Tina M. Henkin - Snyder and Champness Molecular Genetics of Bacteria
Здесь есть возможность читать онлайн «Tina M. Henkin - Snyder and Champness Molecular Genetics of Bacteria» — ознакомительный отрывок электронной книги совершенно бесплатно, а после прочтения отрывка купить полную версию. В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Жанр: unrecognised, на английском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.

- Название:Snyder and Champness Molecular Genetics of Bacteria
- Автор:
- Жанр:
- Год:неизвестен
- ISBN:нет данных
- Рейтинг книги:3 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
Snyder and Champness Molecular Genetics of Bacteria: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «Snyder and Champness Molecular Genetics of Bacteria»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
Although the text is centered on the most-studied bacteria,
and
, many examples are drawn from other bacteria of experimental, medical, ecological, and biotechnological importance. The book's many useful features include
Text boxes to help students make connections to relevant topics related to other organisms, including humans A summary of main points at the end of each chapter Questions for discussion and independent thought A list of suggested readings for background and further investigation in each chapter Fully illustrated with detailed diagrams and photos in full color A glossary of terms highlighted in the text While intended as an undergraduate or beginning graduate textbook, Molecular Genetics of Bacteria is an invaluable reference for anyone working in the fields of microbiology, genetics, biochemistry, bioengineering, medicine, molecular biology, and biotechnology.
"This is a marvelous textbook that is completely up-to-date and comprehensive, but not overwhelming. The clear prose and excellent figures make it ideal for use in teaching bacterial molecular genetics."—
, University of Washington
Snyder and Champness Molecular Genetics of Bacteria — читать онлайн ознакомительный отрывок
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «Snyder and Champness Molecular Genetics of Bacteria», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
The positions of nucleotides in a promoter region are numbered as shown in Figure 2.6. The position of the first nucleotide in the RNA is called the start point and is given the number +1; the distance in nucleotides from this point to another point is numbered negatively or positively, depending on whether the second site is upstream or downstream of the start point, respectively. Note that these definitions can be used to describe only a region of DNA that is known to encode an RNA or protein, where we know which is the coding strand and which is the transcribed strand. Otherwise, what is upstream on one strand of DNA is downstream on the other strand.
Because mRNAs are both made and translated in the 5′-to-3′ direct ion, an mRNA can (and usually will) be translated while it is still being made, at least in bacteria and archaea, in which there is no nuclear membrane separating the DNA from the cytoplasm, where the ribosomes reside. We have discussed how this can lead to phenomena unique to bacteria, such as ρ-dependent polarity, and it is used to regulate expression of some genes in bacteria (see chapter 11).
It is important to distinguish promoters from TIRs and to distinguish transcription termination sites from translation termination sites. Figure 2.44illustrates this difference. Transcription begins at the promoter and defines the 5′ end of the mRNA, but the place where translation begins, the TIR, can be some distance from the 5′ end. The untranslated region on the 5′ end of an mRNA upstream of the TIR is called the 5′ untranslated region or leader region and can be quite long. Similarly, a nonsense codon in the reading frame for the protein is a translation terminator, not a transcription terminator. The transcription terminator, and therefore the 3′ end of the mRNA, may be some distance downstream from the nonsense codon that terminates transition of the mRNA. The distance from the last termination codon to the 3′ end of the mRNA is the 3′ untranslated region. Polycistronic mRNAs encode more than one polypeptide. These mRNAs have a separate TIR and termination codon for each gene and can have noncoding or untranslated sequences upstream of, downstream of, and between the genes. Eukaryotes generally do not have polycistronic mRNAs, which is related to the dependence on ribosome binding to the 5′ end of the mRNA for translation initiation.
Open Reading Frames
The concept of an open reading frame, or ORF, is very important, particularly in this age of genomics. As discussed above, a reading frame in DNA is a succession of nucleotides in the DNA taken three at a time, the same way the genetic code is translated. Each DNA sequence has six reading frames, three on each strand, as illustrated in Figure 2.44. An ORF is a string of potential codons for amino acids in DNA unbroken by termination codons in one of the reading frames. Computer software can show where all the ORFs in a sequence are located, and most DNA sequences have many ORFs on both strands, although most of them are short. The region shown in Figure 2.44contains many ORFs, but only the longest, in frame 6, is likely to encode a polypeptide. However, the presence of even a long ORF in a DNA sequence does not necessari ly indicate that the sequence encodes a protein, and fairly long ORFs often occur by chance. Furthermore, it has become evident recently that even very short ORFs can encode short peptides with important biological functions.
If an ORF does encode a polypeptide, it will begin with a TIR, but as discussed above, TIRs are sometimes difficult to identify. Clues to whether an ORF is likely to encode a protein may come from the choice of the third base in the codon for each amino acid in the ORF. Because of the redundancy of the code, an organism has many choices of codons for each amino acid, but each organism prefers to use some codons over others (see “Codon Usage” above) (Table 2.2).
A more direct way to determine if an ORF actually encodes a protein is to ask which polypeptides are made from the DNA in an in vitro transcription-translation system. These systems use extracts of cells, typically of E. coli , from which the DNA has been removed but the RNA polymerase, ribosomes, and other components of the translation apparatus remain. When DNA with the ORFs under investigation is added to these extracts, polypeptides can be synthesized from the added DNA. If the size of one of these polypeptides corresponds to the size of an ORF on the DNA, the ORF probably encodes a protein. Another way to determine if an ORF encodes a protein is to make a translation fusion of a reporter gene to the ORF and to determine whether the reporter gene is expressed (see below).
Transcriptional and Translational Fusions
Probably the most convenient way to determine which of the possible ORFs on the two strands of DNA in a given region are translated into proteins is to make transcriptionaland translational fusionsto the ORFs. These methods make use of reporter genes, such as lacZ (β-galactosidase), gfp (green fluorescent protein), lux (luciferase), or other genes whose products are easy to detect. Figure 2.45illustrates the concepts of transcriptional and translational fusions.
An ORF can be translated only if it is transcribed into RNA. Transcriptional fusions can be used to determine whether this has occurred. To make a transcriptional fusion, a reporter gene containing its TIR sequence but without its own promoter is fused immediately downstream of the promoter of the gene to be tested. If the promoter is active, and its gene is transcribed into mRNA, the reporter gene will also be transcribed, and the reporter gene product will be detectable in the cell. Transcriptional fusions also offer a convenient way of determining how much mRNA is made on a coding sequence. In general, the more reporter gene product that is made in the transcriptional fusion, the more mRNA was made that was directed by the upstream sequence. Translation of the mRNA depends on the activity of the TIR from the reporter gene and is usually consistent regardless of the identity of the upstream sequence. Examples of the use of transcriptional fusions in studying the regulation of operons are given in subsequent chapters.
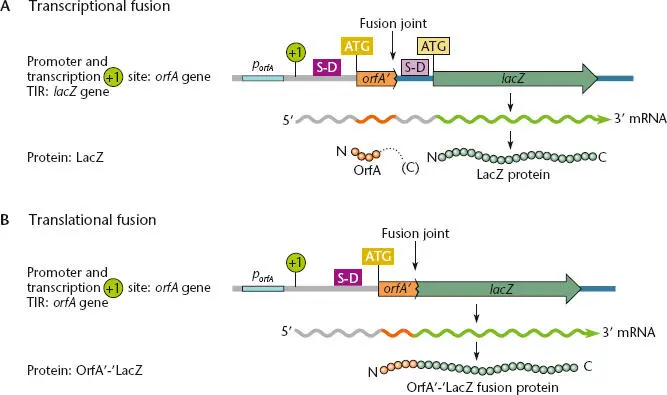
Figure 2.45 Transcriptional and translational fusions to express a lacZ reporter (which encodes β-galactosidase). In both types of fusion, transcription begins at the +1 site at the porfA promoter upstream of the OrfA coding sequence, and the levels of mRNA generated are dependent on the activity of this promoter. (A)In a transcriptional fusion, both the upstream OrfA coding region and the downstream lacZ reporter gene are included in the mRNA, and translation can initiate from both TIRs. Only the TIR for lacZ is used to generate β-galactosidase protein. The translation of the upstream OrfA continues until it encounters a termination codon in frame, as indicated by the dotted line, and therefore the activity of the orfA TIR does not contribute to β-galactosidase synthesis. Levels of β-galactosidase indicate the activity of the poffA promoter. (B)In a translational fusion, the mRNA includes the orfA TIR but the lacZ portion lacks its own TIR. Translation of the mRNA initiates at the TIR upstream of OrfA to make a fusion protein containing the remaining portion of the upstream OrfA coding sequence fused (in frame) to the LacZ reporter protein. The prime symbols indicate that part of each protein may be deleted. Levels of β-galactosidase indicate the activity of both the poffA promoter and the orfA TIR.
Читать дальшеИнтервал:
Закладка:
Похожие книги на «Snyder and Champness Molecular Genetics of Bacteria»
Представляем Вашему вниманию похожие книги на «Snyder and Champness Molecular Genetics of Bacteria» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.











Обсуждение, отзывы о книге «Snyder and Champness Molecular Genetics of Bacteria» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.