Джон Келлехер - Наука о данных. Базовый курс
Здесь есть возможность читать онлайн «Джон Келлехер - Наука о данных. Базовый курс» — ознакомительный отрывок электронной книги совершенно бесплатно, а после прочтения отрывка купить полную версию. В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Город: Москва, Год выпуска: 2020, ISBN: 2020, Издательство: Альпина Паблишер, Жанр: Базы данных, на русском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.

- Название:Наука о данных. Базовый курс
- Автор:
- Издательство:Альпина Паблишер
- Жанр:
- Год:2020
- Город:Москва
- ISBN:978-5-9614-3378-4
- Рейтинг книги:3 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
Наука о данных. Базовый курс: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «Наука о данных. Базовый курс»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
Книга знакомит с основами науки о данных. В ней охватываются все ключевые аспекты, начиная с истории развития сбора и анализа данных и заканчивая этическими проблемами, связанными с конфиденциальностью информации. Авторы объясняют, как работают нейронные сети и машинное обучение, приводят примеры анализа бизнес-проблем и того, как их можно решить, рассказывают о сферах, на которые наука о данных окажет наибольшее влияние в будущем.
«Наука о данных» уже переведена на японский, корейский и китайский языки.
Наука о данных. Базовый курс — читать онлайн ознакомительный отрывок
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «Наука о данных. Базовый курс», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
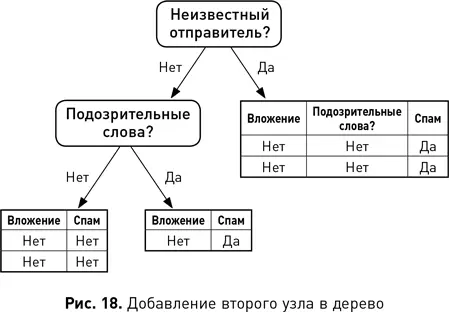
Наконец, поскольку алгоритмы обучения дерева решений многократно разветвляют набор данных, то, когда дерево становится большим, повышается его чувствительность к шуму (например, к ошибочно помеченным объектам). Это происходит потому, что подмножества примеров в каждой ветви становятся все меньше и, следовательно, выборка данных, на которой основано правило классификации, тоже уменьшается. Чем меньше выборка данных, тем более чувствительным к шуму становится правило. Поэтому неглубокие деревья решений — это хорошая идея. Один метод заключается в том, чтобы остановить рост ветви, как только число объектов в ней станет меньше предварительно определенного порога (например, 20 объектов). Другие методы позволяют дереву расти, но потом обрезают его. В таких методах для определения ветвей в нижней части дерева, которые следует удалить, обычно используются статистические тесты или производительность модели на наборе данных, специально предназначенных для этой задачи.
Смещения в науке о данных
Цель машинного обучения — создание моделей, которые кодируют соответствующие обобщения из наборов данных. Есть два основных фактора, которые делают генерируемое алгоритмом обобщение (или модель) более ценным. Первый — это набор данных, на котором работает алгоритм. Если он не является репрезентативным для совокупности, то модель, которую генерирует алгоритм, не будет точной. Например, ранее мы разработали регрессионную модель, которая предсказывала вероятность того, что у человека разовьется диабет 2-го типа, на основе его ИМТ. Эта модель была сгенерирована из набора данных белых американских мужчин. Следовательно, эта модель вряд ли будет точной, если она используется для прогнозирования вероятности развития диабета для женщин или мужчин, принадлежащих другим расам или этническим группам. Термин « смещение выборки» описывает то, как процесс, используемый для формирования набора данных, может внести искажения в последующую аналитику, будь то статистический анализ или создание прогностических моделей с использованием машинного обучения.
Вторым фактором, который влияет на модель, генерируемую из набора данных, является выбор алгоритма машинного обучения. Их существует множество, и каждый кодирует свой способ обобщения набора данных. Тип обобщения, который кодирует алгоритм, известен как смещение обучения (или смещение выбора) алгоритма. Например, алгоритм линейной регрессии кодирует линейное обобщение и в результате игнорирует другие нелинейные отношения, которые могут более точно соответствовать данным. Смещение обычно понимается как нечто нежелательное. Например, рассмотренное выше смещение выборки является примером смещения, которого специалист по данным постарается избежать. Тем не менее без смещения обучение невозможно, поскольку алгоритм сможет только запоминать данные.
Однако, поскольку алгоритмы машинного обучения смещены для поиска различных типов закономерностей, нет одного наилучшего алгоритма, потому что не может быть наилучшего смещения для всех ситуаций. Так называемая теорема об отсутствии бесплатных завтраков {5} утверждает, что не существует ни одного алгоритма МО, в среднем превосходящего все другие алгоритмы по всем возможным наборам данных. Поэтому этап моделирования процесса CRISP-DM обычно включает в себя построение нескольких моделей с использованием разных алгоритмов и их последующее сравнение, чтобы определить, какой из алгоритмов генерирует наилучшую модель. В сущности, эти эксперименты тестируют, какое смещение обучения в среднем дает лучшие модели для конкретных задач и набора данных.
Оценка моделей: обобщение, а не запоминание
После того как набор алгоритмов выбран, следующая основная задача — создать план тестирования для оценки моделей, сгенерированных этими алгоритмами. Цель плана тестирования — обеспечить, чтобы оценка производительности модели на новых данных была реалистичной. Модель прогнозирования, которая просто запоминает набор данных, вряд ли справится с оценкой значений для новых примеров. Во-первых, при простом запоминании данных большинство наборов будут содержать шум и модель прогнозирования также будет запоминать шум в данных. Во-вторых, простое запоминание сводит процесс прогнозирования к поиску в таблице и оставляет нерешенной проблему, как обобщить обучающие данные для работы с новыми примерами, которых нет в таблице.
Читать дальшеИнтервал:
Закладка:
Похожие книги на «Наука о данных. Базовый курс»
Представляем Вашему вниманию похожие книги на «Наука о данных. Базовый курс» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.











Обсуждение, отзывы о книге «Наука о данных. Базовый курс» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.