Сергей Зыков - Основы проектирования корпоративных систем
Здесь есть возможность читать онлайн «Сергей Зыков - Основы проектирования корпоративных систем» — ознакомительный отрывок электронной книги совершенно бесплатно, а после прочтения отрывка купить полную версию. В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Город: Москва, Год выпуска: 2012, ISBN: 2012, Издательство: Array Литагент «Высшая школа экономики», Жанр: economics, management, на русском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.

- Название:Основы проектирования корпоративных систем
- Автор:
- Издательство:Array Литагент «Высшая школа экономики»
- Жанр:
- Год:2012
- Город:Москва
- ISBN:978-5-7598-0862-6
- Рейтинг книги:5 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
Основы проектирования корпоративных систем: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «Основы проектирования корпоративных систем»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
Для студентов, аспирантов и исследователей, а также специалистов-практиков, область интересов которых связана с разработкой крупномасштабных программных систем.
Основы проектирования корпоративных систем — читать онлайн ознакомительный отрывок
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «Основы проектирования корпоративных систем», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
В трехзвенном клиент-сервере взаимодействие происходит более сложным образом. Между веб-сервером и источником данных появляется еще один уровень, реализующий прикладную логику на основе программных расширений. Информация в формате HTML от веб-браузера преобразуется к виду, который может быть транслирован в SQL-запрос, который выполняет SQL-сервер. После этого происходит обратное преобразование в HTML и передача его клиенту. Используются программы-расширения CGI-скрипты, API. Основная цель для трехзвенной клиент-серверной архитектуры – за счет взаимодействия по стандартным протоколам осуществить специализацию деятельности компонентов. И за счет этой специализации ускоряется обработка запросов. Отдельно выделяется задача поддержания соединения с БД для минимизации сетевого трафика. Кроме того, для обеспечения масштабируемости необходимо поддерживать резерв в соединении с БД для того, чтобы в пиковый период увеличить нагрузку. Стандартизация компонентов дает возможность инкрементально наращивать функциональность отдельных систем.
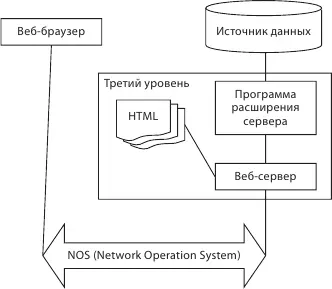
Рис. 6.8.Трехуровневая архитектура клиент – сервер в сетях Интернет/интранет
Кроме традиционных корпоративных систем стоит рассмотреть системы, не являющиеся корпоративными с точки зрения решаемых бизнес-задач. Речь идет о системах, которые поддерживают на уровне государств функционирование достаточно важных информационных служб, например электронное правительство или система, объединяющая различные модели данных и построенные на их основе базы данных. В ряде случаев необходимо использовать не только реляционные базы данных, но и современные объектно-ориентированные модели данных, которые в чисто реляционные таблицы не вполне укладываются исходя из динамического характера объектов и ряда других факторов. Имеются как теоретические, так и удовлетворительные практические результаты в объединении неоднородных источников данных. При этом возможны различные подходы к интеграции неоднородных баз данных. Это можно осуществить путем разработки новых моделей данных, которые объединяют различные подходы к хранению данных (реляционный, сетевой, иерархический, объектно-ориентированный) на основе чисто объектных моделей. Другой подход основан на преобразовании языков манипулирования данными (аналогичных SQL) для взаимодействия с данными, которые хранятся в нереляционных форматах, создании адаптеров для такого рода нереляционных СУБД. При интеграции подобных систем в глобальную среду сетевых коммуникаций, в интернет-среду важной проблемой становится обработка достаточно сложных запросов. Важными аспектами такой интеграции является управление транзакциями на глобальном уровне. Это сложная и многоплановая задача. Сложность вызывает оптимизация запросов, если речь идет об использовании разного рода баз данных для ответов на запросы, а кроме того, администрирование этих данных, ведение журнала, аудит пользователей для получения консолидированных отчетов по безопасности.
Зачастую пользователи этих систем не могут открыть все свои данные в федеративные системы защиты. Выходом является формирование мультибаз данных, которые сохраняют локальную автономность, т. е. для ряда систем имеет место лишь частичная интеграция в федеративные системы. Глобальной схемы данных пользователями не предоставляется, доступ дается в ограниченном виде или особыми способами с механизмами защиты.
Другим интересным направлением в развитии корпоративных систем с базами данных является их взаимодействие с GRID-системами, которые представляют собой глобальные высокопроизводительные сети для вычислений над большими объемами данных в короткие сроки. В ряде случаев такие объемы данных накапливались годами и измеряются терабайтами. Интеграция гетерогенных информационных систем в мультибазы данных и их взаимодействие с GRID являются перспективными направлениями исследований. При этом интерес представляет как построение моделей данных в основном на основе объектов для поддержки этих интегрированных систем, так и разработка средств реализации такого рода систем, в том числе специализированных адаптеров для известных систем, чтобы появилась возможность интегрировать вновь создаваемые системы в существующие среды.
GRID-системы – это системы распределенных вычислений, отличные от традиционных корпоративных СУБД. В ряде корпораций уже есть примеры использования таких систем. Под этим термином понимается глобально распределенная сеть, которая в отличие от корпоративных систем должна обеспечивать очень высокую производительность, дающую возможность обычным компьютерам соперничать в производительности с супер-ЭВМ. В ряде отраслей знания есть потребность хранения и обработки терабайтных объемов данных. Это нужно в биологии для анализа ДНК, в медицине для компьютерной томографии в реальном времени и анализа развития онкологических заболеваний, в геофизике для анализа спутниковых данных об атмосферных явлениях, в астрономии для анализа динамики космических тел, в физике элементарных частиц для анализа данных с ускорителей, в криптографии, вычислениях (константы пи). Характерные скорости поступления информации в таких системах – 100 Мб/с.
Читать дальшеИнтервал:
Закладка:
Похожие книги на «Основы проектирования корпоративных систем»
Представляем Вашему вниманию похожие книги на «Основы проектирования корпоративных систем» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.












Обсуждение, отзывы о книге «Основы проектирования корпоративных систем» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.