Derek Molloy - Raspberry Pi® a fondo para desarrolladores
Здесь есть возможность читать онлайн «Derek Molloy - Raspberry Pi® a fondo para desarrolladores» — ознакомительный отрывок электронной книги совершенно бесплатно, а после прочтения отрывка купить полную версию. В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Жанр: unrecognised, на испанском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.

- Название:Raspberry Pi® a fondo para desarrolladores
- Автор:
- Жанр:
- Год:неизвестен
- ISBN:нет данных
- Рейтинг книги:3 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
Raspberry Pi® a fondo para desarrolladores: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «Raspberry Pi® a fondo para desarrolladores»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
Raspberry Pi® a fondo para desarrolladores — читать онлайн ознакомительный отрывок
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «Raspberry Pi® a fondo para desarrolladores», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
Cómo utilizar Git para el control de versiones
De manera sencilla podemos decir que Git es un sistema que nos permite registrar cualquier cambio que se introduzca en el contenido de un proyecto de software a medida que avanza su desarrollo. Git, diseñado también por Linus Torvalds, se emplea hoy en la línea principal de desarrollo del núcleo de Linux. Git es un sistema increíblemente útil, que debemos entender bien por dos motivos principales: podemos utilizar Git en el desarrollo de nuestro propio software y además nos permite aprender a trabajar con distribuciones de código fuente del núcleo de Linux.
Git es un sistema distribuido de control de versiones, o DVCS (Distributed Version Contol System) que facilita el control del código fuente de un proyecto. Un sistema de control de versiones, VCS, registra y gestiona cualquier cambio introducido en documentos de cualquier tipo. Normalmente, los documentos que cambiemos se destacarán con números de revisión y marcas de tiempo. Se pueden comparar revisiones y hasta regresar a versiones antiguas de los documentos. Hay dos tipos de sistemas VCS:
❏Centralizados (CVCS): estos sistemas, como Apache Subversion (SVN), funcionan con la premisa de que existe una copia "maestra" única del proyecto. El flujo de trabajo es simple y directo: bajamos los cambios desde un servidor central, introducimos los nuestros propios y los volvemos a subir como definitivos a la copia maestra (esta subida definitiva de los cambios se denomina "commit", término típico también de las bases de datos; en español su uso como sustantivo ("hacer commit") es abrumadoramente mayoritario en el entorno informático, y es el que usaremos aquí).
❏Distribuidos (DVCS): usando estos sistemas, por ejemplo Git y Selenic Mercurial, no bajamos cambios, sino que clonamos el repositorio completo, incluido todo el histórico de cambios. El clonado del repositorio produce una copia tan exacta como una copia maestra, que hasta puede llegar a actuar como tal si fuera preciso. Por fortuna, los estándares actuales hacen que los documentos de texto plano y los archivos de código fuente no ocupen mucho espacio en disco. Una precisión importante: el modelo DVCS no excluye el uso de un repositorio maestro central para todos los usuarios. Véase, por ejemplo, git.kernel.org.
La ventaja principal de un DVCS frente a un CVCS es la posibilidad de hacer
commit rápidamente y probar las modificaciones localmente, en nuestro propio sistema, sin tener que subirlas antes a ninguna copia maestra. Esto permite la flexibilidad de poder subir los cambios solo cuando alcancen un nivel apropiado de calidad. La única desventaja significativa es el espacio en disco que exige el almacenamiento de todo el proyecto con su histórico de cambios, que va creciendo con el paso del tiempo.
Git es un DVCS centrado en el control y gestión de código fuente. Nos permite crear desarrollos paralelos que no afecten al original. Podemos regresar a una versión anterior de alguno de los archivos de código fuente, o bien a una de todo el proyecto. El proyecto, con sus archivos asociados e histórico de cambios, se denomina "repositorio" (repository). Esta capacidad resulta particularmente útil en proyectos de programación a gran escala, en los que es posible optar por una dirección para el desarrollo que, finalmente, acabe por resultar infructuosa. También es importante la facilidad para el desarrollo en paralelo cuando se tiene a varias personas trabajando en el mismo proyecto.
Git está escrito en C y, aunque se creó para cubrir la necesidad de control de versiones en el desarrollo del núcleo de Linux, se utiliza ampliamente en otros proyectos de código abierto como Eclipse o Android.
La manera más fácil de entender el manejo de Git es usarlo. Por tanto, hemos estructurado la sección siguiente en forma de guía paso a paso. Si todavía no lo tiene, Git se instala con facilidad mediante el comando sudo apt install git, así que no debería tener problemas para seguir los pasos directamente en el terminal. Este libro emplea GitHub como repositorio remoto de los ejemplos de código fuente. Salvo realizar commit de código fuente en el servidor, el lector podrá hacer todo lo expuesto en esta guía sin crear una cuenta en GitHub. No obstante, GitHub permite crear cuentas de repositorio públicas de forma gratuita, pero si queremos un repositorio privado, por ejemplo para desarrollos que deban salvaguardar derechos de propiedad intelectual, tendremos que pagar una cuota.
NOTA Si el lector planea embarcarse en el desarrollo de un proyecto grande y prefiere que no esté públicamente disponible en www.github.comni pagar cuota de suscripción alguna, es posible hospedar repositorios privados de pequeña escala en sitios como bitbucket.orgy gitlab.com. Con un poco más de trabajo, hasta es posible configurar GitLab en nuestro propio servidor, ya que existe una versión de código abierto de la plataforma.
Una introducción práctica
Para esta guía, hemos creado un repositorio llamado "test" en GitHub. En principio solo contiene un archivo, README.md, con una descripción breve del proyecto "test".
Como podemos ver en la figura 3-4, casi todas las operaciones son locales. Git realiza una suma de verificación en cada archivo antes de almacenarlo. Suma que garantiza que Git detecte cualquier modificación realizada fuera del propio repositorio Git, incluidas las que pudieran derivarse de la corrupción del sistema. Git emplea códigos hash de 40 caracteres para las sumas de verificación. De este modo, es capaz de registrar los cambios entre repositorios locales y remotos, lo que, a su vez, hace posible toda la funcionalidad de operaciones locales.
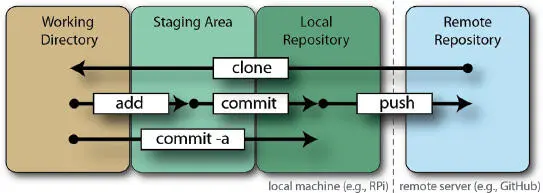
Figura 3-4: El flujo de trabajo básico de Git.
Cómo clonar un repositorio (git clone)
Clonar un repositorio supone realizar una copia de todos los archivos que contenga el proyecto, junto con el histórico de cambios completo, y guardarla en nuestro disco duro. Haremos esta operación una sola vez. Para clonar el repositorio envíe el comando git clone seguido del nombre completo del repositorio:
pi@erpi / $ cd ~/
pi@erpi ~ $ git clone https://github.com/derekmolloy/test.git
Cloning into 'test'...
remote: Counting objects: 14, done.
remote: Compressing objects: 100% (5/5), done.
remote: Total 14 (delta 1), reused 0 (delta 0), pack-reused 9
Unpacking objects: 100% (14/14), done.
Checking connectivity... done.
Ahora tenemos una copia completa del repositorio "test" en el directorio /test. Nuestro repositorio es igual de completo que la versión en el servidor de GitHub. Si fuera necesario, este repositorio podría quedar disponible a través de una red, en un sistema de archivos o en otra cuenta de GitHub y serviría perfectamente como versión principal del repositorio. Aunque no sea necesario contar con un servidor central, generalmente lo hay, ya que de este modo múltiples usuarios pueden insertar (check in) código fuente en un repositorio maestro conocido. El repositorio se crea en el directorio /test y en este momento contiene lo siguiente:
pi@erpi ~/test $ ls -al
total 20
drwxr-xr-x 3 pi pi 4096 Jun 20 22:00 .
drwxr-xr-x 6 pi pi 4096 Jun 20 22:00 ..
drwxr-xr-x 8 pi pi 4096 Jun 20 22:00 .git
-rw-r--r-- 1 pi pi 59 Jun 20 22:00 README.md
Podemos ver el archivo README.md que se creó cuando el proyecto se inicializó en GitHub. Podemos usar more para ver el contenido del mismo. El directorio contiene un subdirectorio .git oculto, con los siguientes archivos y directorios:
pi@erpi ~/test/.git $ ls
branches description hooks info objects refs
Читать дальшеИнтервал:
Закладка:
Похожие книги на «Raspberry Pi® a fondo para desarrolladores»
Представляем Вашему вниманию похожие книги на «Raspberry Pi® a fondo para desarrolladores» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.












Обсуждение, отзывы о книге «Raspberry Pi® a fondo para desarrolladores» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.