The Handbook of Speech Perception
Здесь есть возможность читать онлайн «The Handbook of Speech Perception» — ознакомительный отрывок электронной книги совершенно бесплатно, а после прочтения отрывка купить полную версию. В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Жанр: unrecognised, на английском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.

- Название:The Handbook of Speech Perception
- Автор:
- Жанр:
- Год:неизвестен
- ISBN:нет данных
- Рейтинг книги:4 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
The Handbook of Speech Perception: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «The Handbook of Speech Perception»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
, Second Edition, is a comprehensive and up-to-date survey of technical and theoretical developments in perceptual research on human speech. Offering a variety of perspectives on the perception of spoken language, this volume provides original essays by leading researchers on the major issues and most recent findings in the field. Each chapter provides an informed and critical survey, including a summary of current research and debate, clear examples and research findings, and discussion of anticipated advances and potential research directions. The timely second edition of this valuable resource:
Discusses a uniquely broad range of both foundational and emerging issues in the field Surveys the major areas of the field of human speech perception Features newly commissioned essays on the relation between speech perception and reading, features in speech perception and lexical access, perceptual identification of individual talkers, and perceptual learning of accented speech Includes essential revisions of many chapters original to the first edition Offers critical introductions to recent research literature and leading field developments Encourages the development of multidisciplinary research on speech perception Provides readers with clear understanding of the aims, methods, challenges, and prospects for advances in the field
, Second Edition, is ideal for both specialists and non-specialists throughout the research community looking for a comprehensive view of the latest technical and theoretical accomplishments in the field.
The Handbook of Speech Perception — читать онлайн ознакомительный отрывок
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «The Handbook of Speech Perception», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
The word representation is quite widely used in sensory neuroscience, but it is rarely clearly defined. A neural representation tends to refer to the manner in which neural activity patterns encode or process some key aspects of the sensory world. Of course, if we want to understand how the brain listens to speech, then grasping how neural activity in early stages of the nervous system encodes speech sounds is really only a very small part of what we would ideally like to understand. It is a necessary first step that leaves many interesting questions unanswered, as you can easily appreciate if you consider that fairly simple technological devices such as telephone lines are able to represent speech with patterns of electrical activity, but these devices tell us relatively little about what it means for a brain to hear speech. Phone lines merely have to capture enough of the physical parameters of an acoustic waveform to allow the resynthesis of a sufficiently similar acoustic waveform to facilitate comprehension by another person at the other end of the line. Brains, in contrast, don’t just deliver signals to a mind at the other end of the line, but they have to make the mind at the other end of the line, and to do that they have to try to learn something from the speech signal about who speaks, where they might be, what mood they are in, and, most importantly, the ideas the speaker is trying to communicate. Consequently it would be nice to know how the brain represents not just the acoustics, but also the phonetic, prosodic, and semantic features of the speech it hears.
Readers of this volume are likely to be well aware that extracting such higher‐order features from speech signals is difficult and intricate. Once the physical aspects of the acoustic waveform are encoded, phonetic properties such as formant frequencies, voicing, and voice pitch must be inferred, interpreted, and classified in a context‐dependent manner, which in turn facilitates the creation of a semantic representation of speech. In the auditory brain, this occurs along a processing hierarchy, where the lowest levels of the auditory nervous system – the inner ear, auditory nerve fibers and brainstem – encode the physical attributes of the sound and compute what may be described as low‐level features, which are then passed on via the midbrain and the thalamus toward an extensive network of auditory and multisensory cortical areas, whose task it is to form phonetic and semantic representations. As this chapter progresses, we will look in some detail at this progressive transformation of an initially largely acoustic representation of speech sounds in the auditory nerve, brainstem, midbrain, and primary cortex to an increasingly linguistic feature representation in a part of the brain called the superior temporal gyrus, and finally to semantic representations in brain areas stretching well beyond those classically thought of as auditory structures.
While it is apt to think of this neural speech‐processing stream as a hierarchical process, it would nevertheless be wrong to think of it as entirely a feed‐forward process. It is well known that, for each set of ascending nerve fibers carrying auditory signals from the inner ear to the brainstem, from brainstem to midbrain, from midbrain to thalamus, and from thalamus to cortex, there is a parallel descending pathway going from cortex back to thalamus, midbrain, brainstem and all the way back to the ear. This is thought to allow feedback signals to be sent in order to focus attention and to make use of the fact that the rules of language make the temporal evolution of speech sounds partly predictable, and such predictions can facilitate hearing speech in noise, or to tune the ear to the voice or dialect of a particular speaker.
To orient the readers who are unfamiliar with the neuroanatomy of the auditory pathway we include a sketch in Figure 3.1, which shows the approximate location of some of the key stages of the early parts of this pathway, from the ear to the primary auditory cortex, projected onto a drawing of a frontal section through the brain running vertically roughly through the middle of the ear canals.
The arrows in Figure 3.1show the principal connections along the main, ‘lemniscal’, ascending auditory pathway. Note, however, that it is impossible to overstate the extent to which Figure 3.1oversimplifies the richness and complexity of the brain’s auditory pathways. For example, the cochlear nuclei, the first auditory relay station receiving input from the ear, has no fewer than three anatomical subdivisions, each comprising many tens to a few hundred thousand neurons of different cell types and with different onward connections. Here we show the output neurons of the cochlear nuclei as projecting to the superior olive bilaterally, which is essentially correct, but for simplicity we omit the fact that the superior olive itself is composed of around half a dozen intricately interconnected subnuclei, and that there are also connections from the cochlear nuclei which bypass the superior olive and connect straight to the inferior colliculus, the major auditory‐processing center of the midbrain. The inferior colliculus too has several subdivisions, as does the next station on the ascending pathway, the medial geniculate body of the thalamus. And even primary auditory cortex is thought to have two or three distinct subfields, depending on which mammalian species one looks at and which anatomist one asks. In order not to clutter the figure we do not show any of the descending connections, but it would not be a bad start to think of each of the arrows here as going in both directions.
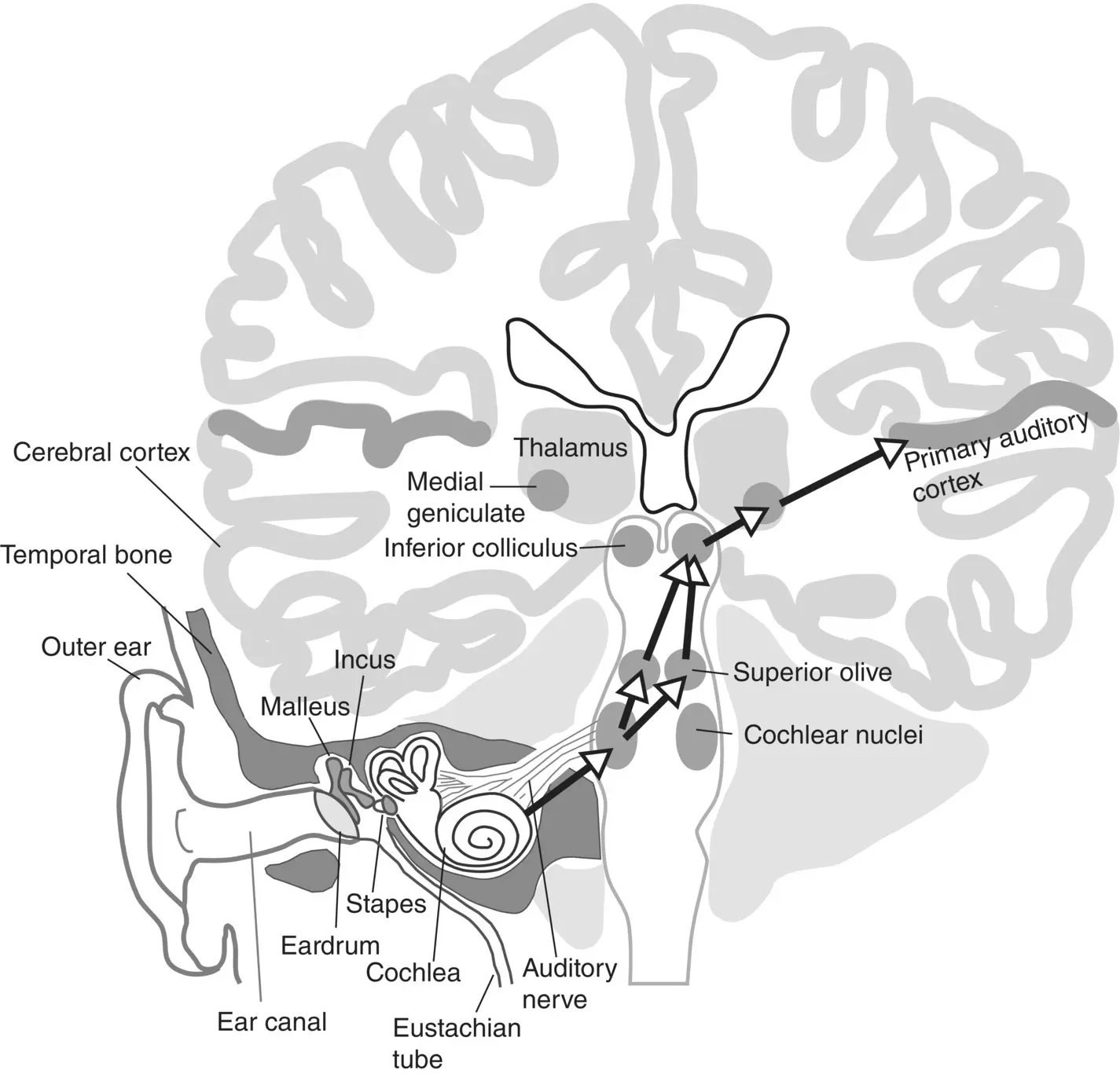
Figure 3.1 Illustration of the ear showing the early stages of the ascending auditory pathway.
The complexity of the anatomy is quite bewildering, and much remains unknown about the detailed structure and function of its many subdivisions. But we have nevertheless learned a great deal about these structures and the physiological mechanisms that are at work within them and that underpin our ability to hear speech. Animal experiments have been invaluable in elucidating basic physiological mechanisms of sound encoding, auditory learning, and pattern classification in the mammalian brain. Clinical studies on patients with various forms of hearing impairment or aphasia have also helped to identify key cortical structures. More recently, functional brain imaging on normal volunteers, as well as invasive electrophysiological recordings from the brains of patients who are undergoing brain surgery for epilepsy have further refined our knowledge of speech representations, particularly in higher‐order cortical structures.
In the sections that follow we shall highlight some of the insights that have been gained from these types of studies. The chapter will be structured as a journey: we shall accompany speech sounds as they leave the vocal tract of a speaker, enter the listener’s ear, become encoded as trains of nerve impulses in the cochlea and auditory nerve, and then travel along the pathways just described and spread out across a phenomenally intricate network of hundreds of millions of neurons whose concerted action underpins our ability to perform the everyday magic of communicating abstract thoughts across space and time through the medium of the spoken word.
Encoding of speech in the inner ear and auditory nerve
Let us begin our journey by reminding ourselves about how speech sounds are generated, and what acoustic features are therefore elementary aspects of a speech sound that need to be encoded. When we speak, we produce both voiced and unvoiced speech sounds. Voiced speech sounds arise when the vocal folds in our larynx open and close periodically, producing a rapid and periodic glottal pulse train which may vary from around 80 Hz for a low bass voice to 900 Hz or above for a high soprano voice, although glottal pulse rates of somewhere between 125 Hz to 300 Hz are most common for adult speech. Voiced speech sounds include vowels and voiced consonants. Unvoiced sounds are simply those that are not produced with any vibrating of the vocal folds. The manner in which they are created causes unvoiced speech sounds to have spectra typical of noise, while the spectra of voiced speech sounds exhibit a harmonic structure , with regular sharp peaks at frequencies corresponding to the overtones of the glottal pulse train. Related to these differences in the waveforms and spectra is the fact that, perceptually, unvoiced speech sounds do not have an identifiable pitch, while voiced speech sounds do have a clear pitch of a height that corresponds to their fundamental frequency, which corresponds to the glottal pulse rate. Thus, we can sing melodies with voiced speech sounds, but we cannot whisper a melody.
Читать дальшеИнтервал:
Закладка:
Похожие книги на «The Handbook of Speech Perception»
Представляем Вашему вниманию похожие книги на «The Handbook of Speech Perception» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.







![О Генри - Справочник Гименея [The Handbook of Hymen]](/books/407356/o-genri-spravochnik-gimeneya-the-handbook-of-hymen-thumb.webp)




Обсуждение, отзывы о книге «The Handbook of Speech Perception» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.