Дуглас Хаббард - Как измерить все, что угодно [Оценка стоимости нематериального в бизнесе]
Здесь есть возможность читать онлайн «Дуглас Хаббард - Как измерить все, что угодно [Оценка стоимости нематериального в бизнесе]» весь текст электронной книги совершенно бесплатно (целиком полную версию без сокращений). В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Город: Москва, Год выпуска: 2009, ISBN: 2009, Издательство: Олимп-Бизнес, Жанр: economics, на русском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.
![Дуглас Хаббард Как измерить все, что угодно [Оценка стоимости нематериального в бизнесе] обложка книги](/books/393412/duglas-habbard-kak-izmerit-vse-chto-ugodno-ocenk.webp)
- Название:Как измерить все, что угодно [Оценка стоимости нематериального в бизнесе]
- Автор:
- Издательство:Олимп-Бизнес
- Жанр:
- Год:2009
- Город:Москва
- ISBN:978-5-9693-0163-4
- Рейтинг книги:4 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
Как измерить все, что угодно [Оценка стоимости нематериального в бизнесе]: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «Как измерить все, что угодно [Оценка стоимости нематериального в бизнесе]»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
Дуглас Хаббард пытается развеять это вредное заблуждение, предлагая свой подход к оценке «неизмеряемого», названный им «прикладная информационная экономика». Он знакомит читателей с понятием «калиброванная оценка», оценкой риска (метод Монте-Карло), способами выборочного исследования, другими необычными инструментами измерений (Интернет, экспертные оценки, рынки предсказаний и др.), а также с оценкой стоимости информации. Свой подход автор применяет в разных областях и приводит ряд примеров успешного решения задач по количественному измерению. В книге содержатся ценные инструкции и рекомендации, которые без труда может использовать любой человек, принимающий решения, а также приложения, позволяющие проверить способность читателя давать калиброванные оценки.
Книга предназначена широкому кругу читателей, интересующихся процессами обоснования и принятия решений. Она будет полезна руководителям, менеджерам, преподавателям и студентам.
Как измерить все, что угодно [Оценка стоимости нематериального в бизнесе] — читать онлайн бесплатно полную книгу (весь текст) целиком
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «Как измерить все, что угодно [Оценка стоимости нематериального в бизнесе]», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
К проведению опроса приступили еще до начала тренинга, чтобы представить себе исходное положение дел. Из клиентов каждого сотрудника службы отбирали только одного. Главный вопрос был сформулирован так: «Какова вероятность, что вы порекомендуете нас своим друзьям, учитывая свой опыт обращения в службу поддержки?» В случае высокой вероятности такого поступка респонденты должны были выбрать цифру 1, если мнение о работе службы не изменилось — цифру 2, а в случае малой вероятности — 3. Каждому ответу присваивался соответствующий балл (1, 2, 3). Зная результаты некоторых предыдущих исследований роста продаж в результате повышения удовлетворенности потребителей, отдел маркетинга определил, что улучшение среднего балла ответов на этот вопрос на 0,1 пункта приведет к повышению объема реализации на 2 %.
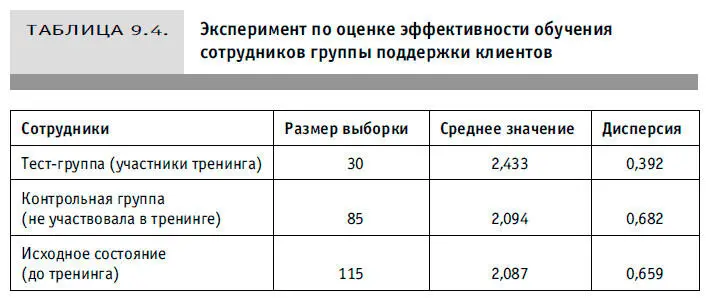
Тренинг, о котором идет речь, был не из дешевых, поэтому сначала руководство решило послать на обучение 30 случайным образом выбранных сотрудников службы поддержки потребителей в качестве группы испытуемых. Тем не менее затраты на обучение этой группы оказались существенно меньше рассчитанной стоимости информации. В контрольную группу вошли все остальные сотрудники службы. После того, как тест-группа прошла программу тренинга, менеджеры продолжили опрос покупателей, осуществив выборочное обследование по принципу, описанному выше. Были рассчитаны среднее значение и дисперсия исходных данных по группе испытуемых и контрольной группе (как это показано в примере с леденцами в начале главы). Результаты расчетов представлены в таблице 9.4.
Ответы респондентов вроде бы продемонстрировали, что обучение дало эффект; но не является ли эта картина просто случайностью? Может быть, 30 случайным образом выбранных сотрудников уже работали лучше, чем персонал в среднем, или этим 30 случайно пришлось иметь дело с менее «трудными» покупателями? Пересчитаем полученные результаты обеих групп следующим образом:
1. Разделим дисперсию выборки каждой группы на размер выборки. Получим: 0,392 / 30 = 0,0131 для группы испытуемых и 0,682 / 85= 0,008 для контрольной группы.
2. Сложим полученные для каждой группы результаты: 0,0131 + 0,008 = 0,021.
3. Извлечем из полученного числа квадратный корень. Так мы получим среднее квадратичное отклонение разницы между группами. В данном случае она составит 0,15.
4. Рассчитаем разницу между средними значениями двух сравниваемых групп: 2,433–2,094 = 0,339.
5. Рассчитаем теперь вероятность того, что разница между группой испытуемых и контрольной группой больше 0, то есть группа испытуемых показала действительно, а не случайно, лучшие результаты, чем контрольная группа. Используем для этого расчета формулу normdist в Excel:
=normdist(0, 0,339, 0,15, 1)
и получим вероятность, равную 0,01.
Таким образом, существует вероятность всего 1 % того, что сравниваемые группы одинаково хороши или плохи. Значит, мы можем быть на 99 % уверены, что люди, прошедшие тренинг, действительно работают лучше остальных сотрудников службы.
Аналогично можно сравнить контрольную группу с исходным состоянием. Разница между ними составляет всего 0,007. Применив метод, только что использованный нами для сравнения тест-группы и контрольной группы, найдем, что есть 48-процентная вероятность того, что контрольная группа работает хуже исходного состояния, или 52-процентная вероятность того, что лучше. Таким образом, различие между этими группами пренебрежимо мало, а для всех практических целей его вообще не существует.
Мы определили с высокой степенью уверенности, что тренинг способствует повышению удовлетворенности потребителей. Поскольку разница между группой испытуемых и контрольной группой составляет около 0,4, отдел маркетинга пришел к выводу: обучение приведет к росту продаж примерно на 8 %. Это означает, что затраты на обучение всего персонала экономически целесообразны. Вспомним, что мы вполне могли бы взять и меньшую выборку, воспользовавшись t-распределением Стьюдента для выборок размером до 30.
Выявление взаимозависимости параметров: введение в регрессионное моделирование
На семинарах мне часто задают примерно такой вопрос: «Если благодаря внедрению новой информационной системы продажи увеличатся, то откуда мы будем знать, что это произошло благодаря именно этой системе?» Просто удивительно, как часто этот вопрос возникает при том, что последние несколько столетий специалисты по научным измерениям только и делают, что пытаются выделить эффект одной переменной. Могу лишь предположить, что эти люди незнакомы с основными понятиями научного измерения. Приведенный ранее в этой главе пример эксперимента ясно показывает: то, что объясняется многими причинами, вполне можно проследить до одного-единственного фактора влияния, сравнивая тест-группу с контрольной группой. На самом деле использование этих групп — лишь один из имеющихся способов выделения эффекта одной переменной из всей массы информации, существующей в любой компании. Другой способ — рассмотреть, насколько одна переменная коррелирует с другой.
Читать дальшеИнтервал:
Закладка:
Похожие книги на «Как измерить все, что угодно [Оценка стоимости нематериального в бизнесе]»
Представляем Вашему вниманию похожие книги на «Как измерить все, что угодно [Оценка стоимости нематериального в бизнесе]» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.











Обсуждение, отзывы о книге «Как измерить все, что угодно [Оценка стоимости нематериального в бизнесе]» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.