрибутами, которые сеть сочла полезными. Последний узел в сети f 4вычисляет другую функцию — скомпонованную из f 1(), f 2() и f 3(), — на выходе которой получается прогноз уровня физической подготовки, возвращаемый сетью. Опять же, эта функция не может быть значимой для человека, кроме того факта, что она определяет взаимодействие, которое, как обнаружила сеть, имеет высокую корреляцию с целевым атрибутом.
Обучение нейронной сети включает в себя поиск правильных весов для ее связей. Чтобы понять, как обучается сеть, полезно начать с размышлений о том, как отдельный нейрон обучается рассчитывать вес связи. Предположим, что у нас есть обучающий набор данных, который имеет для каждого объекта и входные значения, и целевой атрибут. Также предположим, что входящим связям нейрона уже назначены веса. Если мы возьмем объект из набора данных и представим нейрону значения входных атрибутов этого объекта, он выдаст прогноз для цели. Вычитая этот прогноз из значения целевого атрибута в наборе данных, мы сможем измерить отклонение нейрона для этого объекта. Используя ряд простых вычислений, можно вывести правило для обновления весов входящих связей нейрона с учетом выходного отклонения нейрона, чтобы уменьшить выходное отклонение. Точное определение этого правила будет варьироваться в зависимости от функции активации, используемой нейроном, поскольку она влияет на производную, используемую при выводе правила. Но можно дать следующее наглядное пояснение того, как работает правило обновления веса:
1. Если отклонение равно 0, не меняйте веса на входах.
2. Если отклонение положительное, требуется увеличить прогнозное значение, поэтому нужно прибавить веса всех связей с положительным входом и понизить веса связей с отрицательным.
3. Если отклонение отрицательное, требуется уменьшить прогнозное значение, поэтому нужно понизить веса всех связей с положительным входом и прибавить веса связей с отрицательным.
Сложность обучения нейронной сети состоит в том, что правило обновления веса требует оценки ошибки в нейроне, и, хотя вычислить ошибку для каждого нейрона в выходном слое сети довольно просто, сделать то же самое для нейронов в более ранних слоях намного сложнее. Стандартный способ обучения нейронной сети заключается в использовании алгоритма, называемого методом обратного распространения ошибки. Алгоритм обратного распространения является алгоритмом машинного обучения с учителем, поэтому он предполагает набор обучающих данных, который бы имел как входные значения, так и целевой атрибут для каждого объекта. Обучение начинается с назначения случайных весов каждой связи в сети. Затем алгоритм итеративно обновляет весовые коэффициенты, показывая сети обучающие объекты из набора данных и обновляя весовые коэффициенты до тех пор, пока сеть не начнет работать как ожидалось. Алгоритму присваивается имя, потому что после того, как каждый обучающий объект представлен сети, ее веса обновляются путем последовательных шагов в направлении назад по сети:
Читать дальшеИнтервал:
Закладка:
Похожие книги на «Наука о данных. Базовый курс»
Представляем Вашему вниманию похожие книги на «Наука о данных. Базовый курс» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.











Обсуждение, отзывы о книге «Наука о данных. Базовый курс» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.