Artificial Intelligence and Data Mining Approaches in Security Frameworks
Здесь есть возможность читать онлайн «Artificial Intelligence and Data Mining Approaches in Security Frameworks» — ознакомительный отрывок электронной книги совершенно бесплатно, а после прочтения отрывка купить полную версию. В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Жанр: unrecognised, на английском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.

- Название:Artificial Intelligence and Data Mining Approaches in Security Frameworks
- Автор:
- Жанр:
- Год:неизвестен
- ISBN:нет данных
- Рейтинг книги:4 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
Artificial Intelligence and Data Mining Approaches in Security Frameworks: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «Artificial Intelligence and Data Mining Approaches in Security Frameworks»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
This book provides state of the art approaches of artificial intelligence and data mining in these areas. It includes areas of detection, prediction, as well as future framework identification, development, building service systems and analytical aspects. In all these topics, applications of AI and data mining, such as artificial neural networks, fuzzy logic, genetic algorithm and hybrid mechanisms, are explained and explored. This book is aimed at the modeling and performance prediction of efficient security framework systems, bringing to light a new dimension in the theory and practice.
This groundbreaking new volume presents these topics and trends, bridging the research gap on AI and data mining to enable wide-scale implementation. Whether for the veteran engineer or the student, this is a must-have for any library.
Artificial Intelligence and Data Mining Approaches in Security Frameworks — читать онлайн ознакомительный отрывок
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «Artificial Intelligence and Data Mining Approaches in Security Frameworks», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
It is possible in Apriori to count the candidates of a cardinality k with the help of a single scan of a large database. Most important limitation of apriori algorithm is to look up the candidates in each transaction. To do the same, a hash tree structure is used (Jacobsan et al. , 2014). An extension of Apriori, i.e., Apriori-TID, signifies the current candidate on which each transaction is based, while a raw database is sufficient for a normal Apriori. Apriori and Apriori-TID when combined form Apriori-Hybrid. A prefix-tree is used to fix up the parting that occurs between the processes, counting and candidate generation in Apriori-DIC.
2.3 Clustering
A data mining technique is used for grouping a set of objects in such a way that there is more similarity in the objects of the same class as compared to the objects of the other class. It means cluster of same class, i.e., similarity of intra-cluster is maximum and similarity of inter-cluster is minimum. Unsupervised learning can be performed with the help of clustering. Following are the types of clustering algorithms:
1 a) Distribution Based
2 b) Density Based
3 c) Centroid Based
4 d) Connection Based or Hierarchical Clustering
5 e) Recent Clustering Techniques
a) Distribution-Based Clustering
A model of clustering in which the date is grouped/fitted in the model on the basis of probability, i.e., in what way it may fit into the same distribution. Thus, the groups formed will be on the basis of either normal distribution or gaussian distribution
b) Density-Based Clustering
In this type of clustering, a cluster is formed with the help of area with higher density as compared to the rest of the data.
Following are three most frequently used Density-based Clustering techniques:
1 i) Mean-Shift
2 ii) OPTICS
3 iii) DBSCAN
c) Centroid-Based Clustering
Clusters that are represented by a vector are a part of centroid-based clustering. It is not a mandate requirement that these clusters should be a part of the given dataset. The number of clusters is inadequate to size k in k means clustering algorithm; therefore, it is essential to find centres of k cluster and allocate objects to their nearest centres. By taking different values of k random initializations, this algorithm runs multiple times to select the best of multiple runs (Giannotti et al. , 2013). In k medoid clustering, clusters are firmly limited to the members of the dataset, whereas in k medians clustering, median is taken to form a cluster; the foremost drawback of these techniques is that we have to select the number of clusters beforehand.
d) Connection-Based (Hierarchical) clustering
As the name itself suggests, this type of clustering is performed on the basis of closeness or distance of objects. The most important key point to form these types of cluster is the distance between the objects by which they can be connected with each other and form clusters. Instead of single partitioning of dataset, these algorithms provide an in-depth hierarchy of merging clusters at particular distances. To represent clusters, a dendrogram is used. Merging distance of the clusters is shown on the y-axis and an object placement shows the x-axis to ensure that there should not be the mixing of clusters.
On the basis of the different ways with which distance is calculated, there are several types of connection-based clusters:
1 i) Single-Linkage Clustering
2 ii) Complete-Linkage
3 iii) Average-Linkage Clustering
e) Recent Clustering Techniques
For high dimensional data, the above-mentioned standard clustering techniques are not fit, therefore some new techniques are being discovered. These new techniques can be classified into two major categories, namely: Subspace Clustering and Correlation Clustering.
A small list of attributes that should be measured for the formation of a cluster is taken into consideration under subspace clustering. Correlation between the chosen attributes can also be performed with correlation clustering.
2.4 Privacy Preserving Data Mining (PPDM)
To extract the pertinent knowledge from large volumes of data and to protect all sensitive information of that database, we use privacy preserving data mining (PPDM). These techniques are created with the aim to confirm the protection of sensitive data so that privacy can be reserved with the efficient performance of all data mining operations. There are two classes of privacy concerned data mining techniques:
1 Data privacy
2 Information privacyModification of database for the protection of sensitive data of the individuals, we use data privacy technique. If there is a requirement for the modification of sensitive knowledge that can be deduced from the database, information privacy technique is preferred. To provide privacy to input, data privacy is preferable, whereas for providing privacy to output, the technique of information privacy is used. To reserve personal information from exposure is the main focus of a PPDM algorithm. It relies on the analysis of those mining algorithms that are attained during data privacy. Main objective of Privacy Preserving Data Mining is building algorithms that convert the original data in some useful means, so that there is no visibility of private data and knowledge even after a successful mining process. Privacy laws would allow the access in the case that some related satisfactory benefit is found resulting from the access.
2.5 Intrusion Detection Systems (IDS)
Onset detection of the intrusion is the main aim of an Intrusion detection system. There is a requirement of a high level of human knowledge and substantial amount of time to attain security in data mining. However, intrusion detection systems based on data mining need less expertise for better performance. To perceive network attacks in contrast to services that are vulnerable, intrusion detection system is very helpful. Applications-based data-driven attacks always privilege escalation (Thabtah et al. , 2005), un-authorized logins and files accessibility is very sensitive in nature (Hong, 2012). Data mining process can be used as a tool for cyber security for the competent detection of malware from the code. Figure 2.3shows the outline of an intrusion detection system. Several components such as, sensors, a console monitor and a central engine forms the complete intrusion detection system. Security events are generated by sensors whereas the task of console monitor is to monitor and control all events and alerts. The main function of the central engine is recording of events in a database and on the basis of these events, alerts can be created followed by certain set of rules. Following factors are responsible for the classification of an intrusion detection system:
1 i) Location
2 ii) Type of Sensors
3 iii)Technique used by the Central engine for generation of alerts.
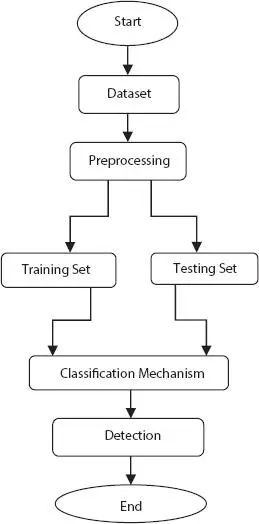
Figure 2.3 An overview of intrusion detection system (IDS).
All the three components of an intrusion detection system can be integrated into a single device.
2.5.1 Types of IDS
Detection of an intrusion could be done either on a network or with an individual system and therefore we have three types of IDS, namely: Network Based, Host Based and Hybrid IDS.
2.5.1.1 Network-Based IDS
Computer networks have been targeted by enemies and criminals because of their progressively dynamic roles in modern societies. It is very important to find the best possible solutions for the sake of protection of our systems. Various techniques of intrusion prevention like programming errors avoidance, protection of information using encryption techniques and biometrics or passwords (Zhan et al. , 2005) can be used as a first line of security. By using intrusion prevention technique as the only protection measure, our system is not 100% safe from combat attacks. To provide an additional security for computer system, the above-mentioned techniques are used. Various resources like accounts of users, their file systems and the system kernels of a target system must be protected by an intrusion detection system. For network-based intrusion detection systems, data source is the network packets. To listen and analyse network traffic as the packets travel across the network, the network-based intrusion detection system (NIDS) makes use of a network adapter. A network-based intrusion detection system is used to generate alerts for the detection of an intrusion which is outside of the boundary of its enterprise.
Читать дальшеИнтервал:
Закладка:
Похожие книги на «Artificial Intelligence and Data Mining Approaches in Security Frameworks»
Представляем Вашему вниманию похожие книги на «Artificial Intelligence and Data Mining Approaches in Security Frameworks» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.












Обсуждение, отзывы о книге «Artificial Intelligence and Data Mining Approaches in Security Frameworks» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.