Michael Yudell - Welcome to the Genome
Здесь есть возможность читать онлайн «Michael Yudell - Welcome to the Genome» — ознакомительный отрывок электронной книги совершенно бесплатно, а после прочтения отрывка купить полную версию. В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Жанр: unrecognised, на английском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.

- Название:Welcome to the Genome
- Автор:
- Жанр:
- Год:неизвестен
- ISBN:нет данных
- Рейтинг книги:5 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
Welcome to the Genome: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «Welcome to the Genome»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
offers substantial new and updated content to reflect recent major advances in genome-level sequencing and analysis, and demonstrates the vast increase in biological knowledge over the past decade. New sections cover next-generation technologies such as Illumina and PacBio sequencing, while expanded chapters discuss controversial ethical and philosophical issues raised by genomic technology, such as direct-to-consumer genetic testing. An essential resource for understanding the still-evolving genomic revolution, this book:
Introduces non-scientists to basic molecular principles and illustrates how they are shaping the genomic revolution in medicine, biology, and conservation biology Explores a wide range of topics within the field such as genetic diversity, genome structure, genetic cloning, forensic genetics, and more Includes full-color illustrations and topical examples Presents material in an accessible, user-friendly style, requiring no expertise in genomics Discusses past discoveries, current research, and future possibilities in the field Sponsored by the American Museum of Natural History,
is a must-read book for anyone interested in the scientific foundation for understanding the development and evolutionary heritage of all life.
Welcome to the Genome — читать онлайн ознакомительный отрывок
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «Welcome to the Genome», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
Deciphering the genetic code allowed scientists to scan stretches of DNA sequences and look for genes. The language spelled out by nucleic and amino acids has rules similar to the rules of punctuation. Just as you can scan this paragraph for capital letters and periods, you can look for the first word in a DNA sentence to find what is called an initiator codon and read on until you find the end of the sentence or period, which in genetic terminology is called the terminator codon. Everything between these points is part of the same gene.
In a genetic sentence the initiator codon is almost always a triplet of the nucleic acids A, T, and G, which codes for the amino acid methionine (also known as Met or M). Thus, when you look at the amino acids that make up proteins, you will, with a few exceptions, always see an M as the first letter in the protein. Experiments by Cambridge University biologists Sydney Brenner and Francis Crick, and by Alan Garen at Yale University, showed that there were three terminator codons or three ways to put a period at the end of a protein sentence—TAG, TAA, TGA. (15)
A sample genetic sentence:
ATG (initiator codon) GCA AGT TCT T … GC ATA AGT TAG (terminator codon)
This sounds easier than it actually is, however. As with the English language, a capital letter does not always indicate the beginning of a sentence. Once an ATG is located, scientists must determine whether the suspected gene is actually a gene at all. The suspected gene is called an open reading frame (ORF) and this process is called annotation.
It took nearly a decade of work for experiments to confirm the triplet model of protein synthesis. In 1961 at the U.S. National Institutes of Health biochemists Johann Heinrich Matthaei and Marshall Nirenberg verified the first word of the genetic code. Matthaei and Nirenberg’s experiment was relatively simple. In a test tube, they provoked nucleic acids they had synthesized to produce a protein. Placing only one type of nucleic acid, all Ts, into a test tube, they were able to produce the protein made up of only the amino acid phenylalanine, or P, meaning that the triplet TTT coded for phenylalanine. (16) Later that year at New York University School of Medicine biochemist Severo Ochoa began similar experiments constructing random strings of nucleotides, placing them in cell extracts, and determining the kind of amino acids that were incorporated into the subsequent protein. (17) By comparing the results of these and other experiments, scientists cracked the entire code of triplets by 1965.
Breaking the genetic code alone couldn’t explain the relationship between genes and proteins. By the late 1950s scientists recognized that some type of intracellular intermediary was bringing genetic information from DNA to ribosomes, which are the cellular mechanisms that assemble proteins. The link between DNA and proteins turned out to be a cellular material known as ribonucleic acid or RNA. (18)
RNA is a versatile molecule; it acts as structural scaffolding, as an enzyme, and as a messenger. Its general structure is the same as that of DNA, but its sugar ring is slightly different, hence the deoxyribo‐ in DNA and just plain ribo‐ in RNA. Also, like DNA, RNA has four kinds of bases. However, instead of T, or thymine, RNA has U, or uracil, which complements A when RNA binds to DNA.
There are two steps in translating genetic instructions into a protein. The first is called transcription. RNA molecules assemble along a stretch of DNA that constitutes a gene. The strand of RNA is complementary to the strand of DNA by the same rules that dictate the formation of a double helix.
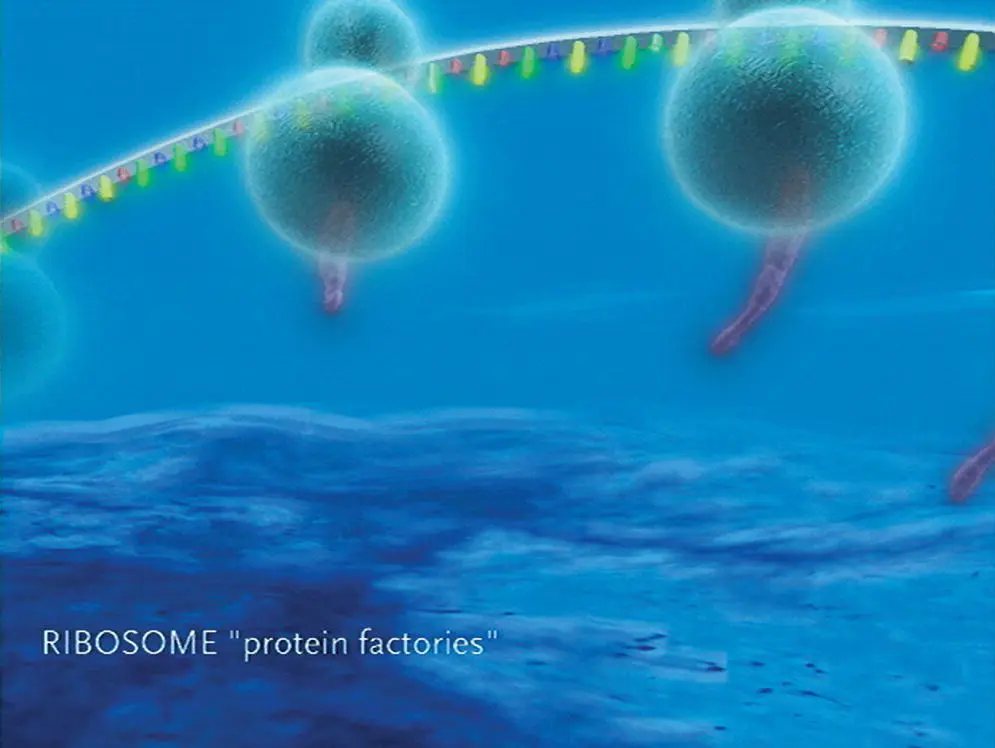
Figure 2.3Proteins are made in two steps. Messenger RNA first assembles along a gene (transcription). The mRNA molecule then moves out of the nucleus to a ribosome (pictured here), where it is translated into a protein (translation).
Credit: Exhibitions Department, American Museum of Natural History
Once formed, this strand of RNA, known as messenger RNA, or mRNA, moves out of the nucleus of a cell to a ribosome, where the genetic sentence is read and translated into a protein. This stage in protein formation is known as translation. This molecular mystery was solved by some of the same scientists working on decoding the genetic code—Sydney Brenner at Cambridge, Francois Jacob and Jacques Monod at the Institute Pasteur in Paris, and Matthew Messelson at Cal Tech. (19) The breaking of the genetic code allowed scientists to interpret DNA information by providing them with an accurate DNA to protein dictionary. This innovation was an important component of the assembly line of technologies that eventually shaped gene sequencing.
RESEARCH MILESTONE 3 : SYNTHESIZING DNA
Since the early part of the twentieth century, scientists had been aware of the vital connection between genes and enzymes, a type of protein that usually accelerates chemical reactions in an organism. As early as 1901, Archibald Garrod, a London physician studying metabolic disorders, recognized that patients with the disease alkaptonuria were lacking what he called a “special enzyme” that results in the body’s inability to break down a substance called alkapton (today we know that alkaptonuria is caused by a mutation in the HGD gene on chromosome 3, which impairs the body’s ability to break down the amino acids phenylalanine and tyrosin). By studying familial patterns of this disease, Garrod came to infer that the missing enzyme was a problem of inheritance; most of the children with the defect were born to parents who were first cousins. (20) This “shallow” gene pool made the emergence of this recessive trait more likely.
Four decades later at Stanford University, biochemist Edward Tatum and geneticist George Beadle refined Garrod’s observations, suggesting in 1941 that one gene codes for one enzyme, a theory that was a cornerstone of molecular biology for more than five decades. They were awarded a Nobel Prize for their discovery in 1958. (21) Although DNA itself was coming to be known to be the stuff of heredity, enzymes and other proteins, it was turning out, were essential to the successful operation of the cell and therefore of the organism. If hereditary information was carried on DNA, then the different classes of proteins are, in large part, heredity’s workhorses, delivering instructions for many of life’s intricacies at the beck and call of the DNA molecule itself.
Work at the cellular level, with its varied goals, was less directed, for example, than the search for the structure of DNA. Some scientists were busy taking the cell apart to determine how DNA replicated, others learning how proteins were synthesized, and still others inquiring about the nature and function of proteins. In fact, Arthur Kornberg carried out his Nobel Prize‐winning discovery of the protein in bacteria that controls DNA replication without Watson and Crick’s work in mind. Perhaps what Kornberg himself called his “many love affairs with enzymes” distracted him from the broader goings‐on in molecular biology. “The significance of the double helix did not intrude into my work until 1956,” Kornberg wrote, “after the enzyme that assembles the nucleotide building blocks into a DNA chain was already in hand.” (22)
Kornberg’s discovery, once known as DNA polymerase or Kornberg’s enzyme and now known as DNA polymerase I, catalyzes the addition of nucleotides to a chain of DNA (other DNA polymerases were discovered later, and were in turn known as polymerases II, III, etc.). In other words, DNA polymerase is the mechanism by which DNA clones or copies itself. Working with the bacteria E. coli , a bacteria that is usually beneficial to the function of the human digestive tract, Kornberg showed that the enzyme DNA polymerase was able to synthesize a copy of one strand of DNA. With a single strand of DNA in a test tube, the presence of DNA polymerase served as the catalyst (or initiator) for DNA replication. These experiments revealed only that the synthesized DNA was true to Chargaff’s rules, having the correct ratio of As to Ts and Cs to Gs. (23) Kornberg’s results did not, however, reveal the sequential arrangement of nucleotides, nor was it known at this time whether this laboratory model was what actually happened in living organisms. (24)
Читать дальшеИнтервал:
Закладка:
Похожие книги на «Welcome to the Genome»
Представляем Вашему вниманию похожие книги на «Welcome to the Genome» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.












Обсуждение, отзывы о книге «Welcome to the Genome» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.