Elisabeth Steiner - Der Fragebogen
Здесь есть возможность читать онлайн «Elisabeth Steiner - Der Fragebogen» — ознакомительный отрывок электронной книги совершенно бесплатно, а после прочтения отрывка купить полную версию. В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Жанр: unrecognised, на немецком языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.

- Название:Der Fragebogen
- Автор:
- Жанр:
- Год:неизвестен
- ISBN:нет данных
- Рейтинг книги:3 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
Der Fragebogen: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «Der Fragebogen»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
Wie plant man eine empirische Erhebung? Wie gestaltet man einen Fragebogen? Wie werden die Daten analysiert und interpretiert? In gut nachvollziehbaren Schritten bietet dieses Lehrbuch einen praktischen Leitfaden für die Umsetzung wissenschaftlicher Erhebungen.
Das Buch behandelt von der Formulierung einer Forschungsidee über die Konstruktion eines Fragebogens bis hin zu den wichtigsten Auswertungsschritten mit dem Statistikprogramm SPSS, Version 26, alle wichtigen Stufen und beinhaltet viele Beispiele.
Der Fragebogen — читать онлайн ознакомительный отрывок
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «Der Fragebogen», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
3 Die Untersuchungsplanung – von der Idee zur empirischen Forschung
3.1 Die Themensuche
3.1.1 Das Anlegen einer Ideensammlung
3.1.2 Die Replikation von Untersuchungen
3.1.3 Die Mitarbeit an Forschungsprojekten
3.1.4 Weitere kreative Anregungen
3.2 Konkretisierung und Formulierung einer Forschungsfrage
3.3 Die Literaturrecherche
3.4 Auswahl der Untersuchungsart – Forschungsdesign
3.5 Ethische Bewertung einer Forschungsfrage
3.6 Zusammenfassung des Kapitels
3.7 Übungsbeispiele
4 Datenerhebung: Die schriftliche Befragung (Fragebogen)
4.1 Methoden der quantitativen Datenerhebung
4.2 Allgemeine inhaltliche Vorbemerkungen zur Fragebogenkonstruktion
4.3 Erste inhaltliche Schritte
4.4 Prinzipien der Konstruktion
4.4.1 Fragenauswahl
4.4.2 Einleitung, Instruktion und Anrede
4.4.3 Richtlinien zur Formulierung der Items
4.4.4 Antwortformate
4.5 Pretest
4.6 Negative Antworttendenzen
4.6.1 Absichtliche Verstellung
4.6.2 Soziale Erwünschtheit (Social Desirability)
4.6.3 Akquieszenz oder „Ja-Sage-Bereitschaft“ 62
4.6.4 Bevorzugung von extremen, unbestimmten oder besonders platzierten Antwortkategorien
4.6.5 Wahl von Antwortmöglichkeiten, die eine bestimmte Länge, Wortfolge oder seriale Position aufweisen
4.6.6 Verfälschung aufgrund der Tendenz, zu raten, oder aufgrund einer raschen Bearbeitung des Tests
4.6.7 Tendenz zur ersten passenden Kategorie
4.6.8 Beeinflussung durch motivationale Bedingungen
4.6.9 „Mustermalen“
4.7 Zusammenfassung des Kapitels
4.8 Übungsbeispiele
5 Computerunterstützte Datenaufbereitung mittels SPSS
5.1 Was ist SPSS?
5.2 Vom Fragebogen zur SPSS-Datei
5.2.1 Wie rufe ich SPSS auf?
5.2.2 Wichtige Anmerkungen vor der Dateneingabe
5.2.3 Kodierung und Kodeplan
5.2.4 Erstellung eines Datenfiles
5.2.5 Datencheck/Data-Cleaning
5.2.6 Weitere Datenaufbereitung
5.3 Zusammenfassung des Kapitels
5.4 Übungsbeispiele
6 Deskriptivstatistische Datenanalyse
6.1 Tabellarische Darstellung der Daten
6.1.1 Häufigkeitstabellen
6.1.2 Kreuztabellen bzw. Kontingenztafeln
6.2 Grafische Darstellung der Daten
6.2.1 Balkendiagramme
6.2.2 Histogramme
6.2.3 Boxplots
6.2.4 Streudiagramme
6.3 Lagemaße – Lokalisationsparameter
6.3.1 Normalverteilung
6.3.2 Das arithmetische Mittel – der Mittelwert
6.3.3 Der Median
6.3.4 Der Modus (Modalwert)
6.4 Dispersionsmaße (Streuungsmaße)
6.4.1 Varianz
6.4.2 Standardabweichung
6.4.3 Der Quartilabstand
6.4.4 Spannweite
6.4.5 Perzentilwerte
6.5 Zusammenfassung des Kapitels
6.6 Übungsbeispiele
7 Schluss von der Stichprobe auf die Population
7.1 Alltags- und statistische Hypothesen
7.2 Statistischer Test
7.3 Fehler erster und zweiter Art und die Macht eines Tests
7.4 Der Standardfehler des Mittelwerts
7.5 Zusammenfassung des Kapitels
7.6 Übungsbeispiele
8 Statistische Tests
8.1 T-Test für unabhängige Stichproben
8.2 T-Test für abhängige Stichproben
8.3 U-Test nach Mann & Whitney
8.4 Wilcoxon-Test
8.5 Friedman-Test
8.6 Vierfelder-Chi-Quadrat-Test
8.7 Zusammenfassung des Kapitels
8.8 Übungsbeispiele
9 Korrelation und lineare Regression
9.1 Produkt-Moment-Korrelation
9.2 Rangkorrelation nach Spearman
9.3 Vierfelderkorrelation
9.4 Partielle Korrelation
9.5 Biseriale Korrelation
9.6 Korrelation und Kausalität
9.7 Einfache lineare Regression
9.8 Multiple lineare Regression
9.9 Zusammenfassung des Kapitels
9.10 Übungsbeispiele
10 Varianzanalyse
10.1 Grundlagen der Varianzanalyse
10.2 Einfaktorielle Varianzanalyse ohne Messwiederholung
10.3 Einfaktorielle Varianzanalyse mit Messwiederholung
10.4 Zusammenfassung des Kapitels
10.5 Übungsbeispiele
11 Der statistische Auswertungsbericht
11.1 Der Theorieteil
11.2 Der Methodenteil
11.3 Der Ergebnisteil
11.4 Diskussion und Ausblick
11.5 Einige Zitierregeln
11.6 Das Literaturverzeichnis
11.7 Zusammenfassung des Kapitels
11.8 Übungsbeispiele
Anhang
Lösungen zu den Übungsbeispielen
Beispiel: Fragebogen zur Studien- und Lebenssituation bei Studierenden
Literaturverzeichnis
Stichwortverzeichnis
1 Elementare Definitionen
1.1 Deskriptive Statistik und Inferenzstatistik
Grundsätzlich wird bei der Analyse quantitativer Beobachtungen bzw. Messungen und deren Beschreibung die Inferenzstatistik von der Deskriptivstatistik unterschieden. Diese beiden prinzipiellen Zugänge in der Statistik sollen im folgenden Kapitel in ihrer Unterschiedlichkeit und Anwendbarkeit genauer dargestellt werden. Diese Darstellungsform soll jedoch nicht den falschen Eindruck entstehen lassen, dass die beiden Zugänge konkurrierend auftreten. In der Praxis stellen sie einander ergänzende und inhaltlich bereichernde Zugänge dar.
1.1.1 Deskriptivstatistik (beschreibende Statistik)
„Ein wesentlicher Teil der Statistik ist die Datenbeschreibung einschließlich einer systematischen Suche nach aufschlussreichen Informationen über die Struktur eines Datenkörpers. Strukturen in den Daten und bedeutsame Abweichungen von diesen Strukturen sollen aufgedeckt werden.“ (Hedderich & Sachs, 2011, S. 11)
Es werden also bestimmte Charakteristika (Eigenschaften) einer Stichprobe beschrieben, allerdings noch ohne den Anspruch, etwas über die dahinterstehende Grundgesamtheit (Population) auszusagen. Dies wäre der Ansatz, den die Inferenzstatistik verfolgt. Bei dieser Beschreibung interessieren im Grunde die Ableitungen von gewissen, in den Daten auffindbaren Gesetzmäßigkeiten, die auch die Basis für weitere inferenzstatistische Verwertungen darstellen.
Es handelt sich um einen summarischen Zugang zu quantitativen Informationen. Wenn wir z. B. etwas über eine Stichprobe von Studierenden (n = 127) wissen möchten, müssen wir im ersten Schritt entscheiden, welche Eigenschaften dieser Stichprobe uns interessieren, und im nächsten Schritt, ob wir diese Eigenschaften zunächst grafisch veranschaulichen und/oder ob Maßzahlen wie Mittelwerte und Streuungen zur Beschreibung herangezogen werden (mehr dazu in Kapitel 6). Wir müssen also entscheiden, wie wir die wichtigsten „Eigenschaften“ der Stichprobe in geeigneter Form und gut überschaubar darstellen.
Nehmen wir an, uns interessiert die Geschlechterverteilung in der Stichprobe der 127 Studierenden. Für ihre Darstellung würde sich aufgrund der geringen Anzahl der Ausprägungen der Variable Geschlecht, nämlich männlich und weiblich, eine einfache Grafik wie das Kreisdiagramm ( Abb. 1.1) anbieten:
Besteht diese Stichprobe von StudentInnen aus 70 männlichen und 57 weiblichen Personen, wird die Verteilung durch das Kreisdiagramm auf einfache und anschauliche Art und Weise grafisch dargestellt.
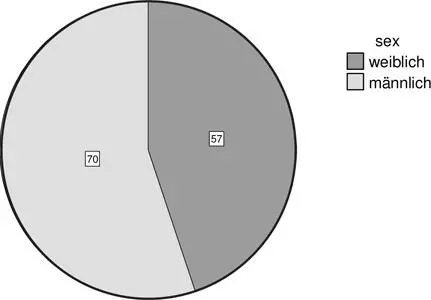
Abb. 1.1: Geschlechterverteilung/Angabe in absoluten Häufigkeiten
Eine weitere deskriptivstatistische Methode wäre die Darstellung einer einfachen Häufigkeitstabelle.
In Tabelle 1.1sind zusätzlich zu diesen absoluten Häufigkeiten von 70 und 57 die Prozente angegeben. Man berechnet sie, indem man die absoluten Zahlen jeder Gruppe durch die Stichprobengröße dividiert und anschließend mit 100 multipliziert (57/127 = 44,9% und 70/127 = 55,1 %).
Tab. 1.1: Geschlechterverteilung/Häufigkeiten und Prozent
| Häufigkeit | Prozetn | ||
| Gültig | weiblich | 57 | 44,9% |
| männlich | 70 | 55,1% | |
| Gesamt | 127 | 100,0% |
Natürlich ist Statistik mit Informationsreduktion verbunden, das ist eine ihrer Grundideen und bedeutet in unserem Beispiel: Aus dem Kreisdiagramm ( Abb. 1.1) oder der Tabelle ( Tab. 1.1) ist nicht mehr ersichtlich, welches Individuum der Stichprobe männlich oder weiblich ist. Wir kennen nur noch die entsprechenden Anteile (45 % und 55 %) bzw. Häufigkeiten (57 und 70).
Читать дальшеИнтервал:
Закладка:
Похожие книги на «Der Fragebogen»
Представляем Вашему вниманию похожие книги на «Der Fragebogen» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.












Обсуждение, отзывы о книге «Der Fragebogen» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.