Дуглас Хаббард - Как измерить все, что угодно [Оценка стоимости нематериального в бизнесе]
Здесь есть возможность читать онлайн «Дуглас Хаббард - Как измерить все, что угодно [Оценка стоимости нематериального в бизнесе]» весь текст электронной книги совершенно бесплатно (целиком полную версию без сокращений). В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Город: Москва, Год выпуска: 2009, ISBN: 2009, Издательство: Олимп-Бизнес, Жанр: economics, на русском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.
![Дуглас Хаббард Как измерить все, что угодно [Оценка стоимости нематериального в бизнесе] обложка книги](/books/393412/duglas-habbard-kak-izmerit-vse-chto-ugodno-ocenk.webp)
- Название:Как измерить все, что угодно [Оценка стоимости нематериального в бизнесе]
- Автор:
- Издательство:Олимп-Бизнес
- Жанр:
- Год:2009
- Город:Москва
- ISBN:978-5-9693-0163-4
- Рейтинг книги:4 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
Как измерить все, что угодно [Оценка стоимости нематериального в бизнесе]: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «Как измерить все, что угодно [Оценка стоимости нематериального в бизнесе]»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
Дуглас Хаббард пытается развеять это вредное заблуждение, предлагая свой подход к оценке «неизмеряемого», названный им «прикладная информационная экономика». Он знакомит читателей с понятием «калиброванная оценка», оценкой риска (метод Монте-Карло), способами выборочного исследования, другими необычными инструментами измерений (Интернет, экспертные оценки, рынки предсказаний и др.), а также с оценкой стоимости информации. Свой подход автор применяет в разных областях и приводит ряд примеров успешного решения задач по количественному измерению. В книге содержатся ценные инструкции и рекомендации, которые без труда может использовать любой человек, принимающий решения, а также приложения, позволяющие проверить способность читателя давать калиброванные оценки.
Книга предназначена широкому кругу читателей, интересующихся процессами обоснования и принятия решений. Она будет полезна руководителям, менеджерам, преподавателям и студентам.
Как измерить все, что угодно [Оценка стоимости нематериального в бизнесе] — читать онлайн бесплатно полную книгу (весь текст) целиком
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «Как измерить все, что угодно [Оценка стоимости нематериального в бизнесе]», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
Однако у Guinness уже были проблемы с разглашением коммерческой тайны, и служащим компании было запрещено публиковать любую информацию о бизнес-процессах. Госсет понимал значение своей работы, но ему сильнее хотелось рассказать о своей идее, чем добиться немедленного признания. Поэтому он опубликовал статью под псевдонимом «Стьюдент». И хотя истинный автор давно известен, практически во всех работах по статистике метод называется t-статистикой Стьюдента.
Вид распределения Стьюдента напоминает обсуждавшееся нами ранее нормальное распределение. Но в случае очень малых выборок его форма становится намного уплощеннее и шире. Рассчитанный с помощью t-статистики 90-процентный CI намного шире (то есть неопределеннее), чем в случае нормального распределения. Если размер выборки больше 30, то график t-распределения практически совпадает с нормальным распределением.
И для одного, и для другого типа распределения существует сравнительно простой (по сравнению со многими другими статистическими методами) способ расчета 90-процентного доверительного интервала для среднего значения генеральной совокупности. Кому-то наши расчеты могут показаться слишком сложными, а те, кто уже знаком с данным методом, скажут, что мы просто пересказываем содержание учебников по статистике. Пусть первые подождут, пока мы не рассмотрим в следующей главе намного более простое решение, а вторые просто пропустят этот материал. Адресуя свои пояснения читателям, которые отнесут себя к средней категории, я старался сделать их как можно более простыми для восприятия. Вот как мы могли рассчитать 90-процентный CI в предыдущем примере, отобрав всего пять леденцов.
1. Рассчитаем сначала дисперсию выборки (этим понятием мы позднее будем часто пользоваться):
а) рассчитаем средний вес отобранных леденцов: (1,4 + 1,4 + 1,5 + 1,6 + 1,1)/5 = 1,4;
б) вычтем это среднее из каждого значения в выборке и возведем полученные результаты в квадрат: (1,4–1,4) 2= 0; (1,5–1,4) 2= 0,01 2и т. д.;
в) суммируем все квадраты и разделим на размер выборки минус единица: (0 + 0 + 0,01 + 0,04 + 0,09)/(5–1) = 0,035.
2. Разделим дисперсию выборки на ее размер и извлечем из полученного результата квадратный корень. В электронной таблице мы записали бы «=SQRT (0,035/5)» и получили 0,0837.
(В работах по статистике это называется средним квадратичным отклонением.)
3. Найдем в таблице 9.1 (таблице упрощенных значений t-статистики) значение t, соответствующее размеру выборки: для выборки, состоящей из пяти объектов, t = 2,13. Обратите внимание, что для очень больших выборок t близко к z-значению (нормальное распределение) 1,645.
4. Умножим найденное t-значение на результат этапа 2: 2,13 × 0,0837 = 0,178. Это ошибка выборки в граммах.
5. Суммируем ошибку выборки и средний вес леденца, чтобы получить верхнюю границу 90-процентного CI, а затем вычтем ее из среднего веса, чтобы получить нижнюю границу: верхняя граница = 1,4 + 0,178 = 1,578; нижняя граница = 1,4–0,178 = 1,222.
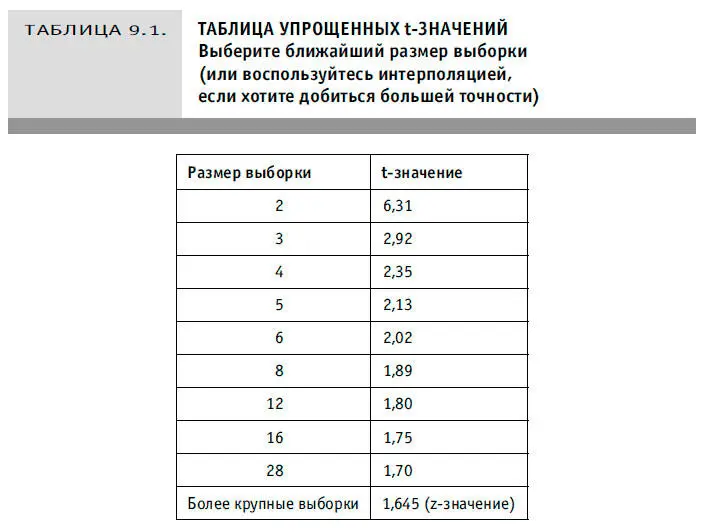
Итак, выбрав всего пять леденцов, мы получили 90-процентный CI, составляющий 1,222–1,578. Аналогично рассчитывают доверительный интервал и для более крупных выборок. Единственная разница заключается в том, что z-значение, необходимое для этого, всегда будет составлять 1,645 (с ростом размера выборки оно не увеличится).
На рисунке 9.1 представлен общий результат решения другой гипотетической задачи с использованием t-статистики. Это могло быть определение средней партии пива, сваренного в компании Guinness, среднего времени, проводимого покупателями в очередях, или среднего размера обуви жителей штата Небраска. В любом случае необходимо определить 90-процентный CI для среднего значения генеральной совокупности, хотя по каким-то причинам (экономические факторы, ограниченность во времени или несогласие жителей штата Небраска на измерение размеров их ног) размер выборки из подобных совокупностей составлял бы не десятки и сотни, а всего несколько образцов.
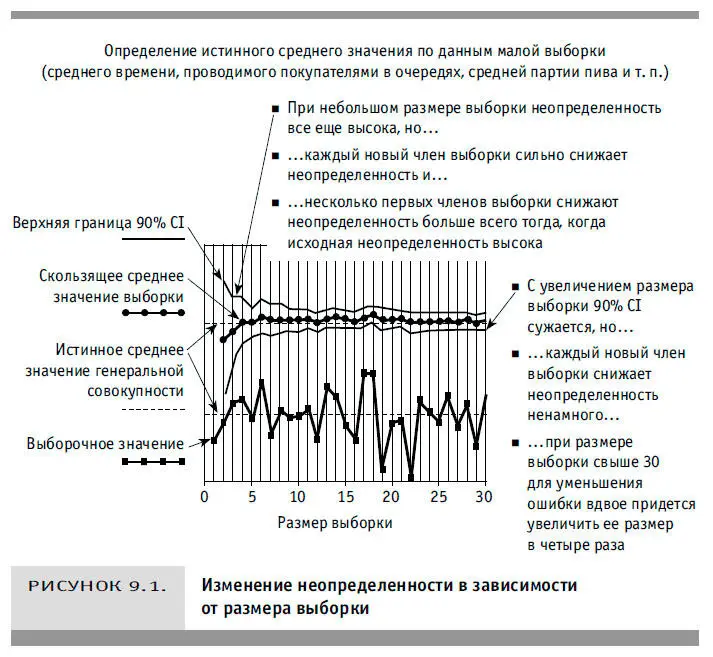
На этом рисунке нижняя ломаная линия — график значений выборки, пунктир — истинное среднее значение генеральной совокупности. Одни значения выборки выше этого среднего, другие ниже. Фактических значений на рисунке нет, но для наших целей смысл понятен. В верхней части рисунка вы видите три кривые, левые края которых образуют своеобразную «воронку торнадо». Средняя линия — график скользящей средней выборки (сначала среднее из первых трех значений, затем среднее из первых четырех значений и т. д.), которая сравнивается с истинным средним генеральной совокупности, представленным прямой пунктирной линией. Две внешние кривые — графики верхней и нижней границ 90-процентного доверительного интервала, пересчитываемого после каждого нового пополнения выборки.
Читать дальшеИнтервал:
Закладка:
Похожие книги на «Как измерить все, что угодно [Оценка стоимости нематериального в бизнесе]»
Представляем Вашему вниманию похожие книги на «Как измерить все, что угодно [Оценка стоимости нематериального в бизнесе]» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.











Обсуждение, отзывы о книге «Как измерить все, что угодно [Оценка стоимости нематериального в бизнесе]» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.