The Handbook of Speech Perception
Здесь есть возможность читать онлайн «The Handbook of Speech Perception» — ознакомительный отрывок электронной книги совершенно бесплатно, а после прочтения отрывка купить полную версию. В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Жанр: unrecognised, на английском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.

- Название:The Handbook of Speech Perception
- Автор:
- Жанр:
- Год:неизвестен
- ISBN:нет данных
- Рейтинг книги:4 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
The Handbook of Speech Perception: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «The Handbook of Speech Perception»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
, Second Edition, is a comprehensive and up-to-date survey of technical and theoretical developments in perceptual research on human speech. Offering a variety of perspectives on the perception of spoken language, this volume provides original essays by leading researchers on the major issues and most recent findings in the field. Each chapter provides an informed and critical survey, including a summary of current research and debate, clear examples and research findings, and discussion of anticipated advances and potential research directions. The timely second edition of this valuable resource:
Discusses a uniquely broad range of both foundational and emerging issues in the field Surveys the major areas of the field of human speech perception Features newly commissioned essays on the relation between speech perception and reading, features in speech perception and lexical access, perceptual identification of individual talkers, and perceptual learning of accented speech Includes essential revisions of many chapters original to the first edition Offers critical introductions to recent research literature and leading field developments Encourages the development of multidisciplinary research on speech perception Provides readers with clear understanding of the aims, methods, challenges, and prospects for advances in the field
, Second Edition, is ideal for both specialists and non-specialists throughout the research community looking for a comprehensive view of the latest technical and theoretical accomplishments in the field.
The Handbook of Speech Perception — читать онлайн ознакомительный отрывок
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «The Handbook of Speech Perception», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
The firing rates of auditory nerve fibers increase monotonically with increasing sound level, but these fibers do need a minimum‐threshold sound level, and they cannot increase their firing rates indefinitely when sounds keep getting louder. This gives auditory nerve fibers a limited dynamic range, which usually covers 50 dB or less. At the edges of the dynamic range, the formants of speech sounds cannot be effectively represented across the tonotopic array because the neurons in the array either fire not at all (or not above their spontaneous firing rates), or because they all fire as fast as they can. However, people can usually understand speech well over a very broad range of sound levels. To be able to code sounds effectively over a wide range of sound levels, the ear appears to have evolved different types of auditory nerve fibers, some of which specialize in hearing quiet sounds, with low thresholds but also relatively low‐saturation sound levels, and others of which specialize in hearing louder sounds, with higher thresholds and higher saturation levels. Auditory physiologists call the more sensitive of these fiber types high spontaneous rate (HSR) fibers, given that these auditory nerve fibers may fire nerve impulses at fairly elevated rates (some 30 spikes per second or so), even in the absence of any external sound, and the less sensitive fibers the LSR fibers, which we have already encountered, and which fire only a handful of spikes per second in the absence of sound. There are also medium spontaneous rate fibers, which, as you might expect, lie in the middle between HSR and LSR fibers in sensitivity and spontaneous activity. You may, of course, wonder why these auditory nerve fibers would fire any impulses if there is no sound to encode, but it is worth bearing in mind that the amount of physical energy in relatively quiet sounds is minuscule, and that the sensory cells that need to pick up those sounds cannot necessarily distinguish a very quiet external noise from internal physiological noise that comes simply from blood flow or random thermal motion inside the ear at body temperature. Auditory nerve fibers operate right at the edge of this physiological noise floor, and the most sensitive cells are also most sensitive to the physiological background noise, which gives rise to their high spontaneous firing rate.
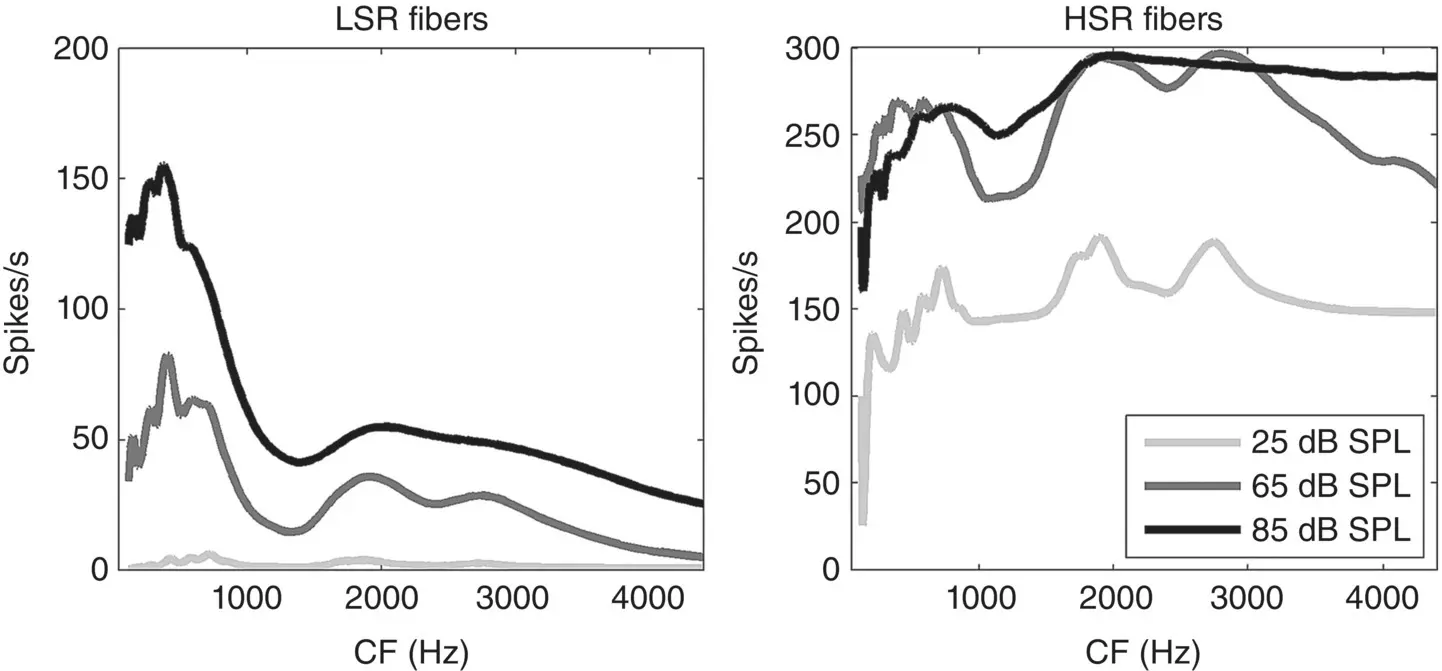
Figure 3.3 Firing‐rate distributions in response to the vowel [ɛ] in head [hɛːd] for low spontaneous rate fibers (left) and high spontaneous rate fibers (right) at three different sound intensities.
To give you a sense of what these different auditory nerve fiber types contribute to speech representations as different sound levels, Figure 3.3shows the firing‐rate distributions for the vowel [ɛ], much as in the right panel of Figure 3.2, but at three different sound levels (from a very quiet 25 dB SPL to a pretty loud 85 dB SPL, and for both LSR and HSR populations. As you can see, the LSR fibers (left panel) hardly respond at all at 25 dB, but the HSR fibers show clear peaks at the formant frequencies already at those very low sound levels. However, at the loud sound levels, most of the HSR fibers saturate, meaning that most of them are firing as fast as they can, so that the valleys between the formant peaks begin to disappear. One interesting consequence of this division of labor between HSR and LSR fibers for representing speech at low and high sound levels respectively is that it may provide an explanation why some people, particularly among the elderly, may complain of an increasing inability to understand speech in situations with high background noise. Recent work by Kujawa and Liberman (2015) has shown that, perhaps paradoxically, the less sound‐sensitive LSR fibers are actually more likely to be damaged during prolonged noise exposure. Patients with such selective fiber loss would still be able to hear quiet sounds quite well because their HSR fibers are intact, but they would find it very difficult to resolve sounds in high sound levels when HSR fibers are saturating and the LSR fibers that should encode spectral contrast at these high levels are missing. It has long been recognized that our ability to hear speech in noise tends to decline with age, even in those elderly who are lucky enough to retain normal auditory sensitivity (Stuart & Phillips, 1996), and it has been suggested that cumulative noise‐induced damage to LSR fibers such as that described by Kujawa and Liberman in their mouse model may pinpoint a possible culprit. Such hidden hearing loss, which is not detectable with standard audiometric hearing tests that measure sensitivity to probe tones in quiet, can be a significant problem, for example by taking all the fun out of important social occasions, such as lively parties and get‐togethers, which leads to significant social isolation. However, some recent studies have looked for, but failed to find, a clear link between greater noise exposure and poorer reception of speech in noise (Grinn et al., 2017; Grose, Buss, & Hall, 2017), which would suggest that perhaps the decline in our ability to understand speech in noise as we age may be more to do with impaired representations of speech in higher cortical centers than with impaired auditory nerve representations.
Of course, when you listen to speech, you don’t really want to have to ask yourself whether, given the current ambient sound levels, you should be listening to your HSR or your LSR auditory nerve fibers in order to get the best representation of speech formants, and one of the jobs of the auditory brainstem and midbrain circuitry is to combine information across these nerve fiber populations so that representations at midbrain and cortical stations will automatically adapt to changes both in mean sound level and in sound‐level contrast or variability, so that features like formants are efficiently encoded whatever the current acoustic environment happens to be (Dean, Harper, & McAlpine, 2005; Rabinowitz et al., 2013; Willmore et al., 2016).
As we saw earlier, the tonotopic representation of speech‐sound spectra in the auditory nerve provides much information about speech formants, but not a great deal about harmonics, which would reveal voicing or voice pitch. We probably owe much of our ability to nevertheless hear voicing and pitch easily and with high accuracy to the fact that, in addition to the small number of resolved harmonics, the auditory nerve delivers a great deal of so‐called temporal fine structure information to the brain. To appreciate what is meant by that, consider Figure 3.4, which shows the waveform (top), a spectrogram (middle) and an auditory nerve neurogram display (bottom) for a recording of the spoken word ‘head.’ The neurogram was produced by computing firing rates of a bank of LSR auditory nerve fibers in response to the sound as a function of time using the model by Zilany, Bruce, and Carney (2014). The waveform reveals the characteristic energy arc remarked upon by Greenberg (2006) for spoken syllables, with a relatively loud vowel flanked by much quieter consonants. The voicing in the vowel is manifest in the large sound‐pressure amplitude peaks, which arise from the glottal pulse train at regular intervals of approximately 7 ms, that is at a rate of approximately 140 Hz. This voice pitch is also reflected in the harmonic stack in the spectrogram, with harmonics at multiples of ~140 Hz, but this harmonic stack is not apparent in the neurogram. Instead we see that the nerve fiber responses rapidly modulate their firing rates to produce a temporal pattern of bands at time intervals which either directly reflect the 7 ms interval of the glottal pulse train (for nerve fibers with CFs below 0.2 kHz or above 1 kHz) or at intervals that are integer fractions (harmonics) of the glottal pulse interval. In this manner auditory nerve fibers convey important cues for acoustic features such as periodicity pitch by phase locking their discharges to salient features of the temporal fine structure of speech sounds with sub‐millisecond accuracy.
Читать дальшеИнтервал:
Закладка:
Похожие книги на «The Handbook of Speech Perception»
Представляем Вашему вниманию похожие книги на «The Handbook of Speech Perception» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.







![О Генри - Справочник Гименея [The Handbook of Hymen]](/books/407356/o-genri-spravochnik-gimeneya-the-handbook-of-hymen-thumb.webp)




Обсуждение, отзывы о книге «The Handbook of Speech Perception» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.