Handbook of Intelligent Computing and Optimization for Sustainable Development
Здесь есть возможность читать онлайн «Handbook of Intelligent Computing and Optimization for Sustainable Development» — ознакомительный отрывок электронной книги совершенно бесплатно, а после прочтения отрывка купить полную версию. В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Жанр: unrecognised, на английском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.

- Название:Handbook of Intelligent Computing and Optimization for Sustainable Development
- Автор:
- Жанр:
- Год:неизвестен
- ISBN:нет данных
- Рейтинг книги:5 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
Handbook of Intelligent Computing and Optimization for Sustainable Development: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «Handbook of Intelligent Computing and Optimization for Sustainable Development»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
This book provides a comprehensive overview of the latest breakthroughs and recent progress in sustainable intelligent computing technologies, applications, and optimization techniques across various industries.
Audience Handbook of Intelligent Computing and Optimization for Sustainable Development
Handbook of Intelligent Computing and Optimization for Sustainable Development — читать онлайн ознакомительный отрывок
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «Handbook of Intelligent Computing and Optimization for Sustainable Development», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
(2.8) 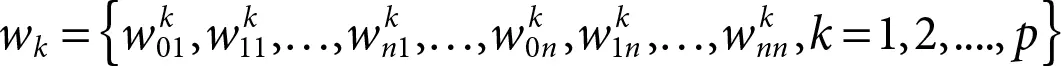
After determining the values for all of the wk , the value of w can be calculated by taking the intersection of wk .
• Category process: If an unknown vector is given as the input, then the model of perceptron categorizes it using the weight set w which has been computed from training process.
2.4.2.1 Algorithm
The researchers further designed the algorithm of linear perceptron categorizer in the context of DNA computation. The steps of the algorithm are given below.
• The input vector, X(k) = (x1, x2, …, xn), is represented by n DNA strands which are extracted from sample molecular library.If the input value of ith neuron = 0 (where i = 1, 2, …, n), then the coding mode is denoted byIf the input value of ith neuron = 1, then the coding mode is denoted byThe value of additional bias signal is always 1. Thus, the coding mode of bias signal isIn the molecular library, there are 2n + 1 types of DNA strands each of which are five bases long.Again, the output values are also represented by five bases long DNA strands. If the output value of jth neuron = 0 (where j = 1, 2, …, m), then the coding mode is denoted byIf the input value of jth neuron = 1, then the coding mode is denoted by
• These strands are hybridized with the DNA library representing weight coefficient.
• DNA strands are made representing the set of weights denoted by w1, w2, …, wp.
• The DNA strands representing the weight coefficient wij have four domains. The coding modes are presented by the following expression:(2.9)wherethe first domain takes in input value of ith input neuron;the second domain wij which is fifteen bases long represents weight coefficient;the third domain vij represents the arithmetic of input value and wij; the length of this domain is proportional to its true value, but not less than five bases;the fourth domain represents the weight coefficient wi=1,j which joins (i+1)th input neuron and jth output neuron.There are four special weights are represented by the expressions illustrated below:(2.10)(2.11)(2.12)(2.13)
• Intersection can be calculated by performing gel electrophoresis using the DNA strands w1, w2,…, wp and w is derived.
• Classification of unknown input vector can be derived from DNA strands representing the weight set w.
2.4.2.2 Implementation of the Algorithm
• Sample Input: Each DNA solution representing (X(k), Y(k)) (here, the kth sample is taken) is mixed with the solution representing the corresponding kth weight molecular library tube, denoted by tk, so that the hybridization with the weight coefficient can occur. Prolongation reaction is performed with the solution of tube tk by using initial input sample as the primer sequence. Then, the solution is treated with excision enzyme to remove the single strands. The new tube is generated with the resultant strands.
• Generation of DNA strands representing weight set: Again, is treated with restriction enzyme and gel electrophoresis is performed to remove shorter DNA strands. The filtered solution containing the longer strands is treated with ligase to perform coupled reaction. This reaction generates DNA strands representing the weight sum.(2.14)(2.15)
• Gel Electrophoresis: Using the strand as probe, the output strands denoting “0” is extracted into the tube . Again, using the strand as probe, the output strands denoting “1” is extracted into the tube , and extract the DNA strands which output value is “1” into the tube . Gel electrophoresis is done with both of the tubes.
For the tube 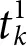 , DNA strands with length less than a specific threshold ∮ are retained and for the tube
, DNA strands with length less than a specific threshold ∮ are retained and for the tube 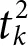 , the DNA strands with length greater than ∮ are retained. From this step, a series DNA strands presenting w1 , w2 , .…, wp are generated.
, the DNA strands with length greater than ∮ are retained. From this step, a series DNA strands presenting w1 , w2 , .…, wp are generated.
• Performing Intersection to generate w: If p is even number, then the set w1, w2, .…, wp is divided into p/2 groups, intersection of each group is solved. If p is odd, then the set divided into (p/2 + 1) groups, and again the interaction for each group is solved. The remainder tube with no match tube directly takes part in the next cyclic grouping, till the last cycle there is one tube remain. If any DNA strand exists, then the intersection of w1, w2, .…, wp can be deduced.
• The sequence of the strand can be read by performing sequencing.
• Classification of the unknown input vector: Using the probe 5′ − wij − 3′ the DNA strands are extracted from the weight. The extracted strands are put into a new tube and it is mixed with the solution representing the unknown input vector. The first, second, and third steps are again performed using the solution. Using the strand as probe, the output strands denoting “0” is extracted. Again, using the strand as probe, the output strands denoting “1” is extracted.
Following these steps, the unknown input vector can be classified.
So far, we have developed neural model using short DNA sequences and replaced the mathematical aspect of ANN by the elementary operations of the DNA chemistry. In next section, we illustrate the DNA logic gates which are the basic of Boolean algebra. It is essential for the hands-on development of DNA computer.
2.5 DNA Logic Gates
The activity of the brain resembles the computer as it functions as an input-output device. The basic design of digital computer follows Boolean algebra. McCulloch and Pitts [1] presented their view on the possibility of the brain to use Boolean algebra. As the input and output of the neural model are binary numbers, thus the researcher do proposed that multilayer neural network can implement the basic logic gates, i.e., AND, OR, and NOT. This can be achieved by appropriately choosing the weights. Complex Boolean circuits can be constructed by designing properly connected architecture by neurons.
• AND Gate: The truth table for AND gate is represented by Table 2.1. Table 2.1 Truth table for AND gate.Input (ix)Input (iy)Output (y)000100010111The function for implementation of AND gate is represented by Equation (2.16). (2.16)where b ≡ bias value and 1 < b < 2;g(.) ≡ step function;ix, iy ≡ input values and ix, iy ∈ {0, 1};y ≡ output value and y ∈ {0, 1}.
• OR Gate: The truth table for OR gate is represented by Table 2.2. Table 2.2 Truth table for OR gate.Input (ix)Input (iy)Output (y)000011101111The function for implementation of OR gate is represented by Equation (2.17). (2.17)where b ≡ bias value and 0 < b < 1;g(.) ≡ step function;ix, iy ≡ input values and ix, iy ∈ {0, 1};y ≡ output value and y ∈ {0, 1}.
• NOT Gate: The truth table for NOT gate is represented by Table 2.3. Table 2.3 Truth table for NOT gate.Input (ix)Output (y)0110The function for implementation of NOT gate is represented by Equation (2.18). (2.18)where b ≡ bias value and 0 < b < 1;g(.) ≡ step function;ix ≡ input value and ix ∈ {0, 1};y ≡ output value and y ∈ {0, 1}.
In this section, we focus on the design strategy of logic gates which has been developed using the secondary structures of DNA molecules. These DNA logic gates are the pillars of logic circuits which are needed to design a competent DNA computer in near future.
Читать дальшеИнтервал:
Закладка:
Похожие книги на «Handbook of Intelligent Computing and Optimization for Sustainable Development»
Представляем Вашему вниманию похожие книги на «Handbook of Intelligent Computing and Optimization for Sustainable Development» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.












Обсуждение, отзывы о книге «Handbook of Intelligent Computing and Optimization for Sustainable Development» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.