Никита Сергеев - Аналитика и Data Science. Для не-аналитиков и даже 100% гуманитариев…
Здесь есть возможность читать онлайн «Никита Сергеев - Аналитика и Data Science. Для не-аналитиков и даже 100% гуманитариев…» — ознакомительный отрывок электронной книги совершенно бесплатно, а после прочтения отрывка купить полную версию. В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. ISBN: , Жанр: popular_business, Прочая научная литература, на русском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.

- Название:Аналитика и Data Science. Для не-аналитиков и даже 100% гуманитариев…
- Автор:
- Жанр:
- Год:неизвестен
- ISBN:9785005007346
- Рейтинг книги:5 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
Аналитика и Data Science. Для не-аналитиков и даже 100% гуманитариев…: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «Аналитика и Data Science. Для не-аналитиков и даже 100% гуманитариев…»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
Аналитика и Data Science. Для не-аналитиков и даже 100% гуманитариев… — читать онлайн ознакомительный отрывок
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «Аналитика и Data Science. Для не-аналитиков и даже 100% гуманитариев…», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
Понять «на глаз» нормально ли распределены данные на самом деле может быть достаточно сложно. Бывает внешне похожее на нормальное распределение значимо от него отличается. А бывает наоборот – визуально не выглядящее нормальным распределение не имеет значимых отличий от нормального.
Поэтому для определения «нормальности» распределения разработаны специальные статистические тесты. Мы на этом остановимся позже в практических разделах книги.
Итоги раздела
В этом разделе основные мысли, которые хотелось бы «осадить» в памяти читателя, следующие:
1. Есть описательная и аналитическая статистика. Описательная статистика «ужимает» миллионы и миллиарды цифр к какому-то компактному числу, типичному для всего миллиона цифр. Аналитика позволяет находить скрытые закономерности, которые дают нам больше понимания о реальности и как она работает, а также строить прогнозы.
2. Выборка и генеральная совокупность. Генеральная совокупность – вся целиком популяция исследуемых объектов. Выборка – выбранные из этой популяции объекты (часть генеральной совокупности). Но выборка должна быть репрезентативной – т.е., отражать генеральную совокупность.
3. Переменные – это признаки / характеристики изучаемых нами объектов (люди, животные, товар, клиенты, организации и т.д.), которые могут принимать разные значения. Доход, пол, возраст, цвет и т. д.
4. В практике стоит различать три типа шкал для измерения переменных. Номинальная:шкала наименований – город, пол, профессия и т. д. Ординальная / порядковая:отражающая степень проявления какого-либо свойства, без точных измерений – высокий-низкий; больше-меньше; I – II – III место и т. д. Интервальная:отражает размерность или масштаб каждой переменной – доход, возраст в годах, расстояние и т. д.
5. Мы выдвигаем наши предположения / суждения (как в виде мнений или домыслов, так и опыта) в виде гипотез, которые потом проверяем цифрами и аналитикой. В статистике фигурируют две гипотезы. Нулевая гипотеза (H 0), гласящая что закономерностей, взаимосвязей, различий в генеральной совокупности не существует – все что мы обнаружили всего лишь нелепая случайность в нашей выборке. И альтернативная (H 1), которая гласит, что обнаруженные в выборке различия нельзя объяснить случайностью: они вероятнее всего имеют место и «материальны» в генеральной совокупности.
6. Практическая статистика оперирует не вероятностью наступления события (или истинности утверждения), а вероятностью ошибиться в случае применения обнаруженной закономерности ко всей генеральной совокупности. Самым страшным и критичным в анализе считается именно обнаружить закономерности, взаимосвязи или различия, которых на самом деле в генеральной совокупности не существует.
7. Все закономерности (взаимосвязи, различия), по которым вероятность ошибки относительно их отсутствия в генеральной совокупности менее 5% (менее 0,05), считаются статистически значимыми.
8. В социально-экономической реальности Вы редко будете встречать нормальное распределение. Оно будет скорее скошено вправо или влево, или очень сжато к оси ОХ или ОY. 90% жителей страны владеют 2% капитала, 2 певца забирают 95% популярности, 99% тиража всех книг приходится на 1% авторов и т. д.
КРАТКО О ПОДГОТОВКЕ МАССИВА ДАННЫХ ДЛЯ АНАЛИЗА
Что такое массив данных
Массивом данных для пользователей как мы с Вами по большому счету является таблица, в которую внесены данные. Главное: в массиве все данные по той или иной переменной должны соотноситься с конкретным случаем, объектом, процессом, явлением.
Строки таблицы – это случаи или объекты (ФИО, завод, филиал, клиент и т.д.).
Столбцы\Колонки – это наши переменные, то есть характеристики этих случаев или объектов (доход, % брака, возраст, пол, страна и т.д.).
Массивом для последующей аналитической обработки является «плоская» таблица (не сведенный отчет). См. рис. 18 .
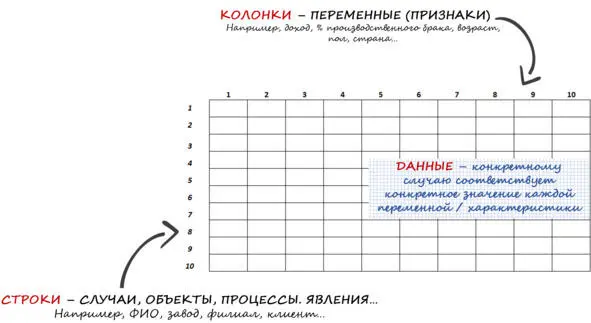
Рис. 18. Базовая структура массива данных
В массивах по строкамидут случаи / объекты / процессы (компания, дата замера, человек, клиент и т.д.), а по столбцам\колонкам – исследуемые переменные с их значениямидля этих случаев / объектов / процессов по ячейкам.
Читать дальшеИнтервал:
Закладка:
Похожие книги на «Аналитика и Data Science. Для не-аналитиков и даже 100% гуманитариев…»
Представляем Вашему вниманию похожие книги на «Аналитика и Data Science. Для не-аналитиков и даже 100% гуманитариев…» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.

![Роман Зыков - Роман с Data Science. Как монетизировать большие данные [litres]](/books/438007/roman-zykov-roman-s-data-science-kak-monetizirova-thumb.webp)









Обсуждение, отзывы о книге «Аналитика и Data Science. Для не-аналитиков и даже 100% гуманитариев…» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.