Владстон Феррейра Фило - Теоретический минимум по Computer Science [Все что нужно программисту и разработчику]
Здесь есть возможность читать онлайн «Владстон Феррейра Фило - Теоретический минимум по Computer Science [Все что нужно программисту и разработчику]» — ознакомительный отрывок электронной книги совершенно бесплатно, а после прочтения отрывка купить полную версию. В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Город: СПб., Год выпуска: 2018, ISBN: 2018, Издательство: Питер, Жанр: Программирование, Прочая околокомпьтерная литература, на русском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.
![Владстон Феррейра Фило Теоретический минимум по Computer Science [Все что нужно программисту и разработчику] обложка книги](/books/389524/vladston-ferrejra-filo-teoreticheskij-minimum-po-co.webp)
- Название:Теоретический минимум по Computer Science [Все что нужно программисту и разработчику]
- Автор:
- Издательство:Питер
- Жанр:
- Год:2018
- Город:СПб.
- ISBN:978-5-4461-0587-8
- Рейтинг книги:4 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
Теоретический минимум по Computer Science [Все что нужно программисту и разработчику]: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «Теоретический минимум по Computer Science [Все что нужно программисту и разработчику]»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
Владстон Феррейра Фило знакомит нас с вычислительным мышлением, позволяющим решать любые сложные задачи. Научиться писать код просто — пара недель на курсах, и вы «программист», но чтобы стать профи, который будет востребован всегда и везде, нужны фундаментальные знания. Здесь вы найдете только самую важную информацию, которая необходима каждому разработчику и программисту каждый день. cite
Владстон Феррейра Фило
Теоретический минимум по Computer Science [Все что нужно программисту и разработчику] — читать онлайн ознакомительный отрывок
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «Теоретический минимум по Computer Science [Все что нужно программисту и разработчику]», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
В документных хранилищах вообще нет таблиц и строк. Вместо них есть записи, называемые документами . Связанные между собой документы группируются в коллекцию .
Документы имеют поле первичного ключа, поэтому их можно связывать друг с другом. Но операции JOIN в документных хранилищах неэффективны. Иногда они даже невозможны, в этом случае вам придется следить за связями между документами самостоятельно. И то и другое плохо — если документы имеют общие данные, их приходится дублировать.
Как и реляционные базы данных, базы данных NoSQL создают индексы для полей с первичным ключом. Также можно определять дополнительные индексы для полей, которые часто запрашиваются или сортируются.
Хранилища «ключ — значение»
Хранилище «ключ — значение» — это простейшая форма организованного хранения данных. В основном используется для кэширования. Например, когда некто запрашивает определенную веб-страницу на сервере, тот должен выбрать соответствующие ей данные из БД и использовать их для конструирования HTML-разметки, которую увидит пользователь. В сайтах с высокой посещаемостью, где случаются тысячи параллельных доступов, делать это становится невозможным.
Для решения проблемы мы используем хранилище «ключ — значение» как механизм кэширования. Ключом является требуемый URL-адрес, значением — HTML-разметка соответствующей веб-страницы. В следующий раз, когда кто-то запросит тот же URL-адрес, готовый код HTML просто будет извлечен из хранилища «ключ — значение» через ключ-адрес.
Если вам приходится раз за разом выполнять медленную операцию, всегда приводящую к одному и тому же результату, рассмотрите возможность его кэширования. Вам не обязательно использовать хранилище «ключ — значение», кэш может содержаться и в базах данных другого типа. Однако когда кэш запрашивается очень часто, система хранилищ данных типа «ключ — значение» — наилучший вариант.
Графовые базы данных
В графовой базе данных записи хранятся в виде вершин, а связи — в виде ребер. Вершины не привязаны к фиксированной схеме и могут содержать данные в разном формате. Графовая структура делает эффективной работу с записями в соответствии с их связями. Вот как информация из рис. 6.6 будет выглядеть в форме графа:
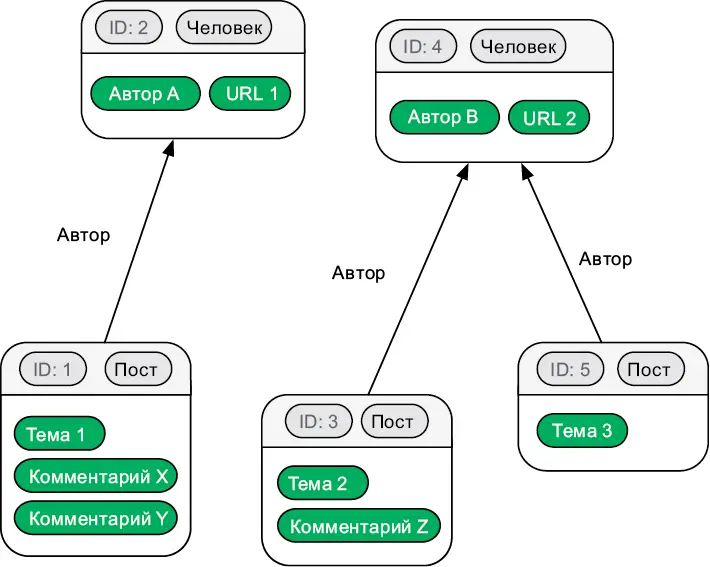
Рис. 6.7.Информация блога, хранящаяся в графовой базе данных
Это самый гибкий тип баз данных. Избавившись от таблиц и коллекций, вы можете хранить сетевые данные интуитивно понятным способом. Если бы вы решили нарисовать станции метро и остановки наземного общественного транспорта на доске, вы не стали бы изображать их в табличной форме. Вы бы использовали круги, прямоугольники и стрелки. Графовые БД позволяют хранить информацию именно таким образом.
Если ваши данные похожи на сеть, подумайте об использовании графовой базы данных. Этот тип БД особенно полезен, когда между компонентами данных много важных связей. Графовые базы данных также позволяют выполнять различные типы граф-ориентированных запросов. Например, если вы храните данные об общественном транспорте в графе, можете прямо запросить лучший маршрут между двумя остановками в одну сторону или туда и обратно.
Большие данные
Популярный в последнее время термин «большие данные» (big data) описывает ситуации обработки данных, которые чрезвычайно сложны с точки зрения объема, скорости или разнообразия [62] В профессиональных кругах это называется «три V»: volume (объем), velocity (скорость) и variety (разнообразие). Некоторые добавляют еще два аспекта: variability (переменчивость) и veracity (достоверность), превращая термин в «пять V».
. «Объем» больших данных — это, например, обработка тысяч терабайт информации в случае с БАК [63] Большой адронный коллайдер, или БАК, — это самый большой ускоритель частиц в мире. Во время эксперимента его датчики генерируют 1000 терабайт данных в секунду.
. «Скорость» применительно к большим данным означает, что вы должны сохранять миллион записей в секунду без задержек или быстро выполнять миллиарды запросов на чтение. «Разнообразие» означает, что данные не имеют строгой структуры, и потому становится очень трудно с ними справляться, используя традиционные реляционные базы данных.
Каждый раз, когда вам требуется искать нестандартный подход к управлению данными по причине их объема, скорости или разнообразия, вы можете смело сказать, что имеете дело с большими данными. Для выполнения некоторых современных научных экспериментов (к примеру, связанных с БАК или SKA [64] Антенная решетка площадью в квадратный километр, или SKA (от англ. Square Kilometer Array), — это группа телескопов, которые планируется ввести в строй в 2020 году. Они будут генерировать 1 млн терабайт данных каждый день.
) специалисты уже проводят исследования в области мегаданных , предполагающей хранение и анализ миллионов терабайт информации.
Интервал:
Закладка:
Похожие книги на «Теоретический минимум по Computer Science [Все что нужно программисту и разработчику]»
Представляем Вашему вниманию похожие книги на «Теоретический минимум по Computer Science [Все что нужно программисту и разработчику]» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.











Обсуждение, отзывы о книге «Теоретический минимум по Computer Science [Все что нужно программисту и разработчику]» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.