Феликс Филатов - Клеймо создателя
Здесь есть возможность читать онлайн «Феликс Филатов - Клеймо создателя» — ознакомительный отрывок электронной книги совершенно бесплатно, а после прочтения отрывка купить полную версию. В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. ISBN: , Издательство: Array Литагент «Ридеро», Жанр: Биология, Прочая научная литература, на русском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.

- Название:Клеймо создателя
- Автор:
- Издательство:Array Литагент «Ридеро»
- Жанр:
- Год:неизвестен
- ISBN:978-5-4474-2574-6
- Рейтинг книги:4.67 / 5. Голосов: 3
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
Клеймо создателя: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «Клеймо создателя»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
Клеймо создателя — читать онлайн ознакомительный отрывок
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «Клеймо создателя», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
В представлениях Свансон и Босняцкого кодировка Грея образует последовательность наборов (3-компонентных наборов, то есть, триплетов из 4-х оснований), в которой два соседних набора отличаются только по одному основанию (в одной и той же позиции). В последовательности, организованной по этому правилу, различаются (хотя и не слишком строго) группы, соответствующие размерам аминокислот («большим» и «малым»), а также их позициям в составе белковых молекул («наружным» или «внутренним», то есть, гидрофильным или гидрофобным). Описанное свойство дает генетическому коду дополнительную защищенность. Стоит вспомнить, что – как об этом пишет Википедия – « коды Грея широко используются для упрощения выявления и исправления ошибок в системах связи, а также в формировании сигналов обратной связи в системах управления ». Они применяются и в теории генетических алгоритмов для кодирования генетических признаков, представленных целыми числами, поскольку минимизируют эффект ошибок при преобразовании аналоговых сигналов в цифровые .
Часть аминокислот обладает выраженными гидрофильными или гидрофобными свойствами. Молекулы синтезируемого полипептида сворачиваются в фиксированную трехмерную структуру. Основной параметр, определяющий это сворачивание (фолдинг) – гидрофобность или гидрофильность аминокислоты. Код очевидно не мог эволюционировать по размеру кодона; он с самого начала был триплетным, что определялось физикой комплементарных соответствий. Что до функций каждой буквы триплета, то поскольку в современном коде за гидрофобность аминокислоты отвечает центральный нуклеотид, постольку на начальных этапах эволюции кодирования направление считывания кодона, по-видимому, не имело большого значения. А общий паттерн генетического кода потребовал симметрий как условия помехоустойчивости хранения, передачи и приема информации, и соответствующие функции были делегированы краевым основаниям триплета. После установления вектора считывания кодона эти функции были, по преимуществу, отданы первым буквам, в то время, как половина третьих стала просто межкодонными разделителями, а вторая половина – дискриминаторами для продуктов с общим кодирующим дублетом. И в этом случае (то есть в случае вторых кодонных оснований) порядок CTAG выявляет билатеральную симметрию:
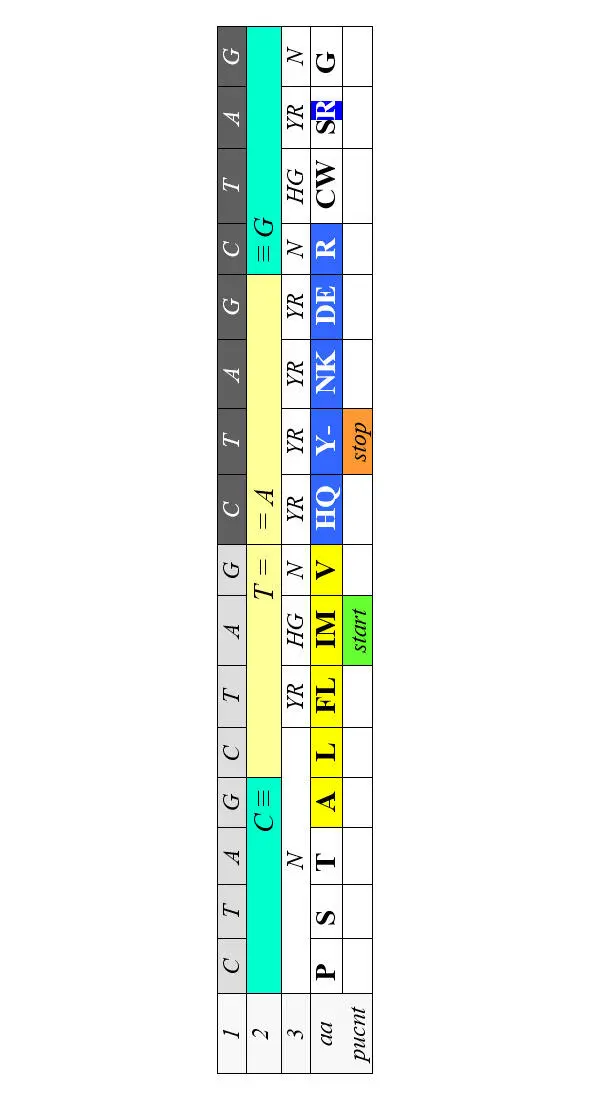
То обстоятельство, что позиции гидрофильных и гидрофобных аминокислот выходят за пределы «своей» центральной буквы в обе стороны от оси симметрии (между Т и А в этой таблице, еще раз подчеркивает значение порядка CTAG в организации генетического кода. Так же симметрично в Таблице 4 размещаются и некоторые другие продукты кодирования – например, пунктуационные знаки.
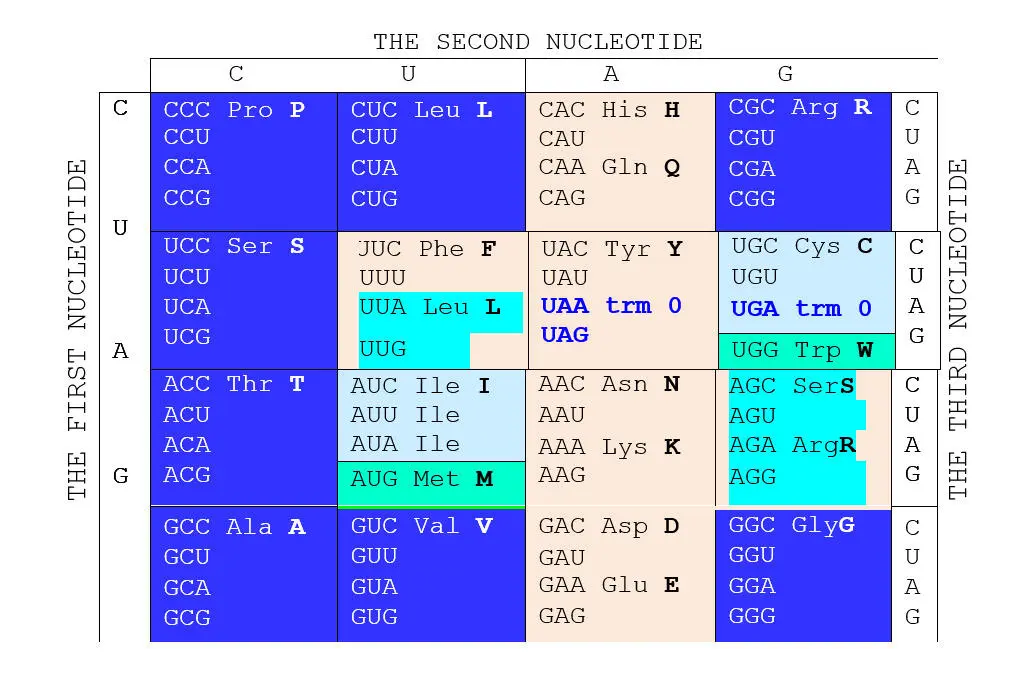
Вернемся, однако, к молекулярной массе как таковой. Автор использовал этот параметр не только для характеристики кодируемых продуктов, но также для характеристики кодирующих оснований. Упорядочивание азотистых оснований по нарастанию массы приводит к ряду C (или C , что в данном случае дела не меняет). Основания ряда симметричны относительно середины, которая делит его на две пары зеркально расположенных оснований CG и ТА (о чем мы уже говорили). Этот ряд не совпадает с рядами Крика и Румера, положенными в основу соответствующих таблиц кода, но Автор находит его намного более интересным и рациональным. Он мгновенно преобразует хорошо известную стандартную таблицу универсального генетического кода ( Глава G@C ), кочующую из учебника в учебник, в симметричную по группам вырожденности относительно оси, разделяющей первые кодирующие пиримидины и пурины (см. следующую страницу).
В новой таблице хорошо разделяются кодоны октетов 1 и 2; последние образуют светлую фигуру «креста», в которой, в свою очередь, хорошо заметно симметричное – относительно центра фигуры – расположение нечетных групп вырожденности и триплетов, дополняющих в октете 2 кодирование аминокислот S, Lи R, имеющих свои кодоны в октете 1.
Упорядочивание кодируемых аминокислот по массе неожиданно выявляет еще одну группу симметрий, которые связаны с классом аминоацил-тРНК-синтетаз (АРСаз), присоединяющих аминокислоту к тРНК. АРСазы делятся на два класса на основе структурного сходства и способу аминоацилирования тРНК. АРСазы 1-го класса (АРСазы-1) в большинстве случаев мономеры. 76-й аденозин тРНК они аминоацилируют по 2» -ОН группе. АРСазы-2 – это, как правило, димеры. За исключением фенилаланил-тРНК-синтетазы все они аминоацилируют 76-й аденозин тРНК по 3» -ОН группе. Оба класса АРСаз содержат равное число ферментов – по десять в каждом. Кроме того, АРСазы-1 узнают «свою» тРНК со стороны так называемого «малого желобка» акцепторной миниспирали, а АРСазы-2 – со стороны «большого».
Читать дальшеИнтервал:
Закладка:
Похожие книги на «Клеймо создателя»
Представляем Вашему вниманию похожие книги на «Клеймо создателя» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.









![Наталья Александрова - Клеймо сатаны [= Табакерка Робеспьера] [litres]](/books/404375/natalya-aleksandrova-klejmo-satany-tabakerka-ro-thumb.webp)

Обсуждение, отзывы о книге «Клеймо создателя» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.