Рауль Ибаньес - Мир математики - т.6 Четвертое измерение. Является ли наш мир тенью другой Вселенной?
Здесь есть возможность читать онлайн «Рауль Ибаньес - Мир математики - т.6 Четвертое измерение. Является ли наш мир тенью другой Вселенной?» весь текст электронной книги совершенно бесплатно (целиком полную версию без сокращений). В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Город: Москва, Год выпуска: 2014, ISBN: 2014, Издательство: «Де Агостини», Жанр: Математика, на русском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.

- Название:Мир математики: т.6 Четвертое измерение. Является ли наш мир тенью другой Вселенной?
- Автор:
- Издательство:«Де Агостини»
- Жанр:
- Год:2014
- Город:Москва
- ISBN:978-5-9774-0631-4
- Рейтинг книги:5 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
Мир математики: т.6 Четвертое измерение. Является ли наш мир тенью другой Вселенной?: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «Мир математики: т.6 Четвертое измерение. Является ли наш мир тенью другой Вселенной?»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
Мир математики: т.6 Четвертое измерение. Является ли наш мир тенью другой Вселенной? — читать онлайн бесплатно полную книгу (весь текст) целиком
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «Мир математики: т.6 Четвертое измерение. Является ли наш мир тенью другой Вселенной?», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
Пример кода, который помогает обнаружить ошибки, — это испанский налоговый идентификационный номер, содержащий дополнительную букву, которая генерируется с помощью математической формулы. Таким образом, если хотя бы одна цифра номера будет неверной, то буква будет отличаться от нужной, что и поможет выявить ошибку.
Самокорректирующийся код американского инженера Ричарда Уэсли Хэмминга устроен так: к каждому шестнадцатеричному слову с помощью математического алгоритма добавляются еще три бита (например, слово ООП превратится в 0011101). К тому же, этот код способен исправить ошибку в одном из битов слова.
Код Хэмминга очень прост, но существуют и другие, гораздо более сложные коды обнаружения и исправления ошибок. Например, код Рида — Соломона, который используется в компакт-дисках и в телеметрии с гражданских спутников, где применяются 65- и 265-битовые слова соответственно, то есть каждое слово представляет собой точку в координатном пространстве с 65 и 265 измерениями. Таким образом, использование математического аппарата в координатном пространстве оказывается очень полезным, особенно при создании кодов для обнаружения и исправления ошибок.
Поисковая система Google
В настоящее время поисковая система Google стала одним из основных инструментов поиска в интернете, и у нее огромное количество пользователей. Одной из причин такого успеха является ее эффективность, так как для каждого поискового запроса система быстро выдает упорядоченный список результатов, и первые из них, как правило, содержат то, что мы ищем. Способ упорядочивания результатов поиска, то есть присвоения числового рейтинга каждой странице, использует сложную математику — смесь линейной алгебры, теории графов и теории вероятностей.
При разработке поисковых систем, подобных системе Google, приходится решать и математические, и технические задачи. Другими словами, главный вопрос заключается в том, как упорядочить результаты поиска. Можно предположить, что рейтинг определенной веб-страницы зависит от количества других страниц, ссылающихся на нее. Однако существуют страницы, на которые мало ссылок, но которые очень важны для данного поиска. Поэтому такая модель невыгодна для пользователей. К тому же она может быть легко использована веб-сайтами для искусственного повышения рейтинга.
Создатели Google Сергей Брин и Ларри Пейдж разработали алгоритм для определения рейтинга страницы не по количеству ссылок на нее, а пропорционально важности этой страницы для данного поиска. Этот алгоритм требует решения системы алгебраических уравнений. Фактически задача сводится к линейной алгебре, а именно к вычислению собственных векторов и собственных значений некой матрицы. Если обозначить важность веб-страниц в интернете набором чисел ( x 1, …., x n), где n — число страниц, существующих в интернете, а х i — число, означающее важность конкретной веб-страницы i, то задача сводится к поиску в n-мерном пространстве элемента ( x 1, …., x n), который является решением некой системы уравнений.
В 2006 г. было подсчитано, что в интернете существует около 600 миллиардов веб-страниц. Это число и соответствует числу измерений рассматриваемого пространства. Такое пространство, безусловно, является многомерным!
* * *
АЛГОРИТМ, КОТОРЫЙ ИЗМЕНИЛ ИНТЕРНЕТ
В 1998 г. два молодых студента-информатика Стэнфордского университета в Калифорнии Ларри Пейдж и Сергей Брин заканчивали исследовательский проекте несколько загадочным названием «Анатомия системы крупномасштабного гипертекстного интернет-поиска». Он содержал первую версию простого и элегантного алгоритма PageRank, используемого для упорядочивания списка
страниц в зависимости от их значимости. PageRank стал основой поисковой системы Google, которая через несколько лет обошла Yahoo, Altavista и многие другие поисковые системы. Поиск в Google даже стал синонимом поиска в интернете (слово «гуглить»» еще не вошло в словари, но активно употребляется в разговорной речи).
Алгоритм PageRank действительно элегантен и прост и может быть записан следующим образом:
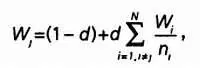
где W j — рейтинг страницы j; W i — рейтинг страницы i, которая содержит ссылку на страницу j; число d— коэффициент затухания со значением между 0 и 1, необходимый для сходимости рядов; n i, — число ссылок на странице W i, на другие страницы; N — общее количество страниц, которые содержат ссылку на страницу j.
Читать дальшеИнтервал:
Закладка:
Похожие книги на «Мир математики: т.6 Четвертое измерение. Является ли наш мир тенью другой Вселенной?»
Представляем Вашему вниманию похожие книги на «Мир математики: т.6 Четвертое измерение. Является ли наш мир тенью другой Вселенной?» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.









Обсуждение, отзывы о книге «Мир математики: т.6 Четвертое измерение. Является ли наш мир тенью другой Вселенной?» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.