Jorge Mauricio Molina Mejía - Lingüística computacional y de corpus
Здесь есть возможность читать онлайн «Jorge Mauricio Molina Mejía - Lingüística computacional y de corpus» — ознакомительный отрывок электронной книги совершенно бесплатно, а после прочтения отрывка купить полную версию. В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Жанр: unrecognised, на испанском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.

- Название:Lingüística computacional y de corpus
- Автор:
- Жанр:
- Год:неизвестен
- ISBN:нет данных
- Рейтинг книги:4 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
Lingüística computacional y de corpus: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «Lingüística computacional y de corpus»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
Lingüística computacional y de corpus — читать онлайн ознакомительный отрывок
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «Lingüística computacional y de corpus», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
Introducción a la lingüística computacional y a la lingüística de corpus
¿Por qué iniciar este libro vinculando la lingüística computacional y la lingüística de corpus? ¿Se trata acaso de dos campos disciplinares diferenciados, o de un gran campo que recubre al otro? Como veremos en este y en los capítulos que siguen, existe una estrecha relación entre ambos campos del conocimiento. Por una parte, la lingüística computacional permite el análisis del lenguaje a partir de herramientas y programas informáticos creados específicamente para ese fin; por otra parte, el trabajo cada vez más importante de la lingüística de corpus hace posible la recolección metódica de textos o grabaciones (en audio o en video) de producciones del ser humano, que más adelante pueden estudiarse gracias al desarrollo de la informática.
Si bien es cierto que es factible trabajar sobre corpus sin la necesidad de emplear para ello herramientas computacionales, también es cada vez más evidente la creciente utilización de los computadores en lo que respecta a la recopilación, el análisis y el tratamiento informático de las grandes colecciones de textos, de archivos de audio o de video, lo que desde hace ya varias décadas se ha denominado lingüística de corpus. Esta particular forma de realizar el trabajo investigativo nos va alejando, cada vez más, del trabajo “manual” que antaño se efectuaba a partir de los corpus. Por otra parte, nos enfrentamos a un creciente empleo de grandes masas de datos para alimentar los sistemas de análisis del lenguaje humano. La lingüística computacional necesita, por lo tanto, de grandes corpus para poder mejorar los sistemas de corrección automática, de etiquetado morfosintáctico o lexicográfico, de autocompletado de textos, de revisión ortográfica y gramatical, etc. Como podemos constatar, se trata de dos campos que necesitan el uno del otro para retroalimentarse y poder ser mejorados día a día.
En las siguientes secciones, pasamos a describir la importancia de estos campos pertenecientes a las ciencias del lenguaje, tratando de mostrar, en cada caso, la utilidad que en la actualidad ofrecen para el estudio del lenguaje y la comunicación humanas.
Importancia de la lingüística computacional
Podemos constatar que en la época actual el empleo de la informática dentro del estudio de las lenguas naturales no nace de un simple uso tecnológico o de una suerte de “moda”; el afán de los lingüistas computacionales (ya sea de lingüistas con conocimientos en el campo de la informática o de ingenieros de sistemas con conocimientos en el campo de la lingüística) se debe a un gran interés por proporcionar a las ciencias del lenguaje mejores herramientas (generalmente gratuitas o de libre acceso) que permitan estudiar y trabajar a partir de grandes cantidades de datos lingüísticos, con el fin de que cualquier interesado en dichos datos pueda comprobar de manera estadística diversas hipótesis desde diferentes posturas teóricas, pero siempre a partir de datos comprobables de forma científica.
Según lo plantean autores como Bolshakov y Gelbukh (2004), la lingüística computacional se encuentra ligada a las llamadas ciencias del lenguaje. Podemos apreciar en la figura 0.1 el rol preponderante que esta ha ido adquiriendo en varios campos de la lingüística y como centro de lo que se ha llamado “la lingüística aplicada”, de manera que se pueden ver las intersecciones entre este y otros campos del conocimiento afines, como las matemáticas, la psicología, la lexicografía y la lingüística general. Tales intersecciones, en nuestro concepto, deberían demostrar una retroalimentación entre estos diversos campos, complementados, además, por disciplinas que no provienen necesariamente de las ciencias del lenguaje, como las matemáticas y la psicología, que llevan al nacimiento de dos subcampos de la lingüística: la lingüística matemática y la psicolingüística, respectivamente.
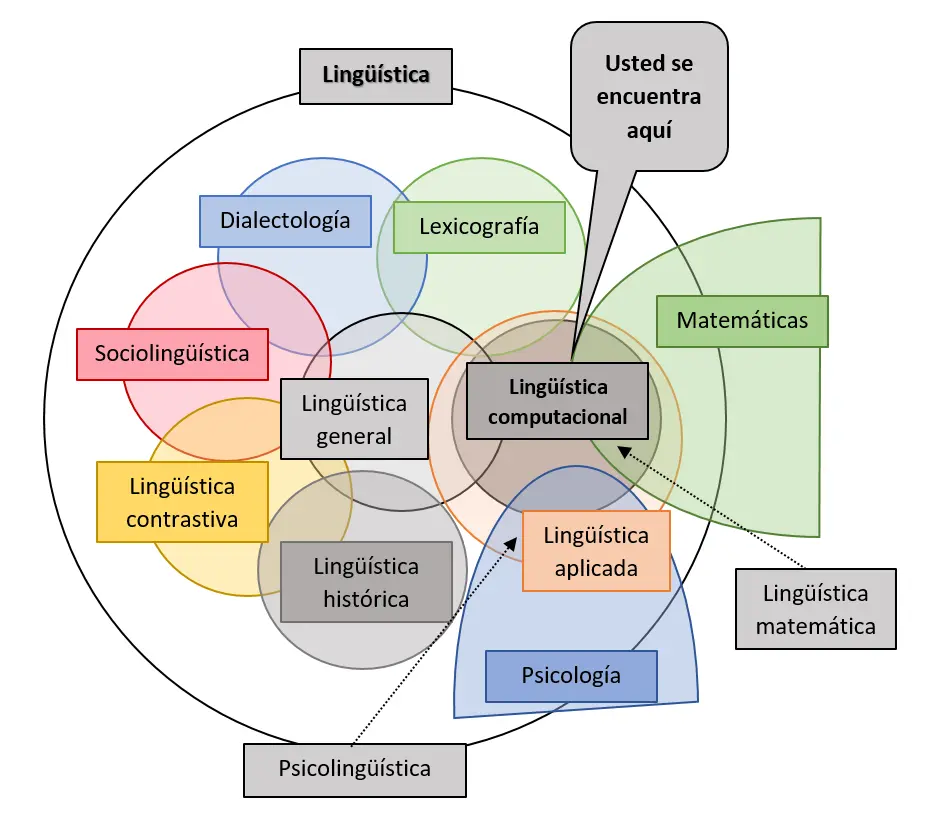
Figura 0.1. La lingüística computacional dentro de las ciencias del lenguaje
Fuente: traducción y adaptación de Bolshakov y Gelbukh (2004, p. 18).
Aquí podríamos agregar, sin ningún tipo de problema, el campo relativo a las ciencias de la cognición —el aprendizaje y la enseñanza—. Nos referimos, por supuesto, a los campos conocidos como alao y elao, que nombran el aprendizaje y la enseñanza de lenguas asistidos por ordenador, los cuales tienen sus bases en la lingüística computacional y el procesamiento del lenguaje natural (Antoniadis, 2008 y 2010; Chanier, 1998a; L’Haire, 2011; Loiseau, 2009; Molina Mejía, 2015).
Finalmente, podemos constatar, como los profesores Hirschberg y Manning (2015, p. 261), que la lingüística computacional se ha ido transformando paulatinamente, en las dos últimas décadas, en un magnífico campo de investigación científica y de práctica tecnológica. Esto, según los mismos autores, se ha visto reflejado en varios productos dirigidos al consumidor final de este tipo de tecnologías (caso, por ejemplo, de las aplicaciones Siri para Apple y Skype Translator, el traductor simultáneo de Skype, entre otras). En pocas palabras, se puede decir que hoy en día la lingüística computacional afecta nuestra vida personal y social de una manera palpable, aunque muchas personas la utilicen a diario sin siquiera percatarse de ello.
Necesidad de trabajar a partir de una lingüística de corpus
En realidad, este aspecto del lenguaje no solamente se aplica a la recolección de corpus en los subcampos de la lingüística; de hecho, se utiliza en otros campos del conocimiento: literatura, sociología, antropología, política, derecho, medicina, ingenierías, etc., en los que se ha vuelto necesario, por su propia naturaleza y por lo que ofrecen a la sociedad, trabajar a partir de datos reales de tipo escrito u oral, reunidos en corpus o en grandes colecciones de documentos. En este sentido, se puede observar el trabajo que se efectúa en la literatura con corpus que permiten el estudio de metáforas, figuras retóricas, en la edición crítica; en antropología, los corpus sirven para el estudio de fenómenos ligados al habla, la escritura y la cultura de diferentes pueblos del mundo; en la medicina, este tipo de trabajo ayuda en el tratamiento de enfermedades mentales, como el alzhéimer, el párkinson, entre otras. Así mismo, usar estas masas de datos auténticos y reales en trabajos de las diversas disciplinas que se han mencionado permite corroborar, de manera estadística, la información recolectada. De modo que en subcampos o niveles de análisis, en este caso de la lingüística (la morfología, la sintaxis, la fonética y la fonología, la pragmática y la semántica) o de las ciencias del lenguaje (sociolingüística, dialectología, lexicografía, la lingüística histórica, etc.), la utilización de grandes colecciones de textos y grabaciones se hace imprescindible para el estudio de fenómenos particulares, cuyas hipótesis asociadas puedan ser corroboradas gracias a datos reales; es allí donde la lingüística de corpus y la estadística van de la mano, pues su trabajo conjunto hace posible comprobar dichas hipótesis de una forma científica.
Ya sea en cuanto a su aceptación como campo teórico o a su empleo como metodología de trabajo (asunto que se verá más adelante, en el capítulo 4), la lingüística de corpus es, sin lugar a dudas, un terreno de vasta investigación y trabajo en la actualidad.
Veamos, en la sección siguiente, la manera como la lingüística computacional está al servicio de la lingüística de corpus, y viceversa, al ir de un trabajo interdisciplinario a uno pluridisciplinario, en el que participarán otras disciplinas y campos del conocimiento humanístico y tecnológico.
Читать дальшеИнтервал:
Закладка:
Похожие книги на «Lingüística computacional y de corpus»
Представляем Вашему вниманию похожие книги на «Lingüística computacional y de corpus» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.












Обсуждение, отзывы о книге «Lingüística computacional y de corpus» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.