Феликс Филатов - Клеймо создателя
Здесь есть возможность читать онлайн «Феликс Филатов - Клеймо создателя» — ознакомительный отрывок электронной книги совершенно бесплатно, а после прочтения отрывка купить полную версию. В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. ISBN: , Издательство: Array Литагент «Ридеро», Жанр: Биология, Прочая научная литература, на русском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.

- Название:Клеймо создателя
- Автор:
- Издательство:Array Литагент «Ридеро»
- Жанр:
- Год:неизвестен
- ISBN:978-5-4474-2574-6
- Рейтинг книги:4.67 / 5. Голосов: 3
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
Клеймо создателя: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «Клеймо создателя»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
Клеймо создателя — читать онлайн ознакомительный отрывок
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «Клеймо создателя», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
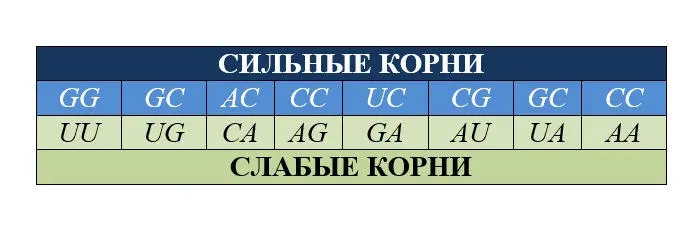
Идея о разбиении корней кодонов на два октета – «сильные» и «слабые» была совершенно новой и неожиданной для специалистов, работавших в этой области. Оказалось, что анализ многих свойств аминокислот четко подтверждает разбиение всех аминокислот на две группы, соответствующие разбиению корней на два октета. Исследованию разнообразных следствий этой идеи были посвящены несколько работ Румера. В частности, подход Румера к проблеме с однозначностью приводил к следующему порядку букв:
C – очень сильная
G – сильная
U – слабая
A – очень слабая
Этот порядок букв ( CGUA ) дает возможность сформулировать простые правила, определяющие « силу» корня :
сила корня , содержащего в качестве второй буквы С или А , определяется
силой второй буквы;
сила корня , содержащего в качестве второй буквы G или U , определяется силой первой буквы.
Крик предпочитал другой порядок букв в генетическом алфавите. В письме Румеру он доказывал преимущества порядка UCAG (этот порядок и сейчас используется во всех учебниках), но алфавит Румера позволял, в частности, видеть поразительные симметрии внутри генетического кода. Не вдаваясь в описание румеровской аргументации, мы предлагаем здесь свой порядок: CUAG , основанный не на качественном понятии « сила кодирующего основания », но на простом упорядочивании по нарастанию весьма простого же параметра – молекулярной массы азотистых оснований – и показываем группу наглядных симметрий, что – как и сам принцип такого упорядочивания – представляется нам даже более интересным. Но об этом позже. Что же до Юрия Борисовича Румера, то это фигура чрезвычайно интересная; о нѐм очень много можно прочесть в Интеренете:
… Чутьѐ у Румера было поразительным. То, что увлекало его в молекулярной биологии [много] лет назад, сейчас является передним краем исследований. В последние годы наблюдается явный рост числа публикаций, в которых проблемы генетического кода анализируются с привлечением симметрий и методов теории групп. Предлагаются разные подходы, основанные на разных типах групп, включая квантовые. В основном этим занимаются физики, не слышавшие о работах Юрия Борисовича. Когда они знакомятся-таки с работами Румера, то поражаются их изяществу, глубине и тому, что идеи симметрии уже [много] лет назад играли центральную роль при подходе к проблемам генетического кода …
Любопытно, в частности, что Юрий Борисович инициировал исследования и по поиску корреляций между одномерной и трехмерной структурами белков. Их не удалось довести до конца по причине существенной неполноты экспериментальных данных, отсутствия хороших компьютеров, а в основном, по-видимому, из-за недостатка энтузиазма … у молодых участников проекта . И снова современное: Не люблю я точные науки, Точно сам не знаю, почему …
Он объединил кодоны, третья буква которых может быть любой из четырех, в один набор, а кодоны, не удовлетворяющие этому условию – в другой. Оба набора содержали равное число триплетов – по 32 каждый. При этом число кодирующих дублетов в обоих наборах составляло по восемь в каждом, поэтому наборы были названы октетами. Оба октета оказались связанными между собой простым преобразованием: T↔G, C↔A (ДНК-вариант):
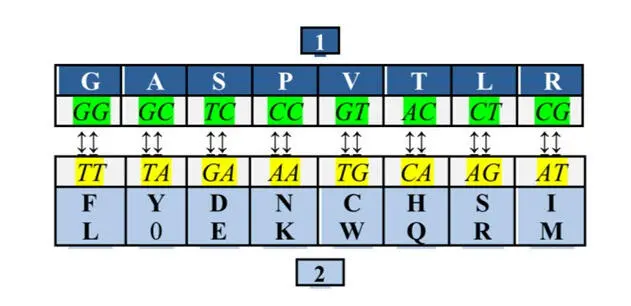
Этот рисунок иллюстрирует румеровское преобразование, переводящее дублеты одного октета в другой. Третье основание кодона неявно присутствует здесь в составе октета II, продукты которого организованы в две строки: верхнюю кодируют триплеты с третьим пиримидином, нижнюю – с третьим пурином.
Идеи Юрия Румера были продолжены и развиты работами Владимира Щербака. Два румеровских октета Щербак преобразовал таким образом, чтобы выделить в них группы вырожденности, пронумеровав их справа налево, а продукты кодирования (аминокислоты) он упорядочил в каждой группе по нарастанию молекулярной массы слева направо; триплеты, соответствующие продуктам кодирования, он записал по вертикали сверху вниз. Тогда первые, вторые и третьи основания кодонов образовывали три строки в каждом кодоне. Вот что у него получилось (цифры под третьими основаниями – характеристики кодируемого продукта):
Читать дальшеИнтервал:
Закладка:
Похожие книги на «Клеймо создателя»
Представляем Вашему вниманию похожие книги на «Клеймо создателя» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.









![Наталья Александрова - Клеймо сатаны [= Табакерка Робеспьера] [litres]](/books/404375/natalya-aleksandrova-klejmo-satany-tabakerka-ro-thumb.webp)

Обсуждение, отзывы о книге «Клеймо создателя» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.