The Handbook of Speech Perception
Здесь есть возможность читать онлайн «The Handbook of Speech Perception» — ознакомительный отрывок электронной книги совершенно бесплатно, а после прочтения отрывка купить полную версию. В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Жанр: unrecognised, на английском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.

- Название:The Handbook of Speech Perception
- Автор:
- Жанр:
- Год:неизвестен
- ISBN:нет данных
- Рейтинг книги:4 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
The Handbook of Speech Perception: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «The Handbook of Speech Perception»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
, Second Edition, is a comprehensive and up-to-date survey of technical and theoretical developments in perceptual research on human speech. Offering a variety of perspectives on the perception of spoken language, this volume provides original essays by leading researchers on the major issues and most recent findings in the field. Each chapter provides an informed and critical survey, including a summary of current research and debate, clear examples and research findings, and discussion of anticipated advances and potential research directions. The timely second edition of this valuable resource:
Discusses a uniquely broad range of both foundational and emerging issues in the field Surveys the major areas of the field of human speech perception Features newly commissioned essays on the relation between speech perception and reading, features in speech perception and lexical access, perceptual identification of individual talkers, and perceptual learning of accented speech Includes essential revisions of many chapters original to the first edition Offers critical introductions to recent research literature and leading field developments Encourages the development of multidisciplinary research on speech perception Provides readers with clear understanding of the aims, methods, challenges, and prospects for advances in the field
, Second Edition, is ideal for both specialists and non-specialists throughout the research community looking for a comprehensive view of the latest technical and theoretical accomplishments in the field.
The Handbook of Speech Perception — читать онлайн ознакомительный отрывок
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «The Handbook of Speech Perception», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
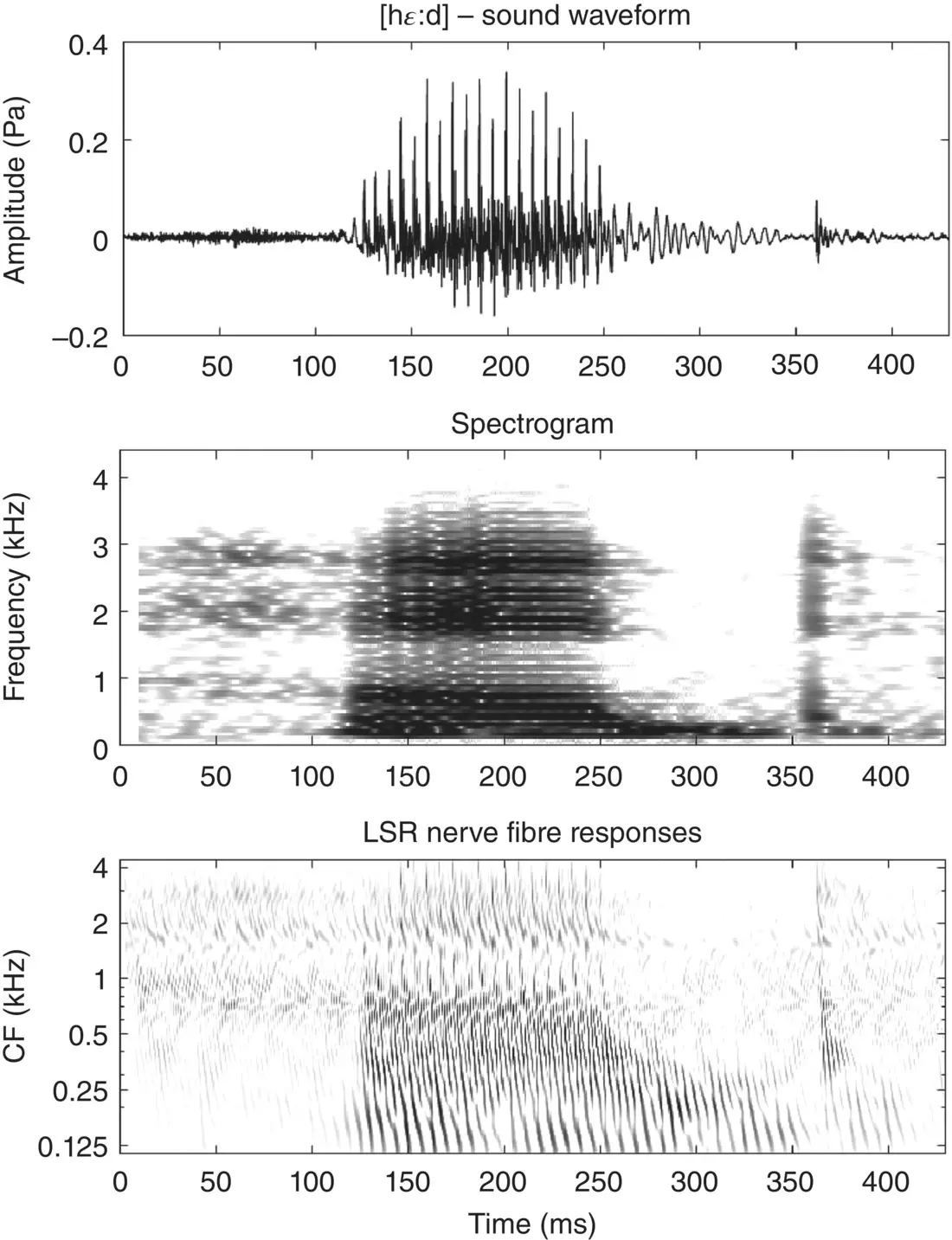
Figure 3.4 Waveform (top), spectrogram (middle), and simulated LSR auditory nerve‐fiber neurogram of the spoken word head [hɛːd].
As an aside, note that it is quite common for severe hearing impairment to be caused by an extensive loss of auditory hair cells in the cochlea, which can leave the auditory nerve fibers largely intact. In such patients it is now often possible to restore some hearing through cochlear implants, which use electrode arrays implanted along the tonotopic array to deliver direct electrical stimulation to the auditory nerve fibers. The electrical stimulation patterns delivered by the 20‐odd electrode contacts provided by these devices are quite crude compared to the activity patterns created when the delicate dance of the basilar membrane is captured by some 3,000 phenomenally sensitive auditory hair cells, but because coarsely resolving only a modest number of formant peaks is normally sufficient to allow speech sounds to be discriminated, the large majority of deaf cochlear implant patients do gain the ability to have pretty normal spoken conversations – as long as there is little background noise. Current cochlear implant processors are essentially incapable of delivering any of the temporal fine structure information which we have just described via the auditory nerve, and consequently cochlear implant users miss out on things like periodicity pitch cues, which may help them separate out voices in a cluttered auditory scene. A lack of temporal fine structure can also affect the perception of dialect and affect in speech, as well as melody, harmony, and timbre in music.
Subcortical pathways
As we saw in Figure 3.1, the neural activity patterns just described are passed on first to the cochlear nuclei, and from there through the superior olivary nuclei to the midbrain, thalamus, and primary auditory cortex. As mentioned, each of these stations of the lemniscal auditory pathway has a tonotopic structure, so all we learned in the previous section about tonotopic arrays of neurons representing speech formant patterns neurogram style still applies at each of these stations. But that is not to say that the neural representation of speech sounds does not undergo some transformations along these pathways. For example, the cochlear nuclei contain a variety of different neural cell types that receive different types of converging inputs from auditory nerve fibers, which may make them more or less sensitive to certain acoustic cues. So‐called octopus cells, for example, collect inputs across a number of fibers across an extent of the tonotopic array, which makes them less sharply frequency tuned but more sensitive to the temporal fine structure of sounds such glottal pulse trains (Golding & Oertel, 2012). So‐called bushy cells in the cochlear nucleus are also very keen on maintaining temporal fine structure encoded in the timing of auditory nerve fiber inputs with very high precision, and passing this information on undiminished to the superior olivary nuclei (Joris, Smith, & Yin, 1998). The nuclei of the superior olive receive converging (and, of course, tonotopically organized) inputs from both ears, which allows them to compute binaural cues to the direction that sounds may have come from (Schnupp & Carr, 2009). Thus, firing‐rate distributions between neurons in the superior olive, and in subsequent processing stations, may provide information not just about formants or voicing of a speech sound, but also about whether the speech came from the left or the right or from straight ahead. This adds further dimensions to the neural representation of speech sounds in the brainstem, but much of what we have seen still applies: formants are represented by peaks of activity across the tonotopic array, and the temporal fine structure of the sound is represented by the temporal fine structure of neural firing patterns. However, while the tonotopic representation of speech formants remains preserved throughout the subcortical pathways up to and including those in the primary auditory cortex, temporal fine structure at fast rates of up to several hundred hertz is not preserved much beyond the superior olive. Maintaining the sub‐millisecond precision of firing patterns across a chain of chemical synapses and neural cell membranes that typically have temporal jitter and time constants in the millisecond range is not easy. To be up to the job, neurons in the cochlear nucleus and olivary nuclei have specialized synapses and ion channels that more ordinary neurons in the rest of the nervous system lack.
It is therefore generally thought that temporal fine structure cues to aspects such as the periodicity pitch of voiced speech sounds become recoded as they ascend the auditory pathway beyond the brainstem. Thus, from about the inferior colliculus onward, temporal fine structure at fast rates is increasingly less represented though fast and highly precise temporal firing patterns, but instead through neurons becoming periodicity tuned (Frisina, 2001); this means that their firing rates may vary as a function of the fundamental frequency of a voiced speech sound, in addition to depending on the amount of sound energy in a particular frequency band. Some early work on periodicity tuning in the inferior colliculus has led to the suggestion that this structure may even contain a periodotopic map (Schreiner & Langner, 1988), with neurons tuned to different periodicities arranged along an orderly periodotopic axis running through the whole length of the inferior colliculus, with the periodotopic gradient more or less orthogonal to the tonotopic axis. Such an arrangement would be rather neat: periodicity being a major cue for sound features such as voice pitch, a periodotopic axis might, for example, physically separate out the representations of voices that differ substantially in pitch. But, while some later neuroimaging studies seemed to support the idea of a periodotopic map in the inferior colliculus (Baumann et al., 2011), more recent, very detailed, and comprehensive recordings with microelectrode arrays have shown conclusively that there are no consistent periotopic gradients running the width, breadth, or depth of the inferior colliculus (Schnupp, Garcia‐Lazaro, & Lesica, 2015), nor are such periodotopic maps a consistent feature of primary auditory cortex (Nelken et al., 2008).
Thus, tuning to periodicity (and, by implication, voicing and voice pitch), as well as to cues for sound‐source direction, is widespread among neurons in the lemniscal auditory pathway from at least the midbrain upward, but neurons with different tuning properties appear to be arranged in clusters without much overarching systematic order, and their precise arrangement can differ greatly from one individual to the next. Thus, neural populations in these structures are best thought of as a patchwork of neurons that are sensitive to multiple features of speech sounds, including pitch, sound‐source direction, and formant structure (Bizley et al., 2009; Walker et al., 2011), without much discernible overall anatomical organization other than tonotopic order.
Primary auditory cortex
So far, in the first half of this chapter we have talked about how speech is represented in the inner ear and auditory nerve, and along the subcortical pathways. However, for speech to be perceived, the percolation of auditory information must reach the cortex. Etymologically, the word cortex is Latin for “rind,” which is fitting as the cerebral cortex covers the outer surface of the brain – much like a rind covers citrus fruit. Small mammals like mice and trees shrews are endowed with relatively smooth cortices, while the cerebral cortices of larger mammals, including humans ( Homo sapiens ) and, even more impressively, African bush elephants ( Loxodonta africana ), exhibit a high degree of cortical folding (Prothero & Sundsten, 1984). The more folded, wrinkled, or crumpled your cortex, the more surface area can fit into your skull. This is important because a larger cortex (relative to body size) means more neurons, and more neurons generally mean more computational power (Jerison, 1973). For example, in difficult, noisy listening conditions, the human brain appears to recruit additional cortical regions (Davis & Johnsrude, 2003) which we shall come back to in the next few sections. In this section, we begin our journey through the auditory cortex by touching on the first cortical areas to receive auditory inputs: the primary auditory cortex.
Читать дальшеИнтервал:
Закладка:
Похожие книги на «The Handbook of Speech Perception»
Представляем Вашему вниманию похожие книги на «The Handbook of Speech Perception» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.







![О Генри - Справочник Гименея [The Handbook of Hymen]](/books/407356/o-genri-spravochnik-gimeneya-the-handbook-of-hymen-thumb.webp)




Обсуждение, отзывы о книге «The Handbook of Speech Perception» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.