Elisabeth Steiner - Der Fragebogen
Здесь есть возможность читать онлайн «Elisabeth Steiner - Der Fragebogen» — ознакомительный отрывок электронной книги совершенно бесплатно, а после прочтения отрывка купить полную версию. В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Жанр: unrecognised, на немецком языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.

- Название:Der Fragebogen
- Автор:
- Жанр:
- Год:неизвестен
- ISBN:нет данных
- Рейтинг книги:3 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
Der Fragebogen: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «Der Fragebogen»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
Wie plant man eine empirische Erhebung? Wie gestaltet man einen Fragebogen? Wie werden die Daten analysiert und interpretiert? In gut nachvollziehbaren Schritten bietet dieses Lehrbuch einen praktischen Leitfaden für die Umsetzung wissenschaftlicher Erhebungen.
Das Buch behandelt von der Formulierung einer Forschungsidee über die Konstruktion eines Fragebogens bis hin zu den wichtigsten Auswertungsschritten mit dem Statistikprogramm SPSS, Version 26, alle wichtigen Stufen und beinhaltet viele Beispiele.
Der Fragebogen — читать онлайн ознакомительный отрывок
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «Der Fragebogen», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
Eine weitere gängige Methode der Deskriptivstatistik, um Stichproben zu beschreiben, besteht darin, sogenannte deskriptivstatistische Maßzahlen zu berechnen. Die bekanntesten sind das arithmetische Mittel (meist nur „Mittelwert“ genannt) und die Standardabweichung (dazu eine ausführliche Beschreibung in Kapitel 6), die dazugehörige Streuung.
Den Mittelwert (x̄ = arithmetisches Mittel) erhält man, indem alle Messwerte (wie z. B. das Alter in Jahren) addiert werden und die resultierende Summe durch die Anzahl der Messwerte (n = Stichprobengröße) dividiert wird.
x̄ = 24 Jahre für die männliche Stichprobe
Zieht man einen der siebzig Studenten aus der Gruppe und erfragt sein Alter, so ist die Wahrscheinlichkeit hoch, dass es im Bereich um 24 Jahre liegt. Allerdings ist die Angabe des Mittelwertes praktisch sinnlos, wenn man nichts über die Verteilung der ursprünglichen Messwerte weiß. In einer Stichprobe von drei 20-jährigen Personen beträgt der Mittelwert zwanzig Jahre [(20 + 20 + 20) / 3 = 20]. Auch in einer Stichprobe mit einem 10-Jährigen, einem 11-Jährigen und einem 39-Jährigen macht der Mittelwert zwanzig Jahre aus [(10 + 11 + 39) / 3 = 20].
Dies führt uns zum nächsten Schritt – der Angabe der dazugehörigen Streuungsmaße (Dispersionsmaße), die Aufschluss über die „Differenzen“ in der Altersverteilung geben können, z. B. die Standardabweichung = s = 3 Jahre.
Das heißt, in Kombination mit der Angabe des Mittelwerts von 24 Jahren kann unter der Annahme der Normalverteilung (dazu ebenfalls mehr in Kapitel 6) davon ausgegangen werden, dass rund 68 % der Studenten im Altersbereich von 21 bis 27 Jahren liegen (d. h. im Bereich 24 Jahre +/– 3 Jahre).
Durch die so durchgeführte Beschreibung der Stichprobe gewinnt man bereits einen guten Überblick über deren Charakteristika, also wesentliche Informationen über ihre Beschaffenheit: Wir wissen bis jetzt, dass die Stichprobe aus 57 weiblichen und 70 männlichen Studierenden besteht. Dies könnte mit einer Häufigkeitstabelle unter der zusätzlichen Angabe von Prozenten noch ergänzt werden. Der Altersdurchschnitt der männlichen Studierenden liegt bei 24 Jahren. Und rund 68 % der männlichen Studierenden liegen im Altersbereich von 21 bis 27 Jahren.
Statistische Methoden zur Beschreibung der Daten von Stichproben in Form von Grafiken, Tabellen oder einzelnen Kennwerten (Lagemaße bzw. Streuungsmaße) bezeichnen wir zusammenfassend als deskriptive (beschreibende) Statistik.
Sie gibt einen Überblick über die Merkmalsausprägungen einzelner Variablen und stellt oft eine fundierte Basis für weitere statistische Berechnungen dar.
1.1.2 Inferenzstatistik (beurteilende bzw. schließende Statistik)
Auf Basis von Erfahrungen, Beobachtungen und Wissen ziehen wir Rückschlüsse – dieser Prozess wird als Inferenz bezeichnet. Dabei können zwei Zugänge verfolgt werden: Vom „Allgemeinen“ auf das „Besondere“ zu schließen wird als deduktiver Zugang bezeichnet. Im Gegensatz dazu spricht man vom induktiven Zugang, wenn man vom „Besonderen“ auf das „Allgemeine“ schließen möchte. Durch diese Differenzierung werden auch grob qualitative von quantitativen Forschungszugängen unterschieden.
Während die Deskriptivstatistik eine Stichprobe beschreibt, ermöglicht die Inferenzbzw. analytische oder beurteilende Statistik, über diese Stichprobe hinaus etwas über die dahinterstehende Grundgesamtheit (Population) auszusagen, also Verallgemeinerungen zu treffen.
Die Inferenzstatistik bzw. „Beurteilende (Schließende) Statistik untersucht […] nur einen Teil, der für die Grundgesamtheit, deren Eigenschaften uns interessieren, charakteristisch oder repräsentativ sein soll“ (Hedderich & Sachs, 2011, S. 9).
Die Grundidee liegt also darin, von einer kleinen Auswahl (Stichprobe) auf die dahinterliegende Grundgesamtheit zu schließen.
Es gibt neben den bereits erwähnten Begrifflichkeiten Inferenzstatistik, beschreibende bzw. analytische Statistik auch noch die Bezeichnung induktive (hinführende) Statistik. Alltagssprachlich wird eine solche Hinführung als logischer Schluss dargestellt. Die Verwendung dieser Begriffe verwirrt oft, bezeichnet aber den gleichen Zugang zur Statistik.
Wir stellen in der Stichprobe fest, dass sich die männlichen von den weiblichen Studierenden hinsichtlich des Lernaufwandes für eine bestimmte Prüfung unterscheiden, also eine Gruppe für dieselbe Prüfung länger lernt. Mittels der Methoden der Inferenzstatistik, mit denen wir uns später beschäftigen werden, kann nun festgestellt werden, ob es sich in der Grundgesamtheit (alle StudentInnen dieser Studienrichtung an dieser Universität) genauso wie in der Stichprobe verhält. Dieses Schließen von der Stichprobe auf das Dahinterstehende – die Grundgesamtheit – ist allerdings nicht mit absoluter Sicherheit möglich, sondern nur mit einer bestimmten Wahrscheinlichkeit. Die Verallgemeinerung auf die Population ist stets unsicher. Wir können mithilfe statistischer Auswertungen prinzipiell nur Wahrscheinlichkeitsaussagen treffen – und dies mit unterschiedlicher Genauigkeit.
In sozialwissenschaftlichen Untersuchungen möchte man also meist über die Beschreibung einer ausgewählten (spezifischen) Gruppe von Untersuchungseinheiten (Stichproben) hinausgehen und allgemein gültige Aussagen treffen. Dazu ist die rein deskriptive Statistik, die Beschreibung der Daten in Form von Häufigkeitstabellen, Grafiken und einzelnen Kennwerten, in den wenigsten Fällen ausreichend.
Die Inferenzbzw. beurteilende Statistik nimmt sich des Problems an, wie man Ergebnisse, die an einer verhältnismäßig kleinen Zahl von Personen (Stichprobe) gewonnen wurden, auf die Grundgesamtheit (Population) umlegen, also allgemein gültige Aussagen treffen kann. Die allgemein gültige Aussage (über die Grundgesamtheit) wird als Hypothese formuliert, die anhand von Stichproben zu überprüfen ist. Hierin liegt ein wesentlicher Unterscheidungspunkt der zwei Zugänge. Die Inferenzstatistik stellt Hypothesen auf und ermöglicht deren Überprüfung.
Aus der Grundgesamtheit wird eine von vielen möglichen Stichproben gezogen. Die folgende Abbildung 1.2verdeutlicht dies. Aus einer größeren Grundgesamtheit (der große Kreis) gibt es nahezu unendlich viele Möglichkeiten, einzelne Stichproben (kleine Kreise) zu erhalten. Wichtig ist, dass diese gezogene Stichprobe „repräsentativ“ ist, also die wesentlichen Charakteristika der Grundgesamtheit widerspiegelt.
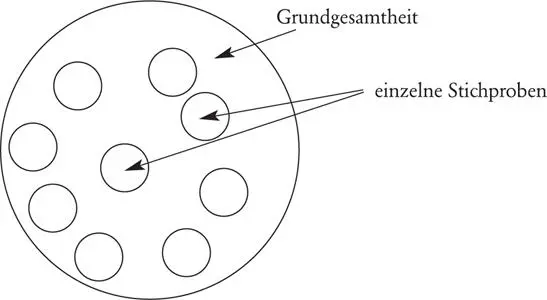
Abb. 1.2: Grundgesamtheit mit verschiedenen Stichprobenziehungen
Ein bekanntes Anwendungsgebiet ist die Hochrechnung vor Wahlen. Die Meinungsforschungsinstitute konkurrieren jeweils um die korrekteren Vorhersagen des Wahlausgangs. Sie gehen dabei so vor, dass sie eine kleine (aber repräsentative) Stichprobe von WählerInnen befragen, von der sie auf die Grundgesamtheit der Bevölkerung schließen können.
Repräsentativität bedeutet in diesem Beispiel, dass die „kleine“ ausgewählte Gruppe möglichst die reale Situation der „Grundgesamtheit“ beschreibt, also die Variablen (Eigenschaften), wie z. B. Geschlecht, Alter, Ausbildungsstand, soziale Schicht usw., real abgebildet sind.
Natürlich sind Ergebnisse, die aufgrund von Daten einer Stichprobe gewonnen werden, mit Ungenauigkeiten behaftet. Das ist auch der Grund, weshalb bei einer Wahlprognose stets ein Bereich angegeben wird, z. B. +/–2 %, in dem das „wahre“ Ergebnis (also der An teil der WählerInnen an der Grundgesamtheit) mit gewisser Wahrscheinlichkeit liegt.
Neben den Ergebnissen, die durch analytische Verfahren gewonnen werden, können deskriptivstatistische zusätzlich zu einer übersichtlichen und anschaulichen Informationsaufbereitung beitragen.
Читать дальшеИнтервал:
Закладка:
Похожие книги на «Der Fragebogen»
Представляем Вашему вниманию похожие книги на «Der Fragebogen» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.












Обсуждение, отзывы о книге «Der Fragebogen» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.