Computational Statistics in Data Science
Здесь есть возможность читать онлайн «Computational Statistics in Data Science» — ознакомительный отрывок электронной книги совершенно бесплатно, а после прочтения отрывка купить полную версию. В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Жанр: unrecognised, на английском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.

- Название:Computational Statistics in Data Science
- Автор:
- Жанр:
- Год:неизвестен
- ISBN:нет данных
- Рейтинг книги:4 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
Computational Statistics in Data Science: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «Computational Statistics in Data Science»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
Computational Statistics in Data Science
Computational Statistics in Data Science
Wiley StatsRef: Statistics Reference Online
Computational Statistics in Data Science
Computational Statistics in Data Science — читать онлайн ознакомительный отрывок
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «Computational Statistics in Data Science», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
The presentation begins with a thoughtful introduction on how we should view Computational Statistics & Data Science in the 21st Century(Holbrook, et al.), followed by a careful tour of contemporary Statistical Software(Schissler, et al.). Topics that follow address a variety of issues, collected into broad topic areas such as Simulation‐based Methods, Statistical Learning, Quantitative Visualization, High‐performance Computing, High‐dimensional Data Analysis, and Numerical Approximations & Optimization.
Internet access to all of the articles presented here is available via the online collection Wiley StatsRef: Statistics Reference Online (Davidian, et al., 2014–2021); see https://onlinelibrary.wiley.com/doi/book/10.1002/9781118445112.
From Deep Learning(Li, et al.) to Asynchronous Parallel Computing(Yan), this collection provides a glimpse into how computational statistics may progress in this age of big data and transdisciplinary data science. It is our fervent hope that readers will benefit from it.
We wish to thank the fine efforts of the Wiley editorial staff, including Kimberly Monroe‐Hill, Paul Sayer, Michael New, Vignesh Lakshmikanthan, Aruna Pragasam, Viktoria Hartl‐Vida, Alison Oliver, and Layla Harden in helping bring this project to fruition.
| Tucson, ArizonaSan Diego, California Tucson, ArizonaDavis, California | Walter W. Piegorsch Richard A. Levine Hao Helen Zhang Thomas C. M. Lee |
Reference
1 Davidian, M., Kenett, R.S., Longford, N.T., Molenberghs, G., Piegorsch, W.W., and Ruggeri, F., eds. (2014–2021). Wiley StatsRef: Statistics Reference Online. Chichester: John Wiley & Sons. doi:10.1002/9781118445112.
1 Computational Statistics and Data Science in the Twenty‐First Century
Andrew J. Holbrook1, Akihiko Nishimura2, Xiang Ji3, and Marc A. Suchard1
1University of California, Los Angeles, CA, USA
2Johns Hopkins University, Baltimore, MD, USA
3Tulane University, New Orleans, LA, USA
1 Introduction
We are in the midst of the data science revolution. In October 2012, the Harvard Business Review famously declared data scientist the sexiest job of the twenty‐first century [1]. By September 2019, Google searches for the term “data science” had multiplied over sevenfold [2], one multiplicative increase for each intervening year. In the United States between the years 2000 and 2018, the number of bachelor's degrees awarded in either statistics or biostatistics increased over 10‐fold (382–3964), and the number of doctoral degrees almost tripled (249–688) [3]. In 2020, seemingly every major university has established or is establishing its own data science institute, center, or initiative.
Data science [4, 5] combines multiple preexisting disciplines (e.g., statistics, machine learning, and computer science) with a redirected focus on creating, understanding, and systematizing workflows that turn real‐world data into actionable conclusions. The ubiquity of data in all economic sectors and scientific disciplines makes data science eminently relevant to cohorts of researchers for whom the discipline of statistics was previously closed off and esoteric. Data science's emphasis on practical application only enhances the importance of computational statistics , the interface between statistics and computer science primarily concerned with the development of algorithms producing either statistical inference 1 or predictions. Since both of these products comprise essential tasks in any data scientific workflow, we believe that the pan‐disciplinary nature of data science only increases the number of opportunities for computational statistics to evolve by taking on new applications 2 and serving the needs of new groups of researchers.
This is the natural role for a discipline that has increased the breadth of statistical application from the beginning. First put forward by R.A. Fisher in 1936 [6, 7], the permutation test allows the scientist (who owns a computer) to test hypotheses about a broader swath of functionals of a target population while making fewer statistical assumptions [8]. With a computer, the scientist uses the bootstrap [9, 10] to obtain confidence intervals for population functionals and parameters of models too complex for analytic methods. Newton–Raphson optimization and the Fisher scoring algorithm facilitate linear regression for binary, count, and categorical outcomes . More recently, Markov chain Monte Carlo (MCMC) has made Bayesian inference practical for massive, hierarchical, and highly structured models that are useful for the analysis of a significantly wider range of scientific phenomena.
While computational statistics increases the diversity of statistical applications historically, certain central difficulties exist and will continue to remain for the rest of the twenty‐first century. In Section 2, we present the first class of Core Challenges, or challenges that are easily quantifiable for generic tasks. Core Challenge 1 is Big 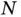 , or statistical inference when the number “ N ” of observations or data points is large; Core Challenge 2 is Big
, or statistical inference when the number “ N ” of observations or data points is large; Core Challenge 2 is Big 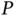 , or statistical inference when the model parameter count “ P ” is large; and Core Challenge 3 is Big
, or statistical inference when the model parameter count “ P ” is large; and Core Challenge 3 is Big 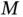 , or statistical inference when the model's objective or density function is multimodal (having many modes “
, or statistical inference when the model's objective or density function is multimodal (having many modes “ 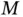 ”) 3 . When large, each of these quantities brings its own unique computational difficulty. Since well over 2.5 exabytes (or
”) 3 . When large, each of these quantities brings its own unique computational difficulty. Since well over 2.5 exabytes (or 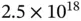 bytes) of data come into existence each day [15], we are confident that Core Challenge 1 will survive well into the twenty‐second century.
bytes) of data come into existence each day [15], we are confident that Core Challenge 1 will survive well into the twenty‐second century.
But Core Challenges 2 and 3 will also endure: data complexity often increases with size, and researchers strive to understand increasingly complex phenomena. Because many examples of big data become “big” by combining heterogeneous sources, big data often necessitate big models. With the help of two recent examples, Section 3illustrates how computational statisticians make headway at the intersection of big data and big models with model‐specific advances. In Section 3.1, we present recent work in Bayesian inference for big N and big P regression. Beyond the simplified regression setting, data often come with structures (e.g., spatial, temporal, and network), and correct inference must take these structures into account. For this reason, we present novel computational methods for a highly structured and hierarchical model for the analysis of multistructured and epidemiological data in Section 3.2.
The growth of model complexity leads to new inferential challenges. While we define Core Challenges 1–3 in terms of generic target distributions or objective functions, Core Challenge 4 arises from inherent difficulties in treating complex models generically. Core Challenge 4 ( Section 4.1) describes the difficulties and trade‐offs that must be overcome to create fast, flexible, and friendly “algo‐ware”. This Core Challenge requires the development of statistical algorithms that maintain efficiency despite model structure and, thus, apply to a wider swath of target distributions or objective functions “out of the box”. Such generic algorithms typically require little cleverness or creativity to implement, limiting the amount of time data scientists must spend worrying about computational details. Moreover, they aid the development of flexible statistical software that adapts to complex model structure in a way that users easily understand. But it is not enough that software be flexible and easy to use: mapping computations to computer hardware for optimal implementations remains difficult. In Section 4.2, we argue that Core Challenge 5, effective use of computational resources such as central processing units (CPU), graphics processing units (GPU), and quantum computers, will become increasingly central to the work of the computational statistician as data grow in magnitude.
Читать дальшеИнтервал:
Закладка:
Похожие книги на «Computational Statistics in Data Science»
Представляем Вашему вниманию похожие книги на «Computational Statistics in Data Science» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.
![Роман Зыков - Роман с Data Science. Как монетизировать большие данные [litres]](/books/438007/roman-zykov-roman-s-data-science-kak-monetizirova-thumb.webp)











Обсуждение, отзывы о книге «Computational Statistics in Data Science» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.