Леонард Млодинов - (Не)совершенная случайность. Как случай управляет нашей жизнью
Здесь есть возможность читать онлайн «Леонард Млодинов - (Не)совершенная случайность. Как случай управляет нашей жизнью» — ознакомительный отрывок электронной книги совершенно бесплатно, а после прочтения отрывка купить полную версию. В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Город: Москва, Год выпуска: 2010, ISBN: 2010, Издательство: Livebook/Гаятри, Жанр: Математика, Прочая научная литература, на русском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.

- Название:(Не)совершенная случайность. Как случай управляет нашей жизнью
- Автор:
- Издательство:Livebook/Гаятри
- Жанр:
- Год:2010
- Город:Москва
- ISBN:978-5-9689-0171-2
- Рейтинг книги:4 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
(Не)совершенная случайность. Как случай управляет нашей жизнью: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «(Не)совершенная случайность. Как случай управляет нашей жизнью»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
Эта книга — отличный способ тряхнуть стариной и освежить в памяти кое-что из курса высшей математики, истории естественнонаучного знания, астрономии и статистики для тех, кто изучал эти дивные дисциплины в вузах; понятно и доступно изложенные основы теории вероятностей и ее применимости в житейских обстоятельствах (с многочисленными примерами) для тех, кому не посчастливилось изучать их специально; наконец, профессиональный и дружелюбный подсказчик грызущим гранит соответствующих наук в данный момент.
(Не)совершенная случайность. Как случай управляет нашей жизнью — читать онлайн ознакомительный отрывок
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «(Не)совершенная случайность. Как случай управляет нашей жизнью», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
При описании распределения данных колоколообразная кривая демонстрирует, что в том случае, когда вы делаете много замеров, большинство их результатов будут примыкать к среднему значению, что отображается в виде пика. Симметрично снижаясь по обе стороны от пика, кривая показывает, как убывает число результатов замеров ниже и выше среднего, поначалу довольно резко, а потом не столь круто. Если данные распределены нормально, около 68% (т. е. приблизительно 2/ 3) результатов измерений попадают в пределы одного стандартного отклонения, около 95% — в пределы двух стандартных отклонений и 99,7% — в пределы трех стандартных отклонений.
Чтобы представить себе эту картину, взгляните на графики ниже. Квадратики соответствуют результатам угадывания 300 студентами исходов десятикратного подбрасывания монеты {144} 144 The graph is from Index Funds Advisors, «Index Funds.com: Take the Risk Capacity Survey», http://www.indexfunds3.com/step3page2.php , where it is credited to Walter Good and Roy Hermansen, Index Your Way to Investment Success (New York: New York Institute of Finance, 1997). The performance of 300 mutual fund managers was tabulated for ten years (1987–1996), based on the Morningstar Principia database
. По оси абсцисс отложено количество верных угадываний — от 0 до 10. По оси ординат — количество студентов, продемонстрировавших соответствующее количество верных угадываний. Кривая имеет колоколообразную форму с пиком на уровне 5 верных угадываний: столько раз верно угадали исход подбрасывания 75 студентов. Двух третей максимальной высоты (соответствующее количество студентов — 51) кривая достигает посередине между 3 и 4 верными угадываниями слева и между 6 и 7 верными угадываниями справа. Колоколообразная кривая с таким стандартным отклонением типична для стохастических процессов вроде угадывания исходов подбрасывания монеты.
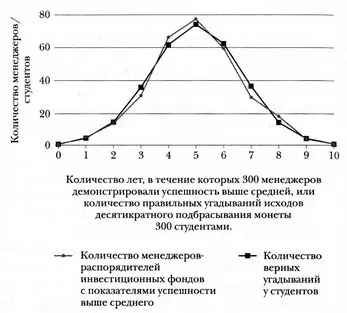
Угадывание исходов подбрасывания монет и подбор акций: сопоставительный анализ.
Кружочками на том же графике отображен еще один набор данных — успешность работы 300 менеджеров паевых инвестиционных фондов. Для этого набора данных по оси абсцисс отложено не количество верных угадываний исходов подбрасывания монеты, а количество лет (из 10), когда показатели успешности работы менеджера были выше группового среднего. Обратите внимание на сходство! Мы еще вернемся к нему в главе 9.
Чтобы понять связь между нормальным распределением и случайной ошибкой, можно рассмотреть процесс проведения выборочного опроса. Вспомним опрос относительно популярности мэра Базеля, который я упоминал в главе 5. В этом городе часть жителей одобряет деятельность мэра, а часть осуждает. Для простоты примем, что тех и других по 50%. Но, как мы видели, результаты опроса не обязательно будут полностью соответствовать этой пропорции 50/50. И в самом деле, если выборочно опросить N горожан, то вероятность, что любое произвольное их число поддержит мэра, пропорциональна числам в строке N треугольника Паскаля. А раз так, то, согласно работам де Муавра, если служба общественного мнения опросит большое число горожан, вероятность всех возможных результатов опроса можно будет описать с помощью кривой нормального распределения. Иными словами, около 95% случаев одобрения попадет в пределы 2 стандартных отклонений от истинного рейтинга мэра, 50%. Для описания этой погрешности службы общественного мнения используют понятие «допустимый предел погрешности». Сообщая средствам массовой информации, что предел погрешности опроса составляет ±5%, они имеют в виду, что если повторить опрос много раз подряд, 19 из 20 раз (т. е. в 95% случаев) результат его будет в пределах 5% от истинного значения измеряемой переменной. (И хотя службы общественного мнения редко на это указывают, в 1 случае из 20 результат опроса будет мало соответствовать действительности.) На практике размеру выборки в 100 человек соответствует такой допустимый предел погрешности, который никуда не годится. А вот для выборки в 1000 человек предел погрешности обычно составляет около 3%, что уже вполне пригодно для большинства целей.
Однако, проводя опрос любого рода, важно сознавать, что при любом повторении опроса результат хоть немного, но изменится. Например, если в действительности 40% зарегистрированных избирателей дают положительную оценку деятельности президента, шесть независимых опросов скорее покажут что-то вроде 37%, 39%, 39%, 40%, 42% и 42%, нежели сойдутся на показателе в 40%. (Эти шесть чисел — действительные результаты шести независимых опросов, призванных выявить количество граждан, которые положительно оценивали деятельность президента в первые две недели сентября 2006 года {145} 145 Polling Report, «President Bush-Overall Job Rating», http://pollingreport.com/BushJob.htm .
.) Вот почему на практике на изменчивость данных в рамках допустимого предела погрешности не следует обращать внимания. Но даже если «Нью-Йорк Таймс» никогда и не вынесет на первую страницу заголовок «Количество рабочих мест и уровень заработной платы к двум часам пополудни несколько выросли», в публикациях, посвященных политическим опросам, подобного рода заголовки — не редкость. Например, после Национального партийного съезда республиканцев в 2004 г. «Си-эн-эн» разродилась выпуском новостей, озаглавленным так: «Похоже, рейтинг Буша несколько вырос» {146} 146 «Poll: Bush Apparently Gets Modest Bounce», CNN, September 8, 2004; http://www.cnn.com/2004/ALLPOLITICS/09/06/presidential.poll/index.html .
. Эксперты «Си-эн-эн» пояснили, что «в результате проведения съезда рейтинг Буша увеличился на 2%… Если до съезда в его пользу склонялись 50% потенциальных избирателей, то сразу после съезда — 52%». Лишь позднее репортер оговорил, что предел погрешности для данного опроса составлял 3,5%, а это означает, что экстренный выпуск новостей по сути не имел смысла. Похоже, слово «похоже» на самом деле означало «непохоже».
Интервал:
Закладка:
Похожие книги на «(Не)совершенная случайность. Как случай управляет нашей жизнью»
Представляем Вашему вниманию похожие книги на «(Не)совершенная случайность. Как случай управляет нашей жизнью» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.












Обсуждение, отзывы о книге «(Не)совершенная случайность. Как случай управляет нашей жизнью» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.