Никита Сергеев - Аналитика и Data Science. Для не-аналитиков и даже 100% гуманитариев…
Здесь есть возможность читать онлайн «Никита Сергеев - Аналитика и Data Science. Для не-аналитиков и даже 100% гуманитариев…» — ознакомительный отрывок электронной книги совершенно бесплатно, а после прочтения отрывка купить полную версию. В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. ISBN: , Жанр: popular_business, Прочая научная литература, на русском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.

- Название:Аналитика и Data Science. Для не-аналитиков и даже 100% гуманитариев…
- Автор:
- Жанр:
- Год:неизвестен
- ISBN:9785005007346
- Рейтинг книги:5 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
Аналитика и Data Science. Для не-аналитиков и даже 100% гуманитариев…: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «Аналитика и Data Science. Для не-аналитиков и даже 100% гуманитариев…»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
Аналитика и Data Science. Для не-аналитиков и даже 100% гуманитариев… — читать онлайн ознакомительный отрывок
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «Аналитика и Data Science. Для не-аналитиков и даже 100% гуманитариев…», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
Тогда задача сводится к обратному: зная размер генсовокупности и выборки – рассчитать доверительный интервал, чтобы понимать, насколько полученные в выборке данные ± могут отличаться в генеральной совокупности.
Имея размер генеральной совокупности и количество заполненных анкет (выборка) можно рассчитать доверительный интервал (те наши ±%) для того или иного % ответов определенной категории.
Например, если в компании 5.000 сотрудников, а сдали анкеты только 3.250, то при доверительной вероятности 95% доверительный интервал будет ±1,02%. Считается это также в онлайн калькуляторах. Пример, как выглядят такие онлайн калькуляторы в сети Интернет на рис.10.1 :
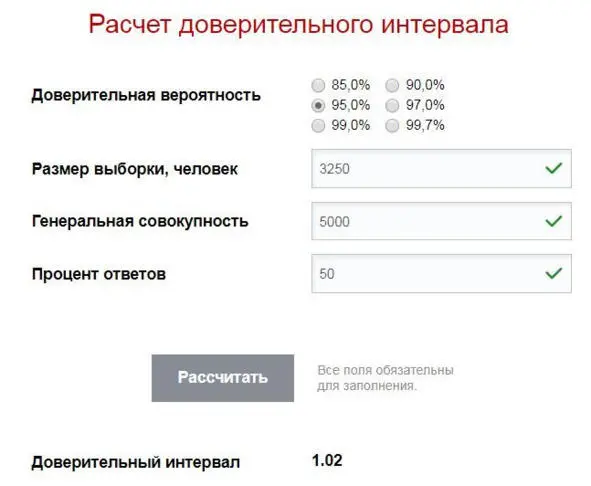
Рис.10.1. Пример онлайн калькулятора расчета доверительного интервала
Но в расчете доверительного интервала есть один нюанс по поводу поля «Процент ответов».
Внимательно читаем:рассчитанный доверительный интервал будет справедливым для альтернатив ответов сотрудников, которые набрали 50%. Для альтернатив, которые набрали другие % – доверительный интервал будет другим .
Например, Вы задали сотрудникам такой компании вопрос «Довольны ли Вы стилем менеджмента в компании?» с тремя вариантами ответа и такими % ответов персонала:
· Доволен – 50%
· Насколько доволен, настолько недоволен – 15%
· Недоволен – 35%
В данном случае, доверительный интервал (или ошибка выборки) будет ±1,02% будет справедлива только для «довольных» – т.е. доля довольных будет в диапазоне 50±1,02% (от 48,98 до 51,02).
Но для средней альтернативы доверительный интервал (или ошибка выборки) будет ±0,73%.
А для «недовольных» ±0,97%.
Т.е, подставляя в поле «Процент ответов» разные значения альтернатив в зависимости от % отметивших их сотрудников, мы будем получать разные значения доверительного интервала для альтернатив.
На практике, если в целом ошибка выборки (значения доверительно интервала) Вас устраивает в целом для «Процент ответов» 50, то далее просто смотрят полученные % ответов.
Переменные
Данные обычно состоят из большого количества отдельных показателей, которые называют переменными. Это, например, доход, количество клиентов, город или страна, отдел, род войск, зарплата, пол, частота курения, количество посещений или часов порносайтов, частота занятия сексом в неделю, количество детей, социальный статус и т. д.
Переменная имеет свое значение для того или иного объекта /случая / наблюдения.
По большому счету переменная – это характеристика объекта / случая / наблюдения. Например, цвет глаз у каждого человека будет свой.
Т.о., каждый случай, объект или наблюдение имеют свои характеристики, т.е., имеет свое значение той или иной переменной. Переменные описывают объект.
Например, на рис. 11 в качестве примера приведены Валя и Иван – это объекты / случаи / наблюдения.

Рис. 11. Объекты и переменные
А их рост, цвет глаз, доход, место проживания, частота путешествий и другие характеристики – это переменные.
Например,
· Валя -женщина, Иван – мужчина.
· Рост Вали = 1,7 метра, а Ивана 1,82.
· У Вали глаза голубые, у Ивана зеленые.
· Валя живет в Омске, Иван в Москве.
· Месячный доход Вали – 80.000 руб, а Ивана – 200.000 руб.
· Валя ездит на отдых за границу редко – раз в несколько лет, Иван часто – несколько раз в год.
Шкалы для измерения переменных
Каждая переменная может принимать различные значения. Значения переменных варьируются и отличаются от случая к случаю, от объекта к объекту.
Ну и Вы уже наверняка заметили, что они могут быть измерены в различных шкалах.
Например, пол – 0 и 1 или 1 и 0. Т.е, мужчина или женщина.
Доход, который выражается в рублях и может принимать большое количество разных значений, хоть до копеек.
Или частота поездок за границу, курения, использования интернета…
Разные шкалы имеют разную информативность. От того, какая шкала используется, зависят также и методы анализа, которые к ней можно применять.
Статисты придумали разные типы шкал (см. рис.) но их в целом можно объединить в три основных типа, которые в книге приводятся в порядке возрастания информативности:
Читать дальшеИнтервал:
Закладка:
Похожие книги на «Аналитика и Data Science. Для не-аналитиков и даже 100% гуманитариев…»
Представляем Вашему вниманию похожие книги на «Аналитика и Data Science. Для не-аналитиков и даже 100% гуманитариев…» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.

![Роман Зыков - Роман с Data Science. Как монетизировать большие данные [litres]](/books/438007/roman-zykov-roman-s-data-science-kak-monetizirova-thumb.webp)









Обсуждение, отзывы о книге «Аналитика и Data Science. Для не-аналитиков и даже 100% гуманитариев…» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.