Stephen Winters-Hilt - Informatics and Machine Learning
Здесь есть возможность читать онлайн «Stephen Winters-Hilt - Informatics and Machine Learning» — ознакомительный отрывок электронной книги совершенно бесплатно, а после прочтения отрывка купить полную версию. В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Жанр: unrecognised, на английском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.

- Название:Informatics and Machine Learning
- Автор:
- Жанр:
- Год:неизвестен
- ISBN:нет данных
- Рейтинг книги:3 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
Informatics and Machine Learning: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «Informatics and Machine Learning»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
Discover a thorough exploration of how to use computational, algorithmic, statistical, and informatics methods to analyze digital data Informatics and Machine Learning: From Martingales to Metaheuristics
ad hoc, ab initio
Informatics and Machine Learning: From Martingales to Metaheuristics
Informatics and Machine Learning — читать онлайн ознакомительный отрывок
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «Informatics and Machine Learning», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
If you have as prior information the existence of the mean and variance of some quantity (the first and second statistical moments), then you have the Lagrangian:
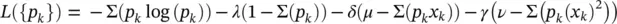
where, ∂L / ∂p k= 0→ the Gaussian distribution (see Exercise 3.3).
With the introduction of Shannon entropy above, c. 1948, a reformulation of statistical mechanics was indicated (Jaynes [112] ) whereby entropy could be made the starting point for the entire theory by way of maximum entropy with whatever system constraints – immediately giving rise to the classic distributions seen in nature for various systems (itself an alternate derivation starting point for statistical mechanics already noted by Maxwell over 100 years ago). So instead of introducing other statistical mechanics concepts (ergodicity, equal a priori probabilities, etc.) and matching the resulting derivations to phenomenological thermodynamics equations to get entropy, with the Jaynes derivation we start with entropy and maximize it directly to obtain the rest of the theory.
3.1.3 Relative Entropy and Its Uniqueness
Relative entropy ( ρ = ∑ x p(x) log(p(x)/q(x)) = D(P||Q)) uniquely results from a geometric (differentiable manifold) formalism on families of distributions – the Information Geometry formalism was first described by Amari [113–115]. Together with Laplace’s principle of insufficient reason on the choice of “reference” distribution in the relative entropy expression, this will reduce to Shannon entropy, and thus uniqueness on Shannon entropy from a geometric context. The parallel with geometry is the Euclidean distance for “flat” geometry (simplest assumption of structure), vs. the “distance” between distributions as described by the Kullback–Leibler divergence.
When comparing discrete probability distributions P and Q , both referring to the same N outcomes, the measure of their difference is sometimes measured in terms of their symmetrized relative entropy [105] (a.k.a. Kullback–Leibler divergence), D ( P , Q ):
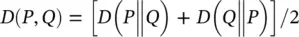
where,
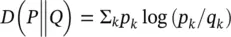
where, P and Q have outcome probabilities { p k} and { q k}.
Relative entropy has some oddities that should be explained right away. First, it does not have the negative sign in front to make it a positive number (recall this was done for the Shannon entropy definition since all of the log factors are always negative). Relative entropy does not need the negative sign, however, since it is provably always positive as is! (The proof uses Jensen’s Inequality from Section 2.6.1, see Exercise 3.12.) For relative entropy there is also the constraint to the convention mentioned above where all the outcome probabilities are nonzero (otherwise have a divide by zero or a log(0) evaluation, either of which is undefined). Relative entropy is also asymmetric in that D ( P ‖ Q ) is not equal to D ( Q ‖ P ).
3.1.4 Mutual Information
One of the most powerful uses of Relative entropy is in the context of evaluating the statistical linkage between two sets of outcomes, e.g. in determining if two random variables are independent are not. In probability we can talk about the probability of two events happening, such as the probabilities for the outcomes of rolling two dice P ( X , Y ), where X is the first die, with outcomes x 1= 1, …, x 6= 6, and similarly for the second die Y . If they are both fair dice, they act independently of each other, then their joint probability reduces to: P ( X , Y ) = P ( X ) P ( Y ), if { X , Y } are independent of each other.
If using loaded dice, but with dice that have no interaction, then they are still independent of eachother, and their probabilities are thus still independent, reducing to the product of two simpler probability distributions (with one argument each) as shown above. In games of dice where two dice are rolled (craps) it is possible to have dice that individually roll as fair, having uniform distribution on outcomes, but that when rolled together interact such that their combined rolls are biased. This can be accomplished with use of small bar magnets oriented from the “1” to “6” faces, such that the dice tend to come up with their magnets anti‐aligned one showing its “1” face, the other showing its “6” face, for a total roll count of “7” (where the roll of a “7” has special significance in the game of craps). In the instance of the dice with magnets, the outcomes of the individual die rolls are not independent, and the simplification of P ( X , Y ) to P ( X ) P ( Y ) cannot be made.
In evaluating if there is a statistical linkage between two events we are essentially asking if the probability of those events are independent, e.g. does P ( X , Y ) = P ( X ) P ( Y )? In this situation we are again in the position of comparing two probability distributions, P ( X , Y ) and P ( X ) P ( Y ), so if relative entropy is best for such comparisons, then why not evaluate D ( P ( X , Y ) ‖ P ( X ) P ( Y ))? This is precisely what should be done and in doing so we have arrived at the definition of what is known as “mutual information” (finally a name for an information measure that is perfectly self‐explanatory!).
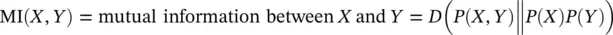
The use of mutual information is very powerful in bioinformatics, and informatics in general, as it allows statistical linkages to be discovered that are not otherwise apparent. In Section 3.2we will start with evaluating the mutual information between genomic nucleotides at various degrees of separation. If we see nonzero mutual information in the genome for bases separated by certain, specified, gap distances, we will have uncovered that there is “structure” of some sort.
3.1.5 Information Measures Recap
The fundamental information measures are, thus, Shannon entropy, mutual information, and relative entropy (also known as the Kullback–Leibler divergence, especially when in symmetrized form). Shannon entropy, σ = –∑ x p(x)log(p(x)), is a measure of the information in distribution p(x). Relative entropy (Kullback–Leibler divergence): ρ = ∑ x p(x) log(p(x)/q(x)), is a measure of distance between two probability distributions. MI( X , Y ), μ = ∑ x ∑ y p(xy) log(p(xy)/p(x)p(y)), is a measure of information one random variable has about another random variable. As shown above, Mutual Information is a special case of relative entropy. Let us now write code to implement these measures, and then apply them to analysis of genomic data.
Читать дальшеИнтервал:
Закладка:
Похожие книги на «Informatics and Machine Learning»
Представляем Вашему вниманию похожие книги на «Informatics and Machine Learning» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.












Обсуждение, отзывы о книге «Informatics and Machine Learning» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.