Виктор Звонников - Контроль качества обучения при аттестации - компетентностный подход
Здесь есть возможность читать онлайн «Виктор Звонников - Контроль качества обучения при аттестации - компетентностный подход» весь текст электронной книги совершенно бесплатно (целиком полную версию без сокращений). В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Город: Москва, Год выпуска: 2009, ISBN: 2009, Издательство: Array Литагент «Логос», Жанр: Прочая научная литература, на русском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.

- Название:Контроль качества обучения при аттестации: компетентностный подход
- Автор:
- Издательство:Array Литагент «Логос»
- Жанр:
- Год:2009
- Город:Москва
- ISBN:978-5-98704-369-7
- Рейтинг книги:3 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
Контроль качества обучения при аттестации: компетентностный подход: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «Контроль качества обучения при аттестации: компетентностный подход»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
Для студентов высших учебных заведений, обучающихся по специальности «Менеджмент организации». Может использоваться при подготовке кадров по широкому кругу педагогических специальностей, а также при повышении квалификации и переподготовке кадров образования. Представляет интерес для исследователей и специалистов в области тестирования.
Контроль качества обучения при аттестации: компетентностный подход — читать онлайн бесплатно полную книгу (весь текст) целиком
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «Контроль качества обучения при аттестации: компетентностный подход», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
Вообще существует бесконечное множество нормальных кривых, отличающихся друг от друга значениями X̅ и S x , но все они объединяются общими свойствами, которые связаны с долями площади под кривой в пределах определенного числа отклонений. Из всех нормальных кривых наиболее удобна единичная, площадь под которой равна единице. Для нее среднее значение равно нулю, а стандартное отклонение единице.
Для преобразования любой нормальной кривой в единичную достаточно выполнить вычитание среднего значения X̅ из каждого индивидуального балла X i и разделить полученную разность на стандартное отклонение S x , т.е., применив формулу
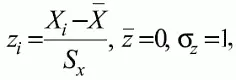
получим нормированное нормальное распределение со средним в нуле и единичным стандартным отклонением.
При разработке теста необходимо помнить о том, что кривая распределения индивидуальных баллов, получаемых на репрезентативной выборке, носит неслучайный характер. Она является следствием подбора трудности заданий теста. При смещении в сторону легких заданий большая часть студентов выполнит почти все задания теста и получит высокие индивидуальные баллы. При приоритетном подборе самых трудных заданий в распределении индивидуальных баллов получится всплеск вблизи начала горизонтальной оси. При оптимальной трудности теста, когда распределение оценок параметра трудности заданий имеет вид нормальной кривой, автоматически возникает нормальность распределения индивидуальных баллов репрезентативной выборки студентов, что в свою очередь позволяет считать полученное распределение устойчивым по отношению к генеральной совокупности и определить репрезентативные нормы выполнения теста.
Углубленный анализ качества теста, позволяющий сделать выводы о направлениях коррекции содержания отдельных заданий, связан с вычислением показателей связи между результатами испытуемых по отдельным заданиям теста. При оценке качества заданий важно понять, существует ли тенденция, когда одни и те же студенты добиваются успеха в какой-либо паре заданий теста либо состав учеников, добивающихся успеха, полностью меняется при переходе от одного задания теста к другому. Ответ на вопрос о существовании связи между двумя наборами данных получают с помощью корреляции.
Для выражения степени соответствия между наборами данных X и Y используется специальная мера, которая называется ковариацией. Смысл понятия «ковариация» удобно пояснить на примере результатов выполнения одной группой испытуемых двух тестов X и Y Пусть результаты по первому тесту X – это множество х i ( i = l, 2, …, Ν ) , а по второму тесту – Y i ( i = 1, 2, …, Ν ). Тогда для установления меры связи между результатами студентов по двум тестам необходимо сравнить положение каждого тестируемого по отношению к средним в распределении результатов по тесту X и по тесту Y. Степень соответствия результатов i -го испытуемого в первом ( X ) и во втором ( Y ) тестированиях будет проявляться в величине и знаке произведения отклонений ( X i – X̅ )( Y i – Y̅ ) , где X i , Y i – результаты i -го испытуемого в первом и во втором тестированиях соответственно ( i = 1, 2, … , N ); X̅, Y̅ — средние значения результатов по тестам X и Y, N — число студентов тестируемой группы.
Если результат i -го испытуемого намного выше или ниже среднего балла по обоим тестам, то произведение ( X i – X̅ )( Y i – Y̅ ) будет большим и положительным. Таким образом, при прямой связи значений X i и Y i ( i = 1, 2, …, N ) по тестам X и Y большой и положительной получится сумма всех произведений, т.е.
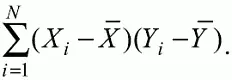
При обратной связи результатов тестирования, когда большинство значений X i выше (ниже) среднего X̅ по тесту X сменяются на значения Y i ниже (выше) среднего Y̅ по тесту Y, сумма
будет меньше нуля и велика по модулю в силу отрицательного знака всех или почти всех произведений ( X i – X̅ )( Y i – Y̅ ) . Наконец, если систематической связи между результатами студентов по тестам X и Y не наблюдается, знак произведения ( X i – X̅ )( Y i – Y̅ ) будет хаотически меняться. Вполне возможно, что для достаточно большой выборки испытуемых, положительные слагаемые будут уравновешиваться отрицательными и потому сумма произведений
Читать дальшеИнтервал:
Закладка:
Похожие книги на «Контроль качества обучения при аттестации: компетентностный подход»
Представляем Вашему вниманию похожие книги на «Контроль качества обучения при аттестации: компетентностный подход» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.











Обсуждение, отзывы о книге «Контроль качества обучения при аттестации: компетентностный подход» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.