Carol A. Chapelle - The Concise Encyclopedia of Applied Linguistics
Здесь есть возможность читать онлайн «Carol A. Chapelle - The Concise Encyclopedia of Applied Linguistics» — ознакомительный отрывок электронной книги совершенно бесплатно, а после прочтения отрывка купить полную версию. В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Жанр: unrecognised, на английском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.

- Название:The Concise Encyclopedia of Applied Linguistics
- Автор:
- Жанр:
- Год:неизвестен
- ISBN:нет данных
- Рейтинг книги:5 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
The Concise Encyclopedia of Applied Linguistics: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «The Concise Encyclopedia of Applied Linguistics»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
Applied linguistics is an interdisciplinary field that identifies, examines, and seeks solutions to real-life language-related issues. Such issues often occur in situations of language contact and technological innovation, where language problems can range from explaining misunderstandings in face-to-face oral conversation to designing automated speech recognition systems for business.
includes entries on the fundamentals of the discipline, introducing readers to the concepts, research, and methods used by applied linguists working in the field. This succinct, reader-friendly volume offers a collection of entries on a range of language problems and the analytic approaches used to address them.
This abridged reference work has been compiled from the most-accessed entries from
(www.encyclopediaofappliedlinguistics.com)
the more extensive volume which is available in print and digital format in 1000 libraries spanning 50 countries worldwide. Alphabetically-organized and updated entries help readers gain an understanding of the essentials of the field with entries on topics such as multilingualism, language policy and planning, language assessment and testing, translation and interpreting, and many others.
Accessible for readers who are new to applied linguistics,
:
Includes entries written by experts in a broad range of areas within applied linguistics Explains the theory and research approaches used in the field for analysis of language, language use, and contexts of language use Demonstrates the connections among theory, research, and practice in the study of language issues Provides a perfect starting point for pursuing essential topics in applied linguistics Designed to offer readers an introduction to the range of topics and approaches within the field
is ideal for new students of applied linguistics and for researchers in the field.
The Concise Encyclopedia of Applied Linguistics — читать онлайн ознакомительный отрывок
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «The Concise Encyclopedia of Applied Linguistics», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
SR (and some LP) tasks are typically scored right/wrong for L2 features based on one criterion for correctness (e.g., accurate form). Scoring criteria might involve accuracy, precision, range, complexity, fluency, acceptability, meaningfulness, appropriateness, naturalness, or conventionality. Dichotomous scoring such as this assumes that an item elicits only one underlying dimension of knowledge (e.g., form), that it measures full or no knowledge of the feature, and that item difficulty resides in the interaction between the input and the response key, and not with the distractors.
In other SR or LP tasks, response choices may represent complete knowledge of the feature (e.g., form), partial knowledge , misinformation , or a total lack of knowledge . If the distractors represent “partial” knowledge of the feature, then the use of partial credit scoring should be considered, as dichotomous scoring would deflate test scores by failing to reward examinees for partial knowledge (e.g., Purpura, Dakin, Ameriks, & Grabowski, 2010). In the case of grammaticality judgments, for example, grammatical acceptability depends on what feature is being measured. If knowledge of both form and meaning are required for an acceptable response, then dichotomous scoring would be inappropriate, which is the case in several studies of second language acquisition (SLA) using grammatical judgment tasks. In these cases, right/wrong scoring with multiple areas of correctness or a partial credit scoring method could be used. Partial credit scores are assigned according to the dimensions of knowledge being measured (e.g., 1 point for form + 1 for meaning = 2 points). The measurement of different levels of knowledge can also be accomplished by using an analytic or holistic rubric based on a rating scale such as the following: 0, .3, .6, or 1.
EP tasks vary considerably in the quantity and quality of the response. As a result, they are typically scored with a more comprehensive rating scale (e.g., five‐point rubric: 1 to 5 or five bands from 1 to 10). Rating scales provide hierarchical descriptions of observed behavior associated with different levels of performance related to some construct. The more focused the descriptors are for each rating scale, the greater the potential for measurement precision and feedback utility (see Purpura, 2004). Although rating scales are efficient for many contexts, the information they provide may be too coarse‐grained for other assessment contexts, where detailed feedback is required.
In sum, countless studies in L2 assessment have used these techniques to measure the linguistic resources of L2 communication. These same methods have also been used in mainstream educational measurement to measure other learner characteristics.
A second approach to measuring the linguistic resources of communication is by analyzing selected features of learners' spoken or written production, the assumption being that a characterization of L2 production features can provide evidence not only of the learner's L2 knowledge and in some cases, their ability to communicate propositions, but also of their acquisitional processes, especially if the data are elicited under controlled processing conditions (e.g., planning/no planning; integrated/independent tasks) (Ellis, 2005). This approach has a long tradition in SLA research, where characterizations of the learners' production features during naturalistic or task‐based language use are interpreted as a reflection of the learners' implicit, explicit, or metalinguistic knowledge of the language. For a comprehensive review of data collection procedures and their analyses, see Wolfe‐Quintero, Inagaki, and Kim (1998) and Ellis and Barkhuizen (2005).
In examining the development of writing ability, Wolfe‐Quintero et al. (1998) provided a comprehensive list of measures to examine written production. They defined complexity as “the use of varied and sophisticated structures and vocabulary” (p. 117) in production units. Grammatical complexity involved linguistic features (e.g., subordination) in clause, T‐unit, and sentence production units, measured by the frequency of occurrence of these features (e.g., clauses), by complexity ratios (e.g., T‐units per complexity ratio), and by complexity indices (e.g., coordination index). Lexical complexity was measured by lexical ratios (e.g., word variation/density). Accuracy referred to “error‐free production” (p. 117), measured by the frequency of occurrence of errors or error types within a production unit (e.g., error‐free T‐units), by ratios (e.g., error‐free T‐unit per T‐unit), or by accuracy indices (e.g., error index). Finally, they defined fluency as “the rapid production of language” (p. 117), measured by the frequency of occurrence of specified production units (e.g., words in error‐free clauses) or by fluency ratios (e.g., words per T‐unit or clause).
In a comprehensive book on the analysis of learner data, Ellis and Barkhuizen (2005) produced in one chapter an updated list of analytic measures of CAF (complexity, accuracy, and fluency). Complexity was characterized as interactional (e.g., number of turns, mean turn length), propositional (e.g., number of idea units), functional (e.g., frequency of language functions), grammatical (e.g., amount of subordination), whereas accuracy was measured by the number of errors per 100 words, the percentage of error‐free clauses, and so forth. Finally, fluency was defined as temporal variations (e.g., number of pauses) and hesitation phenomena (e.g., number of false starts).
Several L2 testers have also used production features to characterize different aspects of written and spoken text. Cumming et al. (2006) analyzed the discourse features of independent and integrated written tasks for a large‐scale standardized test. They examined whether and how the discourse features written for integrated tasks differed from those for independent essays. The texts were coded for lexical and syntactic complexity, grammatical accuracy, argument structure, orientation to evidence, and verbatim uses of source text ( Figure 9). They found that the discourse features produced for the integrated writing tasks differed significantly at the lexical, syntactic, rhetorical, and pragmatic levels from those produced for the independent task. Also, significant differences were found among the three tasks across proficiency levels on several variables under investigation.
Knoch, Macqueen, and O'Hagan (2014) replicated and extended Cumming et al.'s (2006) study by examining, first, whether the written discourse features produced in independent and integrated writing tasks differed; and then, what features were typical of different scoring levels. The analysis focused on measures of accuracy, fluency, complexity, coherence, cohesion, content, orientation to source evidence, and metadiscourse ( Figure 10). They found that the two types of tasks elicited significantly different language from the test takers and that the discourse features differed at the various score levels.
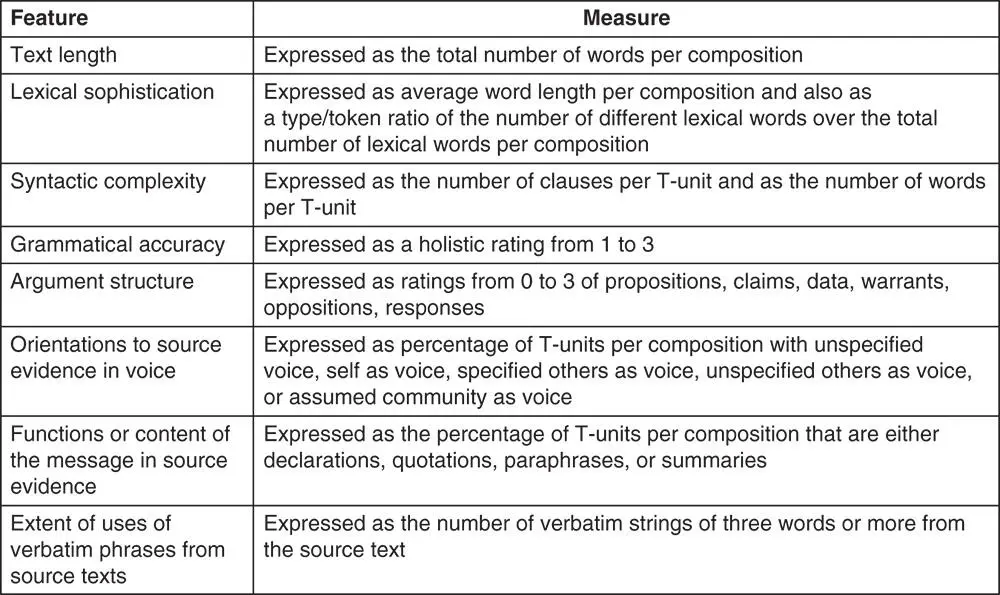
Figure 9 Discourse analytic measures (used in Cumming et al., 2006, used with permission)
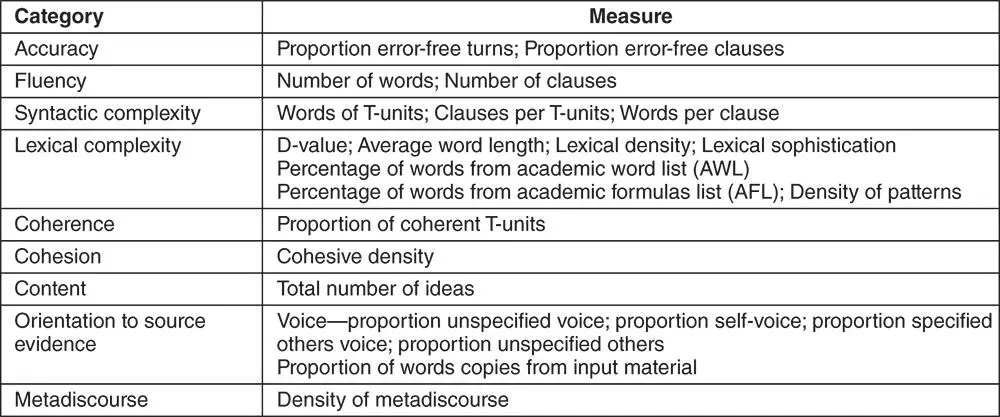
Figure 10 Discourse analytic measures (used in Knoch et al., 2014, used with permission)
These measures provide important information on the characteristics of L2 production and could serve as evidence supporting validity claims (e.g., for extrapolation). However, it is unclear how production measures, such as the number of clauses per T‐unit or the average word length, can be interpreted within a model of L2 proficiency or how these measures can be used to provide actionable feedback for learners. That said, testing experts have effectively used production features to examine validity questions in the area of automated scoring and feedback systems (Chapelle, 2008). Several studies have, for example, correlated measures of production features with the extended, spontaneous production of written or spoken texts (Burnstein, van Moere, & Cheng, 2010), or have examined the use of e‐rater production measures as a complement to human scoring of learners' writing essays (Enright & Quinlan, 2010). Weigle (2010) found consistent correlations between both human and e‐rater scoring with non‐test indicators such as teacher or student self‐evaluation of writing. This work highlights the potential of using production features in automated scoring.
Читать дальшеИнтервал:
Закладка:
Похожие книги на «The Concise Encyclopedia of Applied Linguistics»
Представляем Вашему вниманию похожие книги на «The Concise Encyclopedia of Applied Linguistics» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.












Обсуждение, отзывы о книге «The Concise Encyclopedia of Applied Linguistics» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.