David Machin - Medical Statistics
Здесь есть возможность читать онлайн «David Machin - Medical Statistics» — ознакомительный отрывок электронной книги совершенно бесплатно, а после прочтения отрывка купить полную версию. В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Жанр: unrecognised, на английском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.

- Название:Medical Statistics
- Автор:
- Жанр:
- Год:неизвестен
- ISBN:нет данных
- Рейтинг книги:3 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
Medical Statistics: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «Medical Statistics»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
Helpful multi-choice exercises are included at the end of each chapter, with answers provided at the end of the book. Each analysis technique is carefully explained and the mathematics kept to minimum. Written in a style suitable for statisticians and clinicians alike, this edition features many real and original examples, taken from the authors' combined many years' experience of designing and analysing clinical trials and teaching statistics.
Students of the health sciences, such as medicine, nursing, dentistry, physiotherapy, occupational therapy, and radiography should find the book useful, with examples relevant to their disciplines. The aim of training courses in medical statistics pertinent to these areas is not to turn the students into medical statisticians but rather to help them interpret the published scientific literature and appreciate how to design studies and analyse data arising from their own projects. However, the reader who is about to design their own study and collect, analyse and report on their own data will benefit from a clearly written book on the subject which provides practical guidance to such issues.
The practical guidance provided by this book will be of use to professionals working in and/or managing clinical trials, in academic, public health, government and industry settings, particularly medical statisticians, clinicians, trial co-ordinators. Its practical approach will appeal to applied statisticians and biomedical researchers, in particular those in the biopharmaceutical industry, medical and public health organisations.
Medical Statistics — читать онлайн ознакомительный отрывок
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «Medical Statistics», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
4.6 Reference Ranges
Diagnostics tests use patient data to classify individuals as either normal or abnormal. A related statistical problem is the description of the variability in normal individuals, to provide a basis for assessing the test results of other individuals. The most common form of presenting such data is as a range of values or interval that contains the values obtained from the majority of a sample of normal subjects. The reference interval is often referred to as a normal range or reference range. To distinguish the use of the same word for the Normal distribution we have used a lower case, for the normal range, and upper case convention throughout this book.
Worked Example – Reference Range – Birthweight
We can use the fact that our sample birthweight data, from the O'Cathain et al. (2002) study (see Figure 4.9); appear Normally distributed to calculate a reference range for birthweights. We have already mentioned that about 95% of the observations from a Normal distribution lie within 1.96 SDs either side of the mean. So a reference range obtained from this sample of babies is:
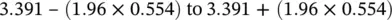
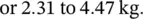
If the baby data were not Normally distributed then the normal reference range is obtained from the calculated percentiles of the sample as described in Chapter 2. Thus the 2.5 percentile corresponds to 2.5% of the babies below this weight which equals 2.91 kg. Correspondingly the estimated 97.5 percentile suggests that only 2.5% of babies are heavier than 4.43 kg at birth. The percentile‐based reference range for baby birthweight is therefore estimated to be 2.19 to 4.43 kg. This is very close to that obtained when we assume the birthweight has a Normal distribution.
Most reference ranges are based on samples larger than 3500 people. Over many years, and millions of births, the World Health Organization (WHO) has come up with a normal birthweight range for new‐born babies. These ranges represent results than are acceptable in new‐born babies and actually cover the middle 80% of the population distribution, that is, the 10th and 90th centiles. Low birthweight babies are usually defined (by the WHO) as weighing less than 2500 g (the 10th centile) regardless of gestational age, and large birth weight babies are defined as weighing above 4000 g (the 90th centile). Hence the normal birth weight range is around 2.5 to 4.0 kg. For our sample data, the 10th to 90th centile range was similar, at 2.75 to 4.03 kg.
4.7 Other Distributions
There are many other probability distributions used in statistics. In this section we briefly list and describe those that are more commonly used.
t ‐distribution
Student's t‐ distribution is any member of a family of continuous probability distributions that arises when estimating the mean of a Normally distributed variable (in the population) in situations where the sample size is small and the population standard deviation is unknown. It was developed by William Sealy Gosset under the pseudonym Student.
The t ‐distribution plays an important role in a number of widely used statistical analyses, including Student's t ‐test for assessing the statistical significance of the difference between two sample means, the construction of confidence intervals for the difference between two population means, and in linear regression analysis.
The t ‐distribution is symmetric and bell‐shaped, like the Normal distribution, but has heavier tails, meaning that it is more prone than a Standard Normal distribution to producing values that fall far from its mean ( Figure 4.14a). The exact shape of the t ‐distribution is determined by the mean and variance plus what are known as the degrees of freedom, df . These are derived from the sample size. As the df increases, the shape of the t ‐distribution becomes closer to the Normal distribution; and when the sample size (and degrees of freedom) are greater than 30, the t ‐distribution is very similar to the Standard Normal distribution.
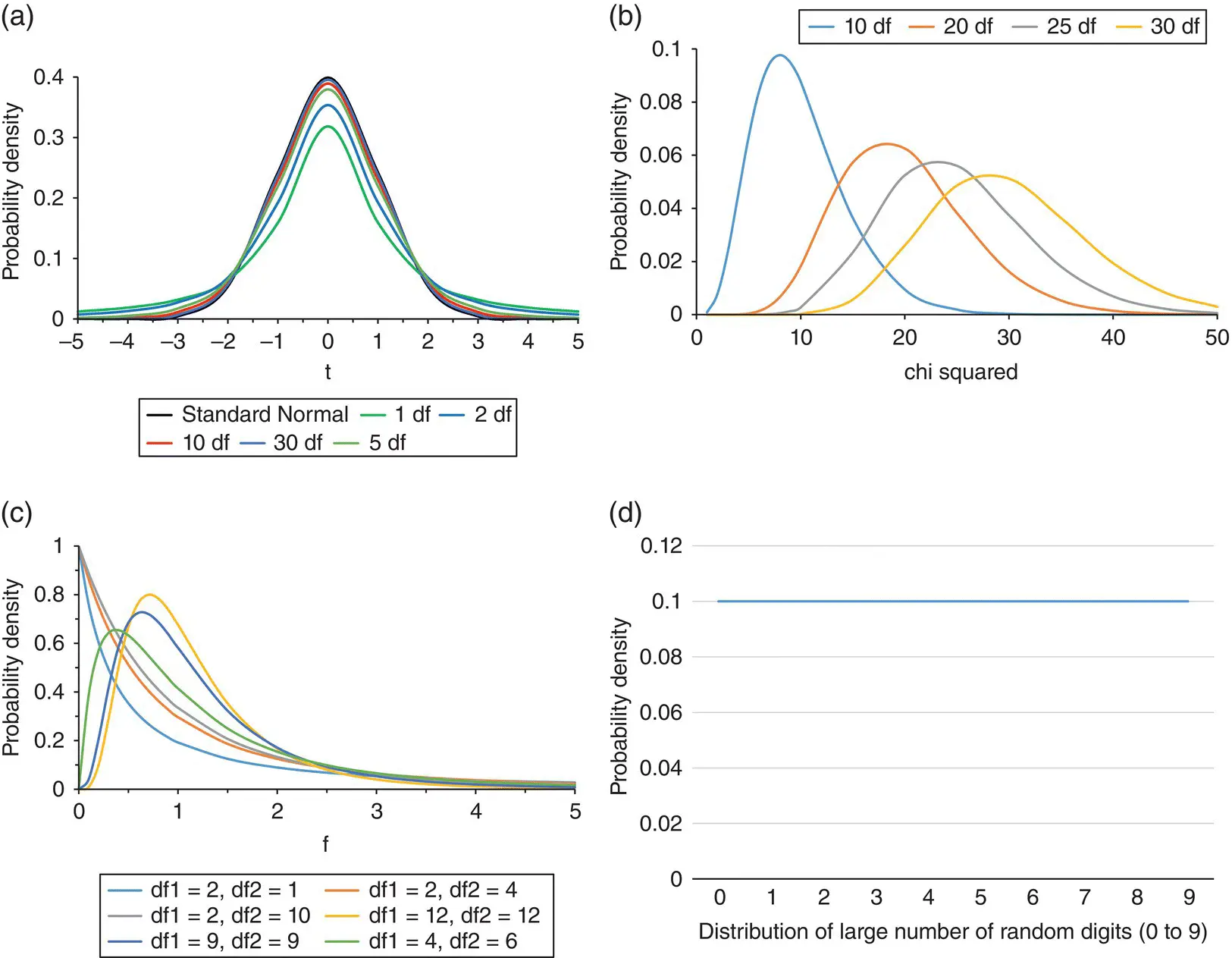
Figure 4.14 Examples of probability density/distribution functions for the t‐, chi‐squared, F‐ and Uniform distributions. (a) t ‐distribution. (b) chi‐squared distribution. (c) F ‐distribution. (d) Uniform distribution.
Chi‐squared Distribution
The chi‐squared distribution (or χ 2‐distribution) with n degrees of freedom ( Figure 4.14b) is the distribution of a sum of the squares of n independent standard Normal random variables. The chi‐squared distribution is always positive and its shape is uniquely determined by the degrees of freedom. The distribution becomes more symmetrical as the degrees of freedom increase and when the degrees of freedom are greater than 50, the chi‐squared distribution is very similar to the Normal distribution. The chi‐squared distribution is used in the common chi‐squared tests for goodness of fit of an observed distribution to a theoretical one, the independence of two criteria of classification of qualitative data, and in confidence interval estimation for a population standard deviation of a Normal distribution from a sample standard deviation.
F ‐distribution
The F ‐distribution ( Figure 4.14c) is the distribution of the ratio of two chi‐squared distributions and is used in hypothesis testing when we want to compare variances, such as in one‐way analysis of variance (see Section 7.3). It is always positive, but the exact shape depends on the degrees of freedom for the two chi‐squared distributions that determine it.
Uniform Distribution
The Uniform distribution ( Figure 4.14d) has a rectangular shape so that each possible value occurs with equal probability within a given range. It can be useful in a Bayesian analysis as the prior distribution of an unknown parameter where all values with a given range are thought to be equally likely.
4.8 Points When Reading the Literature
1 What is the population from which the sample was taken? Are there any possible sources of bias that may affect the estimates of the population parameters?
2 Have reference ranges been calculated on a random sample of healthy volunteers? If not, how does this affect your interpretation? Is there any good reason why a random sample was not taken?
3 For any continuous variable, are the variables correctly assumed to have a Normal distribution? If not, how do the investigators take account of this?
4.9 Technical Section
Binomial Distribution
Data that can take only a 0 or 1 response, such as treatment failure or treatment success, follow the Binomial distribution provided the underlying population response rate π does not change. The Binomial probabilities are calculated from
(4.1) 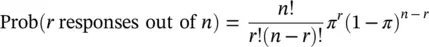
for successive values of r from 0 through to n . In the above n ! is read as n factorial and r ! as r factorial. For r = 4, r ! = 4 × 3 × 2 × 1 = 24. Both 0! and 1! are taken as equal to unity. It should be noted that the expected value for r , the number of successes yet to be observed if we treated n patients, is nπ . The potential variation about this expectation is expressed by the corresponding standard deviation 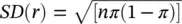 .
.
Интервал:
Закладка:
Похожие книги на «Medical Statistics»
Представляем Вашему вниманию похожие книги на «Medical Statistics» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.












Обсуждение, отзывы о книге «Medical Statistics» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.